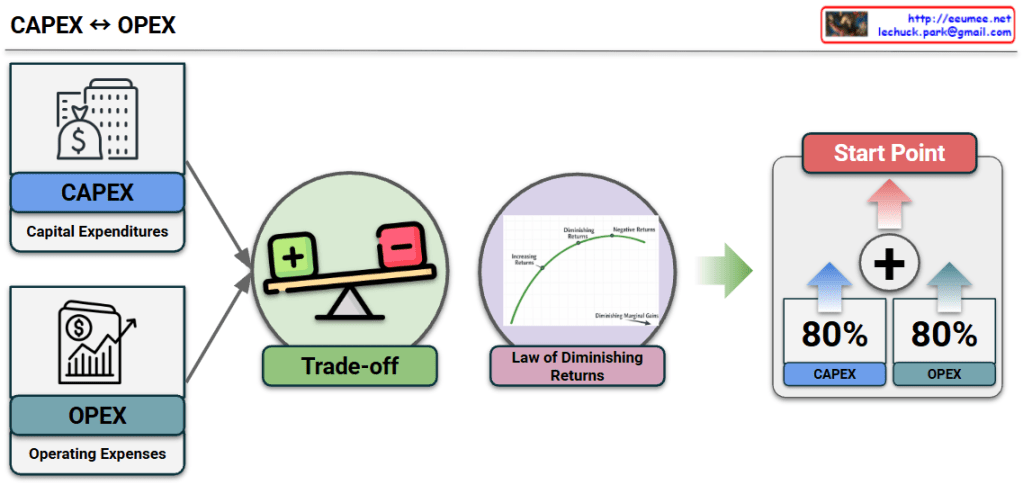
CAPEX (Capital Expenditures): Upfront investments for physical assets (e.g., hardware, infrastructure) to create future value.
OPEX (Operating Expenses): Ongoing costs required to run the day-to-day operations (e.g., maintenance, utilities, subscriptions).
2. The Economic Logic
Trade-off: There is a natural tension between the two; higher upfront investment (CAPEX) can lower future operating costs (OPEX), and vice versa.
Law of Diminishing Returns: This graph warns that striving for 100% perfection in optimization yields progressively smaller benefits relative to the effort and cost invested.
3. Strategic Conclusion: The 80% Rule
The infographic proposes a pragmatic “Start Point.”
Instead of delaying for perfection, it suggests that achieving 80% readiness in CAPEX and 80% efficiency in OPEX is the sweet spot. This balance allows for a timely launch without falling into the trap of diminishing returns.
Summary
While CAPEX and OPEX involve a necessary trade-off, striving for 100% optimization in both leads to diminishing returns.
Over-optimization drains resources and delays execution without proportional gains.
The most efficient strategy is to define the “Start Point” at 80% readiness for both, favoring speed and agility over perfection.
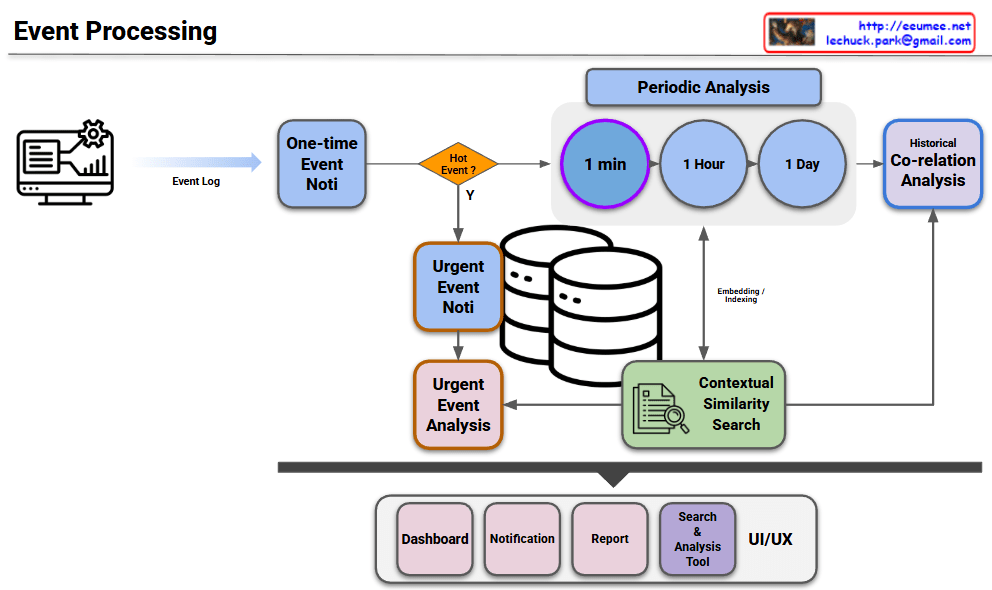
This diagram illustrates a workflow that handles system logs/events by dividing them into real-time urgent responses and periodic deep analysis.
