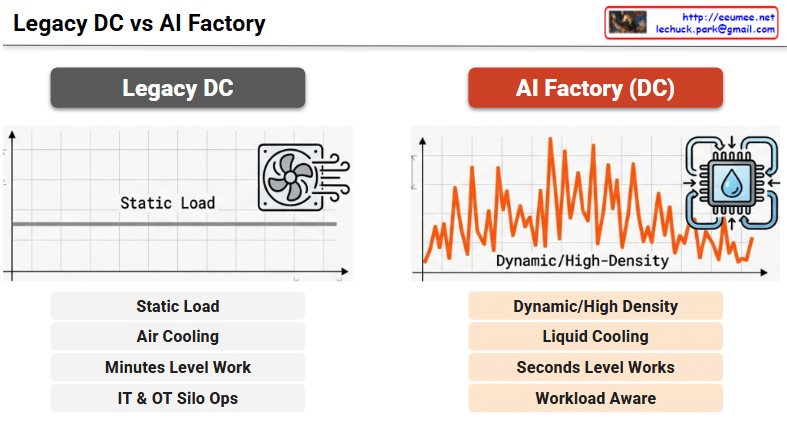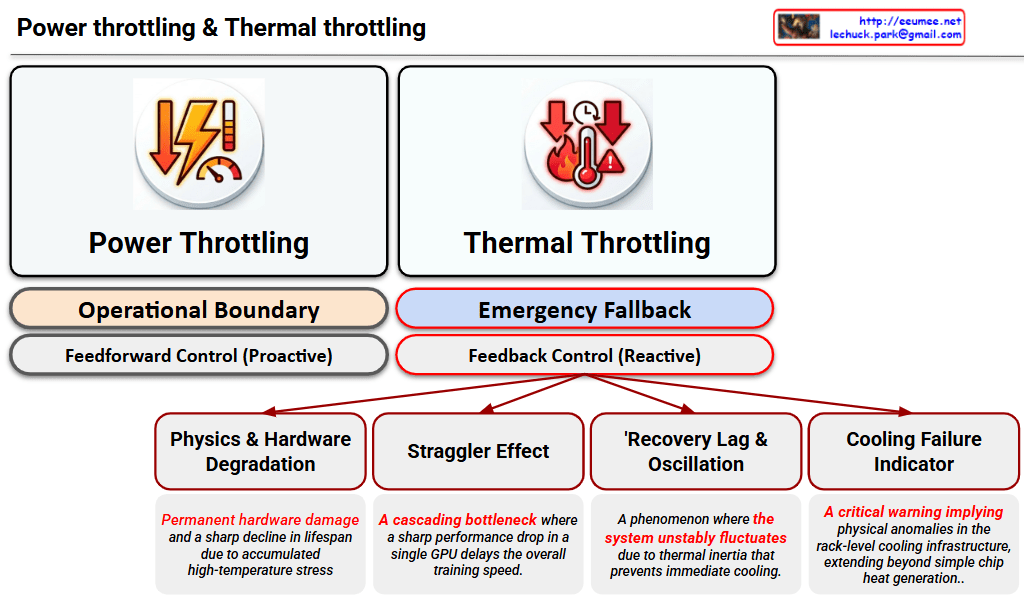
This image is a Visual Engineering diagram that contrasts the fundamental control mechanisms of Power Throttling and Thermal Throttling at a glance, specifically highlighting the critical impact thermal throttling has on the system.
1. Philosophical and Structural Contrast (Top Section)
The diagram places the two throttling methods side-by-side, clearly distinguishing them not just as similar performance limiters, but as mechanisms with completely different operational philosophies.
- Left: Power Throttling
- Operational Boundary: Indicates that this acts as a safety line, keeping the system operating ‘normally’ within its designed power limits.
- Feedforward Control (Proactive): Specifies that this is a proactive control method that restricts input (power demand) before a negative result occurs, fundamentally preventing the issue from happening.
- Right: Thermal Throttling
- Emergency Fallback: Shows that this is not a normal operational state, but a ‘last line of defense’ triggered to prevent physical destruction.
- Feedback Control (Reactive): Emphasizes that this is a reactive control method that drops clock speeds only after detecting the result (high heat exceeding the safe threshold).
2. Four Fatal Risks of Thermal Throttling (Bottom Tree Structure)
The core strength of the diagram lies in placing the sub-tree structure exclusively under Thermal Throttling. This highlights that this phenomenon goes beyond a simple performance drop, breaking down its complex, detrimental impacts on the infrastructure into four key factors:
- Physics & Hardware Degradation: Refers to direct damage to semiconductors (silicon) and the shortening of their lifespan (MTBF) due to the accumulated stress of high heat.
- Straggler Effect: Points out the bottleneck phenomenon in environments like distributed AI training. A delay in a single, thermally throttled node drags down the synchronization and data processing speed of the entire cluster.
- Thermal Inertia & Thermal Oscillations: Describes the unstable fluctuation of system performance. Because heat does not dissipate instantly (thermal inertia), the system repeatedly drops and recovers clock speeds, causing the performance to oscillate.
- Cooling Failure Indicator: Acts as a severe alarm. It implies that the issue extends beyond a hot chip—it indicates that the facility’s infrastructure, such as the rack-level Direct Liquid Cooling (DLC) capacity, has reached its physical limit or experienced an anomaly.
Overall Summary:
The diagram logically and intuitively delivers a powerful core message: “Power Throttling is a normal, proactive control within predictable bounds, whereas Thermal Throttling is a severe, reactive warning at both the hardware and infrastructure levels after control is lost.” It is an excellent piece of work that elegantly structures complex system operations using concise text and layout.
#DataCenter #AIInfrastructure #GPUCooling #ThermalThrottling #PowerThrottling #HardwareEngineering #HighPerformanceComputing #LiquidCooling #SystemArchitecture