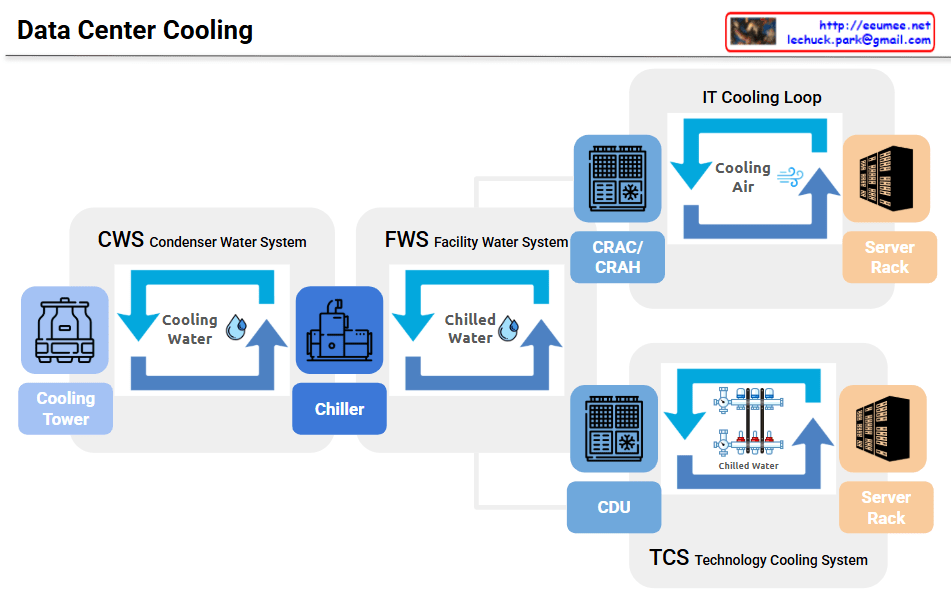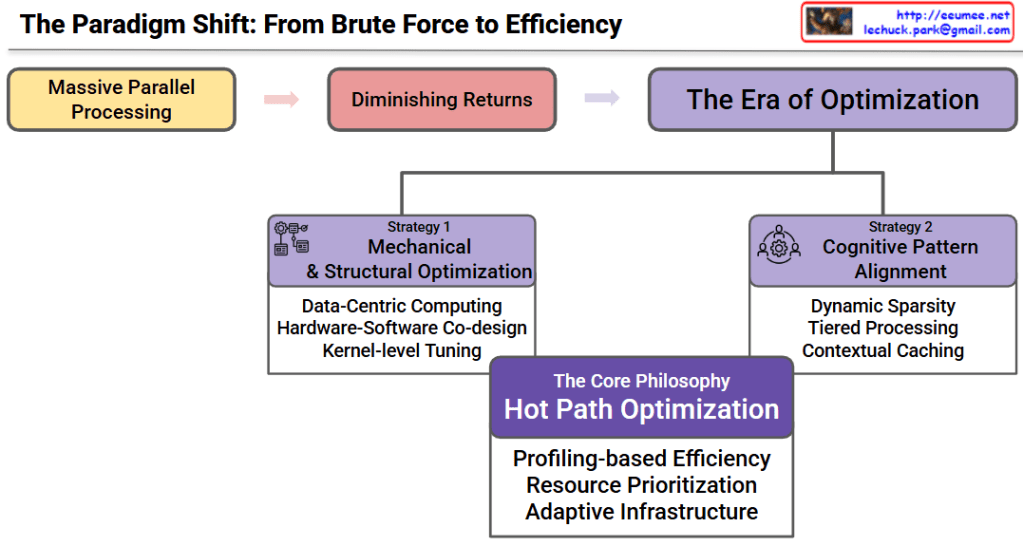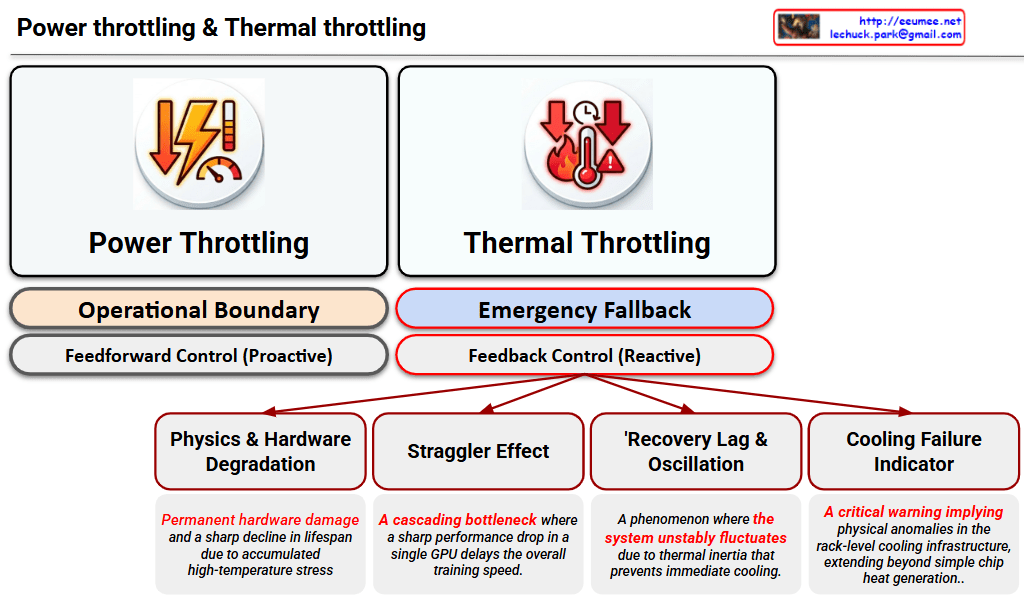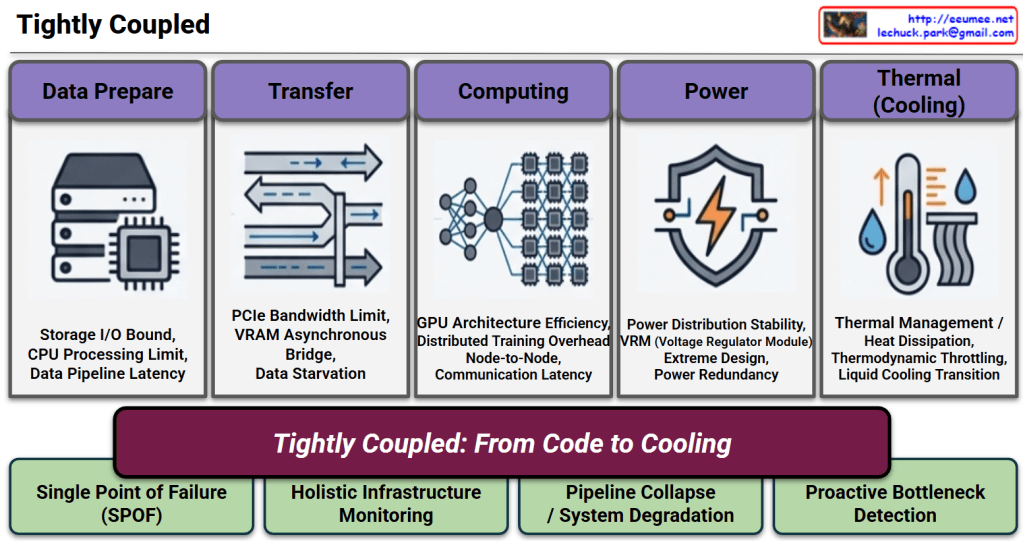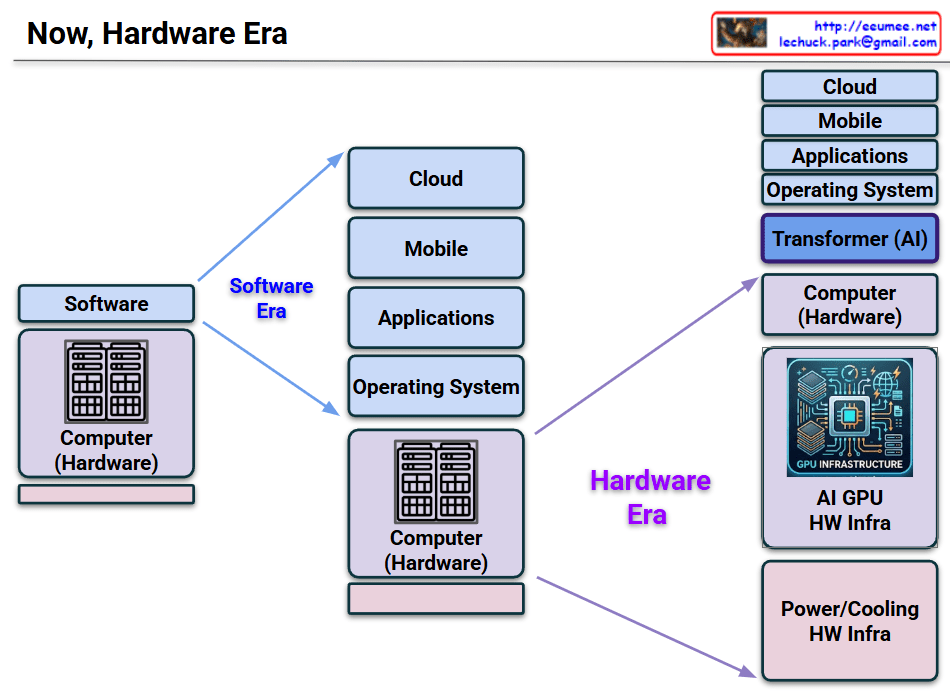
This image is an insightful architectural diagram illustrating the major paradigm shift in the IT industry, transitioning from the past “Software Era” to the current “Hardware Era.”
On the left side, representing the Software Era, the structure is heavily focused on software expansion. A single, traditional “Computer (Hardware)” block serves as a basic foundation to support a growing stack of software components: Operating System, Applications, Mobile, and Cloud. During this time, hardware was largely viewed as a standardized commodity to run software.