1. Data Ingestion & Filtering
Event Log → One-time Event Noti: The process begins with incoming event logs triggering an initial, single-instance notification.
Hot Event Decision: A decision node determines if the event is critical (“Hot Event?”). This splits the workflow into two distinct paths: a Hot Path for emergencies and an Analytical Path for deeper insights.
2. Hot Path (Real-time Response)
Urgent Event Noti & Analysis: If identified as a “Hot Event,” the system immediately issues an urgent notification and performs an urgent analysis while persisting the data to the database. This path appears designed to minimize MTTD (Mean Time To Detect) for critical failures.
3. Periodic & Contextual Analysis (AIOps Layer)
This section indicates a shift from simple monitoring to intelligent AIOps.
Periodic Analysis: Events are aggregated and analyzed over fixed time windows (1 min, 1 Hour, 1 Day). The purple highlight on “1 min” suggests the current focus is on short-term trend analysis.
Contextual Similarity Search: This is a critical advanced feature. By explicitly mentioning “Embedding / Indexing,” the architecture suggests the use of Vector Search (likely via a Vector DB). It implies the system doesn’t just match keywords but understands the semantic context of an error to find similar past cases.
Historical Co-relation Analysis: This module synthesizes the periodic trends and similarity search results to correlate the current event with historical patterns, aiding in Root Cause Analysis (RCA).
4. User Interface (UI/UX)
The processed insights are delivered to the user through four channels:
Dashboard: High-level status visualization.
Notification: Alerts for urgent issues.
Report: Summarized periodic findings.
Search & Analysis Tool: A tool for granular log investigation.
Summary
Hybrid Architecture: Efficiently separates critical “Hot Event” handling (Real-time) from deep “Periodic Analysis” (Batch) to balance speed and insight.
Semantic Intelligence: Incorporates “Contextual Similarity Search” using Embeddings, enabling the system to identify issues based on meaning rather than just keywords.
Holistic Observability: interconnected modules (Urgent, Periodic, Historical) feed into a comprehensive UI/UX to support rapid decision-making and post-mortem analysis.
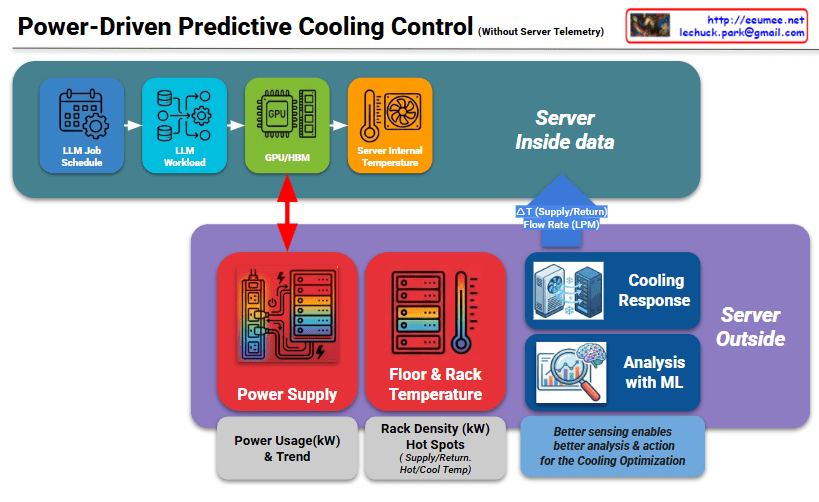
For a Co-location (Colo) service provider, the challenge is managing high-density AI workloads without having direct access to the customer’s proprietary server data or software stacks. This second image provides a specialized architecture designed to overcome this “data blindness” by using infrastructure-level metrics.
1. The Strategy: Managing the “Black Box”
In a co-location environment, the server internal data—such as LLM Job Schedules, GPU/HBM telemetry, and Internal Temperatures—is often restricted for security and privacy reasons. This creates a “Black Box” for the provider. The architecture shown here shifts the focus from the Server Inside to the Server Outside, where the provider has full control and visibility.
2. Power as the Primary Lead Indicator
Because the provider cannot see when an AI model starts training, they must rely on Power Supply telemetry as a proxy.
The Power-Heat Correlation: As indicated by the red arrow, there is a near-instantaneous correlation between GPU activity and power draw ($kW$).
