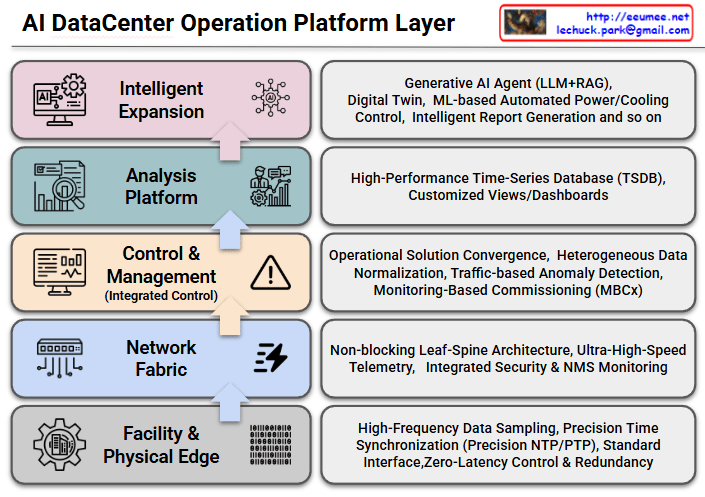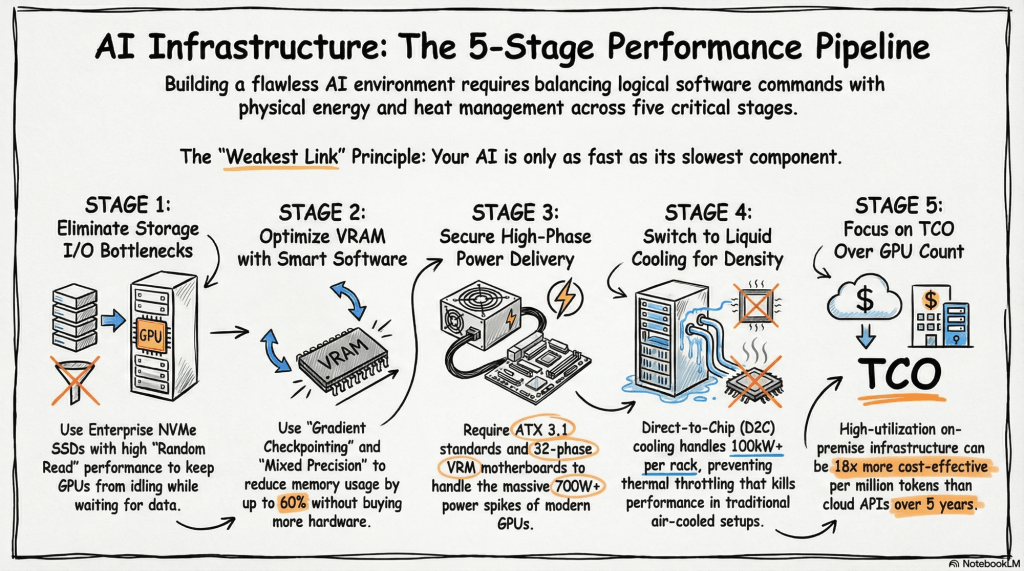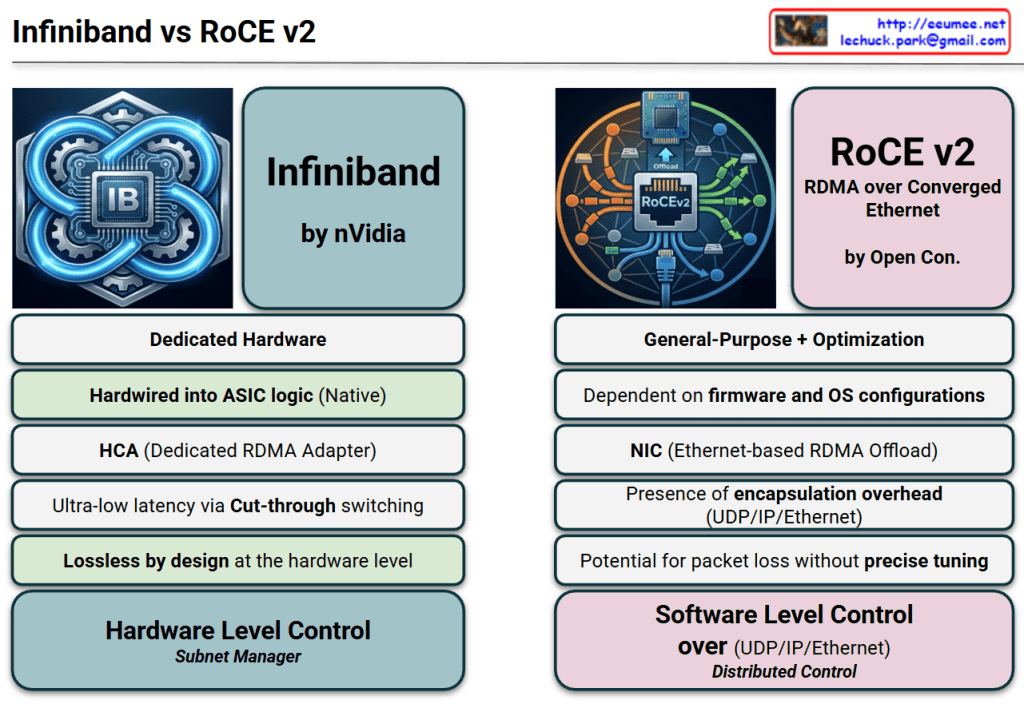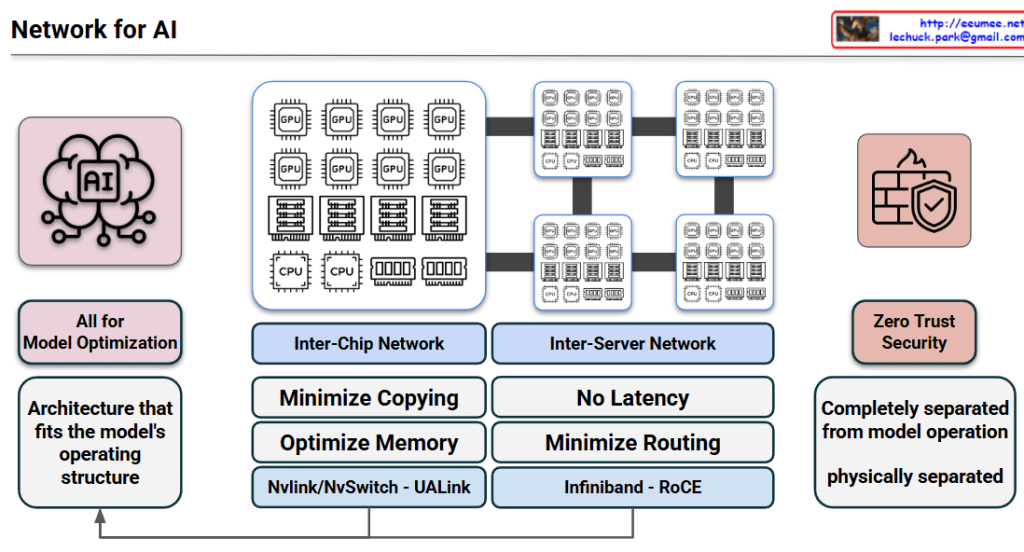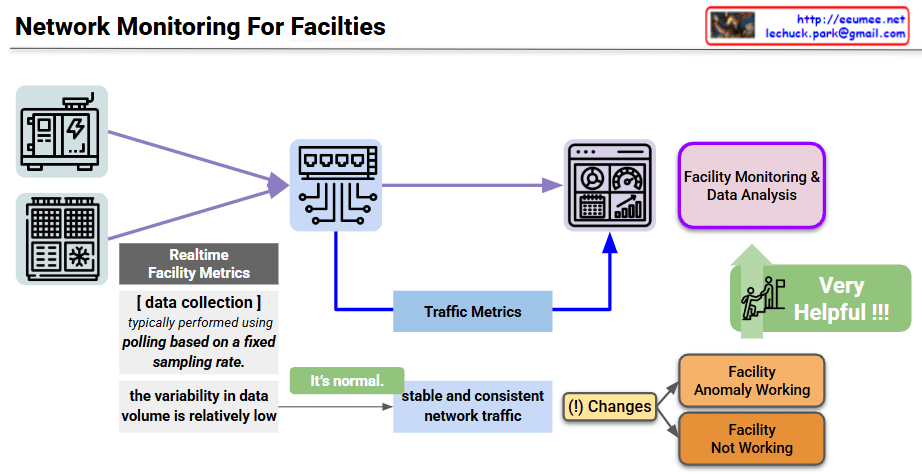
The provided image is a conceptual diagram illustrating how to monitor the status and detect anomalies in critical industrial facility infrastructure (such as power and cooling) through network traffic patterns. I also noticed the author’s information (Lechuck) in the top right corner! Let’s break down the main data flow and core ideas of your diagram step-by-step.
1. Realtime Facility Metrics
- Target: Physical facility equipment such as generators (power infrastructure) and HVAC/cooling units.
- Collection Method: A central monitoring server primarily uses a Polling method, requesting and receiving status data from the equipment based on a fixed sampling rate.
- Characteristics: Because a specific amount of data is exchanged at designated times, the variability in data volume during normal operation is relatively low.
2. Traffic Metrics (Inferring Status via Traffic Characteristics)
This section contains the core insight of the diagram. Beyond just analyzing the payload of the collected sensor data, the pattern of the network traffic itself is utilized as an indicator of the facility’s health.
- Normal State (It’s normal): When the equipment is operating normally, the network traffic occurs in a very stable and consistent manner in sync with the polling cycle.
