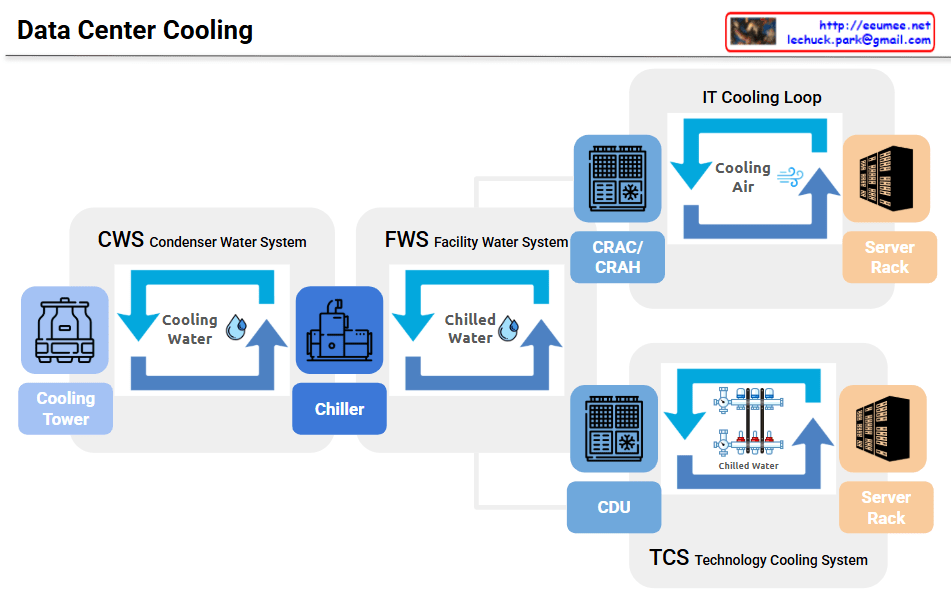
This diagram illustrates a hybrid Data Center Cooling Architecture, depicting how a facility manages thermal loads by combining traditional air cooling with advanced liquid cooling. The system is designed to support both standard infrastructure and high-density compute environments (such as AI clusters) simultaneously.
1. Facility-Level Thermal Management (Primary Infrastructure)
The left and center sections of the diagram represent the foundational facility water loops that capture and reject heat from the entire data center.
- CWS (Condenser Water System): This is the heat rejection loop on the far left. Cooling Water circulates between the Chiller and the external Cooling Tower. The heat absorbed by the chiller from the facility’s interior is transferred to this loop and evaporated into the atmosphere via the cooling tower.
- Chiller: Acts as the central refrigeration unit. It sits between the CWS and FWS, performing the critical energy transfer that cools the facility’s internal water supply.
- FWS (Facility Water System): This is the internal primary loop. It circulates Chilled Water produced by the chiller throughout the building. As shown by the split branching lines on the right, this single FWS loop serves as the shared cold utility source for both cooling methodologies.
2. Dual-Path IT Heat Dissipation (Secondary Loops)
The FWS branches into two distinct pathways to accommodate different server densities and infrastructure types:
A. Air Cooling Pathway (Top Right)
- Components: CRAC/CRAH (Computer Room Air Conditioner / Computer Room Air Handling unit) & IT Cooling Loop.
- Mechanism: Chilled water from the FWS flows into the CRAC/CRAH units. Fans blow air over the chilled coils, generating Cooling Air. This cold air is forced through the data hall into the Server Rack to dissipate heat via convection.
- Application: Ideal for traditional, low-to-medium density workloads.
B. Liquid Cooling Pathway (Bottom Right)
- Components: CDU (Coolant Distribution Unit) & TCS (Technology Cooling System).
- Mechanism: Chilled water from the FWS enters the CDU, which contains an internal heat exchanger. Rather than mixing the waters, the CDU uses the facility’s chilled water to cool a isolated, highly-purified secondary loop (TCS). The TCS then pumps this Chilled Water/Coolant directly through specialized manifolds and fluid conduits into the liquid-cooled Server Rack (e.g., via direct-to-chip cold plates).
- Application: Critical for high-density deployments, such as GPU-accelerated AI servers, where air cooling alone is insufficient.
Summary
The diagram demonstrates a highly efficient, modern Hybrid Data Center Cooling Architecture. By leveraging a centralized primary chilling system (CWS & FWS), the facility successfully bifurcates its cooling delivery: utilizing traditional air cooling (CRAC/CRAH) for standard infrastructure while concurrently deploying precise, high-efficiency liquid cooling (CDU & TCS) to sustain high-density AI server racks.
#DataCenter #AIInfrastructure #LiquidCooling #TCS #CDU #ChilledWaterSystem #AIDC #MechanicalEngineering #ThermalManagement