Zero-Inference Monitoring: By monitoring Power Usage & Trends at the PDU (Power Distribution Unit) level, the provider can detect a workload spike the moment it happens, often several minutes before the heat actually migrates to the rack-level sensors.
3. Bridging the Gap with ML Analysis
Since the provider is missing the “More Proactive” software-level data, the Analysis with ML component becomes even more critical.
Predictive Modeling: The ML engine analyzes power trends to forecast the thermal discharge. It learns the specific “power signature” of AI workloads, allowing it to initiate a Cooling Response (adjusting Flow Rate in LPM and $\Delta T$) before the ambient temperature rises.
Optimization without Intrusion: This allows the provider to maintain a strict SLA (Service Level Agreement) and optimize PUE (Power Usage Effectiveness) without requiring the tenant to install agents or share sensitive job telemetry.
Comparison for Co-location Providers
Feature
Ideal Model (Image 1)
Practical Colo Model (Image 2)
Visibility
Full-stack (Software to Hardware)
Infrastructure-only (Power & Air/Liquid)
Primary Metric
LLM Job Queue / GPU Temp
Power Trend ($kW$) / Rack Density
Tenant Privacy
Low (Requires data sharing)
High (Non-intrusive)
Control Precision
Extremely High
High (Dependent on Power Sampling Rate)
Summary
For Co-location providers, this architecture solves the lack of server-side visibility by using Power Usage ($kW$) as a real-time proxy for heat generation.
By monitoring Power Trends at the infrastructure level, the system can predict thermal loads and trigger Cooling Responses before temperature sensors even react.
This ML-driven approach enables high-efficiency cooling and PUE optimization while respecting the strict data privacy and security boundaries of multi-tenant AI data centers.
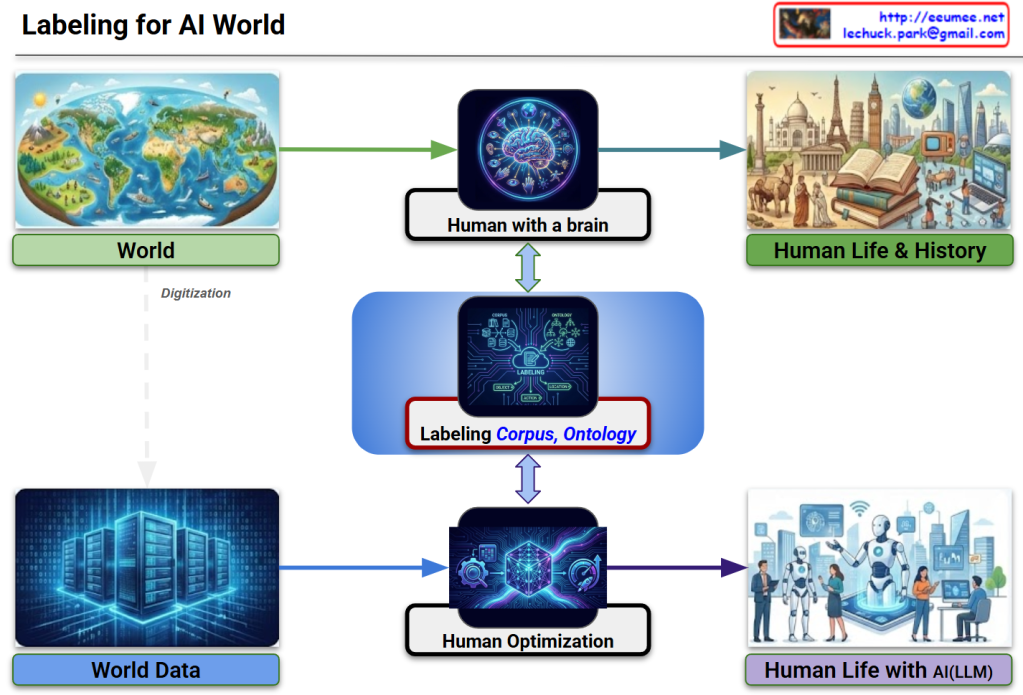
The image illustrates a logical framework titled “Labeling for AI World,” which maps how human cognitive processes are digitized and utilized to train Large Language Models (LLMs). It emphasizes the transition from natural human perception to optimized AI integration.
1. The Natural Cognition Path (Top)
This track represents the traditional human experience:
World to Human with a Brain: Humans sense the physical world through biological organs, which the brain then analyzes and processes into information.
Human Life & History: This cognitive processing results in the collective knowledge, culture, and documented history of humanity.