- Detecting Traffic Changes ((!) Changes): If a change occurs in this expected stable traffic pattern (e.g., traffic spikes, response delays, or disconnections), it is flagged as an anomaly in the facility.
- Status Classification: Based on these abnormal traffic patterns, the system can infer whether the equipment is operating abnormally (Facility Anomaly Working) or has completely stopped functioning (Facility Not Working).
3. Facility Monitoring & Data Analysis
- This architecture combines standard dashboard monitoring with Traffic Metrics extracted from network switches, feeding them into the data analysis system.
- This cross-validation approach is highly effective for distinguishing between actual sensor data errors and network segment failures. As highlighted in the diagram, this ultimately improves the overall reliability of the facility monitoring system (Very Helpful !!!).
💡 Summary
This architecture presents a highly intuitive and efficient approach to data center and facility operations. By leveraging the network engineering characteristic that facility equipment communicates in regular patterns, it demonstrates an excellent monitoring logic. It allows operators to perform initial fault detection almost immediately simply by observing “changes in the consistency of network traffic,” even before conducting complex sensor data analysis.
#NetworkMonitoring #DataCenterOperations #FacilityManagement #TrafficAnalysis #AnomalyDetection #NetworkEngineering #ITInfrastructure #AIOps #SmartFacilities
With Gemini