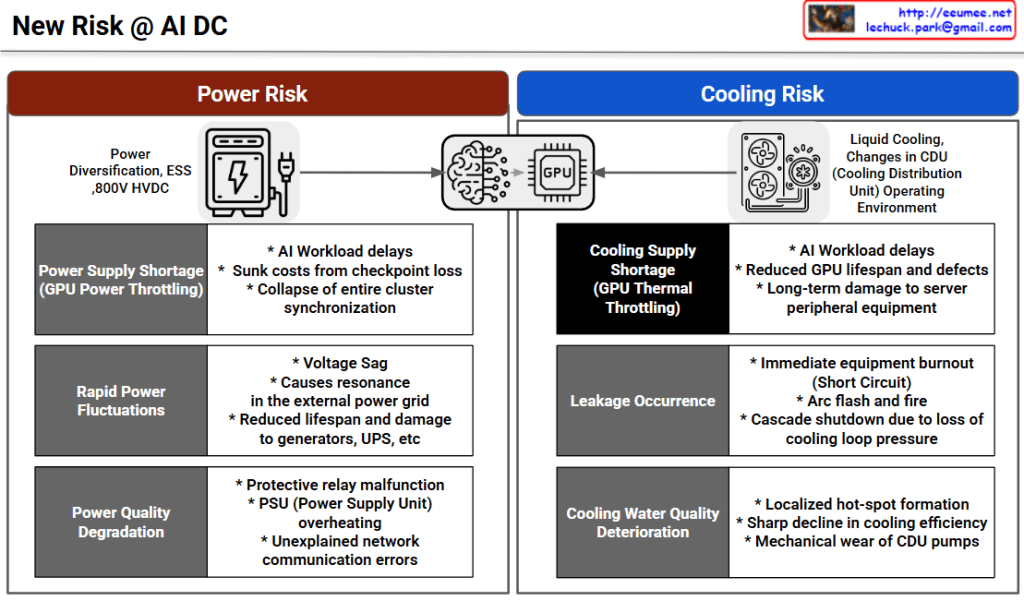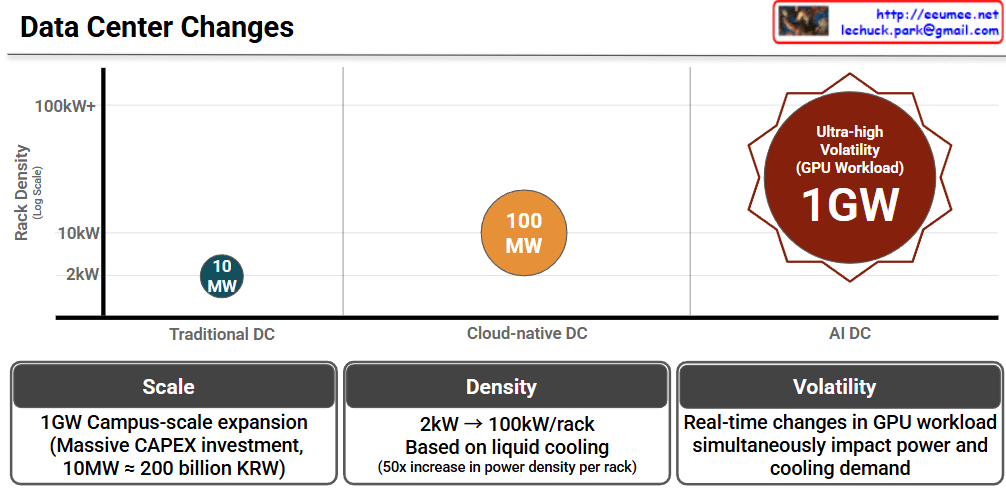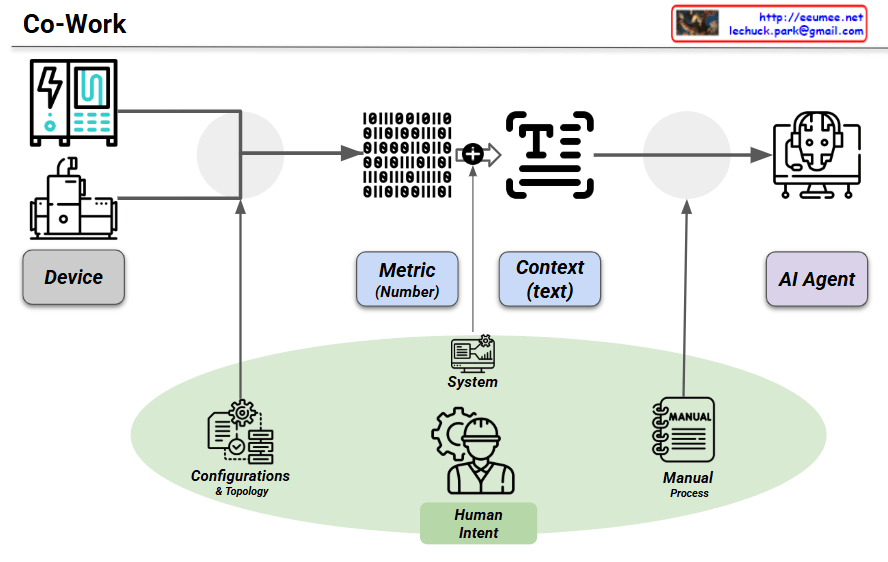
This image, titled “Co-Work,” illustrates a strategic framework for Event-Centric AIOps. It demonstrates how raw telemetry from physical infrastructure is transformed into structured, actionable intelligence for an AI Agent, fundamentally driven by human expertise.
1. Data Generation and Extraction
- Device to Metric: Physical infrastructure (Device) generates raw operational data.
- The Role of Configurations: This data is extracted into quantitative Metric (Number) formats. This extraction is guided by Configurations & Topology, which represents the structural configurations and network topology. This ensures the system understands the physical and logical layout of the devices.
2. Contextualization
- Metric to Context: Raw numerical data lacks operational meaning on its own. It is transformed into readable Context (text), effectively converting raw telemetry into event logs suitable for LLM-based analysis.
- The Role of System: This conversion is executed by the System, which acts as the Data Processing Operating System. It defines the rules and logic for how raw numbers are processed, correlated, and translated into meaningful operational states.
3. AI Agent Integration
- Context to AI Agent: The structured, contextualized text is delivered to the AI Agent for analysis, root cause identification, or predictive tasks.
- The Role of Manual: The AI Agent’s understanding is heavily enriched by the Manual, which encompasses text-based operating manuals, standard operating procedures (SOPs), and historical troubleshooting data. This provides the AI with established guidelines for how to interpret and react to specific scenarios.
4. The Foundation: Human Intent
The green foundational layer, Human Intent, is the most critical aspect of this architecture. Configurations, System, and Manual are the three core elements and systems that are actively built and managed by humans. They dictate the rules, structural layout, and historical knowledge that guide the AI. This ensures that the AI Agent does not operate in a vacuum, but rather functions safely and effectively within the strict boundaries of human operational intent.
Summary
The “Co-Work” architecture visualizes a collaborative AIOps framework where raw device metrics are systematically transformed into contextualized text. By leveraging three key human-managed components—Configurations (topology), Systems (data processing), and Manuals (historical/procedural text)—the architecture bridges the gap between physical hardware and AI. It ensures the AI Agent receives highly structured, context-rich event data to perform accurate and reliable infrastructure management.
#AIOps #EventCentricAIOps #AIDataCenter #HumanInTheLoop #Telemetry #LLM #ITOperations