2. The Digital Optimization Path (Bottom)
This track represents the technical pipeline for AI development:
World Data: Through Digitization, the physical world is converted into raw data stored in environments like AI Data Centers.
Human Optimization: This raw data is refined through processes like RLHF (Reinforcement Learning from Human Feedback) or fine-tuning to align AI behavior with human intent.
Human Life with AI (LLM): The end goal is a lifestyle where humans and LLMs coexist, with the AI acting as a sophisticated partner in daily life.
3. The Central Bridge: Labeling (Corpus & Ontology)
The most critical element of the diagram is the central blue box, which acts as a bridge between human logic and machine processing:
Corpus: Large-scale structured text data necessary for training.
Ontology: The formal representation of categories, properties, and relationships between concepts that define the human “worldview.”
The Link: High-quality Labeling ensures that AI optimization is grounded in human-defined logic (Ontology) and comprehensive language data (Corpus), ensuring both Quality and Optimization.
Summary
The diagram demonstrates that Data Labeling, guided by Corpus and Ontology, is the essential mechanism that translates human cognition into the digital realm. It ensures that LLMs are not just processing raw numbers, but are optimized to understand the world through a human-centric logical framework.
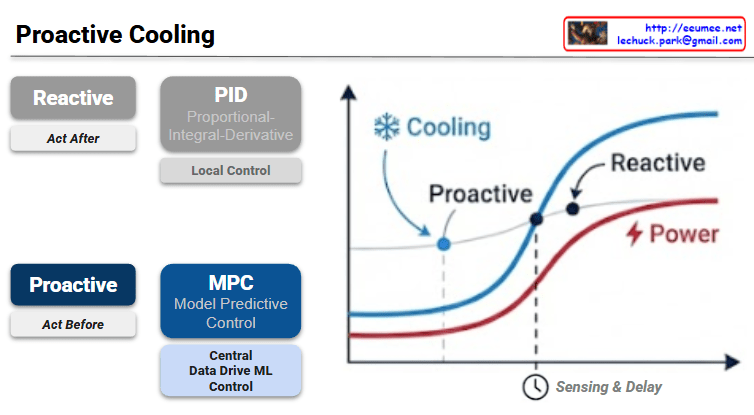
The provided image illustrates the fundamental shift in data center thermal management from traditional Reactive methods to AI-driven Proactive strategies.
1. Comparison of Control Strategies
The slide contrasts two distinct approaches to managing the cooling load in a high-density environment, such as an AI data center.
Feature
Reactive (Traditional)
Proactive (Advanced)
Philosophy
Act After: Responds to changes.
Act Before: Anticipates changes.
Mechanism
PID Control: Proportional-Integral-Derivative.
MPC: Model Predictive Control.
Scope
Local Control: Focuses on individual units/sensors.
Central ML Control: Data-driven, system-wide optimization.
Logic
Feedback-based (error correction).
Feedforward-based (predictive modeling).
2. Graph Analysis: The “Sensing & Delay” Factor
The graph on the right visualizes the efficiency gap between these two methods:
Power (Red Line): Represents the IT load or power consumption which generates heat.
Sensing & Delay: There is a temporal gap between when a server starts consuming power and when the cooling system’s sensors detect the temperature rise and physically ramp up the fans or chilled water flow.
Reactive Cooling (Dashed Blue Line): Because it “acts after,” the cooling response lags behind the power curve. This often results in thermal overshoot, where the hardware momentarily operates at higher temperatures than desired, potentially triggering throttling.
Proactive Cooling (Solid Blue Line): By using Model Predictive Control (MPC), the system predicts the impending power spike. It initiates cooling before the heat is fully sensed, aligning the cooling curve more closely with the power curve to maintain a steady temperature.
3. Technical Implications for AI Infrastructure
In modern data centers, especially those handling fluctuating AI workloads (like LLM training or high-concurrency inference), the “Sensing & Delay” in traditional PID systems can lead to significant energy waste and hardware stress. MPC leverages historical data and real-time telemetry to:
Reduce PUE (Power Usage Effectiveness): By avoiding over-cooling and sudden spikes in fan power.
Improve Reliability: By maintaining a constant thermal envelope, reducing mechanical stress on chips.
Optimize Operational Costs: Through centralized, intelligent resource allocation.
Summary
Proactive Cooling utilizes Model Predictive Control (MPC) and Machine Learning to anticipate heat loads before they occur.
Unlike traditional PID systems that respond to temperature errors, MPC eliminates the Sensing & Delay lag by acting on predicted power spikes.
This shift enables superior energy efficiency and thermal stability, which is critical for high-density AI data center operations.