On the right side, representing the current Hardware Era, the diagram shows a significant architectural transformation driven by Artificial Intelligence.
Here are the key changes:
- The Insertion of AI: A new, prominent purple block labeled “Transformer (AI)” is inserted right beneath the traditional software stack. This signifies that AI models have become the core engine and an indispensable layer for modern IT services.
- Expansion of Hardware Infrastructure: To support the massive computational demands of the AI layer, the hardware section at the bottom has expanded dramatically into three distinct pillars:
- Computer (Hardware): The traditional CPU-based computing servers.
- AI GPU HW Infra: A large, specialized block featuring a detailed microchip icon. This highlights the absolute necessity of high-performance GPU clusters, high-bandwidth memory (HBM), and high-speed networking to process AI workloads.
- Power/Cooling HW Infra: This is perhaps the most critical new addition. It visually emphasizes that running massive AI GPU clusters requires enormous energy and generates immense heat. Consequently, power supply and advanced cooling systems are no longer just facility management issues, but a core component of the IT infrastructure itself.
The diagram visualizes how the advent of AI has shifted the industry’s bottleneck and focus back to building robust, highly specialized hardware and the physical power/cooling infrastructure required to sustain it.
#HardwareEra #AIInfrastructure #GPUComputing #DataCenter #TechTrends #ArtificialIntelligence #PowerAndCooling #ITArchitecture #FutureOfTech
With Gemini