The Evolution of Data Centers
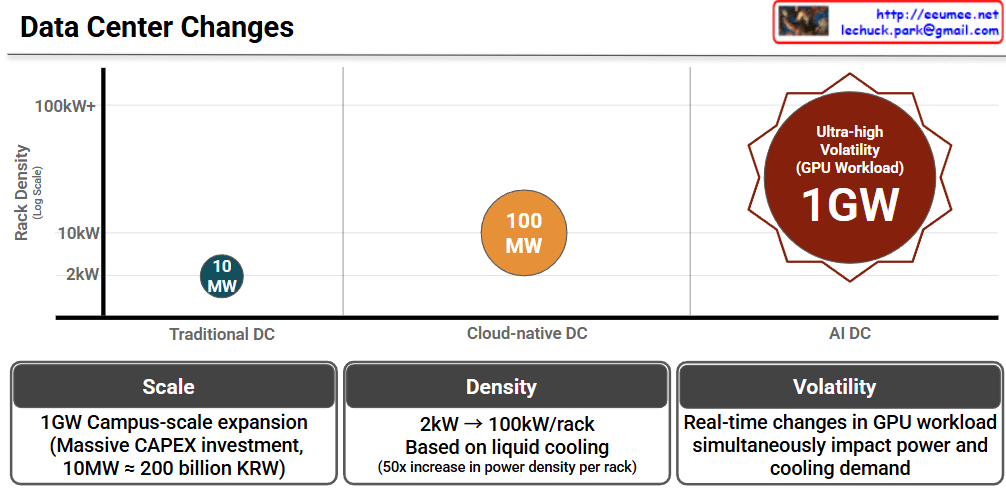
This infographic, titled “Data Center Changes,” visually explains how data center requirements are skyrocketing due to the shift from traditional computing to AI-driven workloads.
The chart compares three stages of data centers across two main metrics: Rack Density (how much power a single server rack consumes, shown on the vertical axis) and the overall Total Power Capacity (represented by the size and labels of the circles).
- Traditional DC (Data Center): In the past, data centers ran at a very low rack density of around 2kW. The total power capacity required for a facility was relatively small, at around 10 MW.
- Cloud-native DC: As cloud computing took over, the demands increased. Rack densities jumped to about 10kW, and the overall facility size grew to require around 100 MW of power.
- AI DC: This is where we see a massive leap. Driven by heavy GPU workloads, AI data centers push rack densities beyond 100kW+. The scale of these facilities is enormous, demanding up to 1GW of power. The red starburst shape also highlights a new challenge: “Ultra-high Volatility,” meaning the power draw isn’t stable; it spikes violently depending on what the AI is processing.
The Three Core Challenges (Bottom Panels)
The bottom three panels summarize the key takeaways of transitioning to AI Data Centers:
- Scale (Massive Investment): Building a 1GW “Campus-scale” AI data center requires astronomical capital expenditure (CAPEX). To put this into perspective, the chart notes that just 10MW costs roughly 200 billion KRW (South Korean Won). Scaling that to 1GW is a colossal financial undertaking.
- Density (The Need for Liquid Cooling): Power density per rack is jumping from 2kW to 100kW—a 50x increase. Traditional air-conditioning cannot cool servers running this hot, meaning the industry must transition to advanced liquid cooling technologies.
- Volatility (Unpredictable Demands): Unlike traditional servers that run at a steady hum, AI GPU workloads change in real-time. A sudden surge in computing tasks instantly spikes both the electricity needed to run the GPUs and the cooling power needed to keep them from melting.
Summary
- Data centers are undergoing a massive transformation from Traditional (10MW) and Cloud (100MW) models to gigantic AI Data Centers requiring up to 1 Gigawatt (1GW) of power.
- Because AI servers use powerful GPUs, power density per rack is increasing 50-fold (up to 100kW+), forcing a shift from traditional air cooling to advanced liquid cooling.
- This AI infrastructure requires staggering financial investments (CAPEX) and must be designed to handle extreme, real-time volatility in both power and cooling demands.
#DataCenter #AIDataCenter #LiquidCooling #GPU #CloudComputing #TechTrends #TechInfrastructure #CAPEX
With Gemini