DC Data Service Model Overview
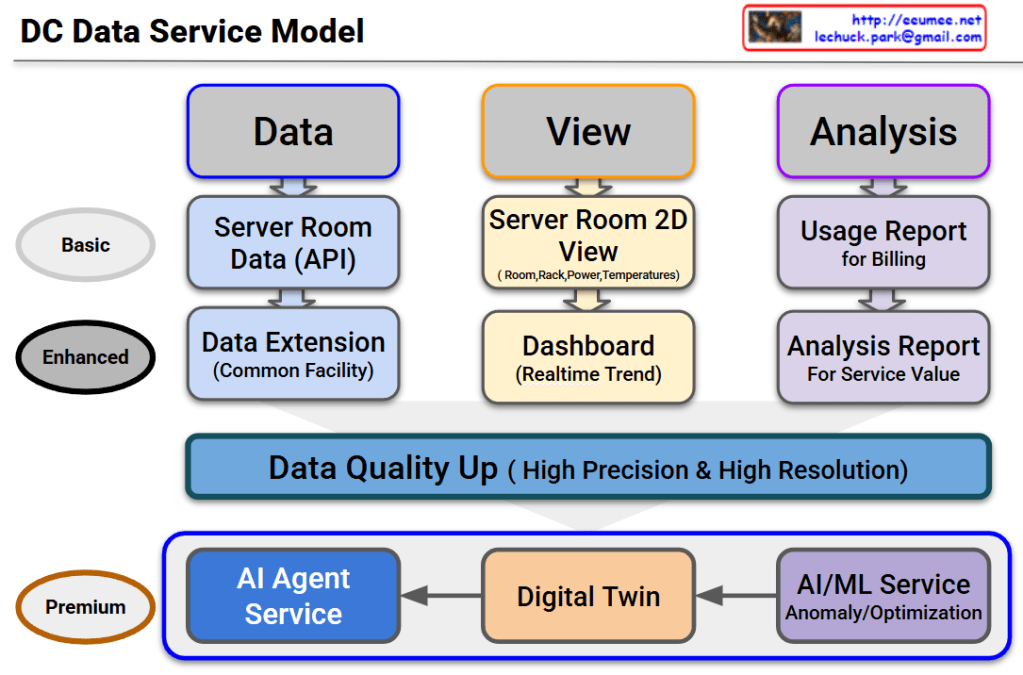
This diagram outlines the evolutionary roadmap of a Data Center (DC) Data Service Model. It illustrates how data center operations advance from basic monitoring to a highly autonomous, AI-driven environment. The model is structured across three functional pillars—Data, View, and Analysis—and progresses through three key service tiers.
Here is a breakdown of the evolving stages:
1. Basic Tier (The Foundation)
This is the foundational level, focusing on essential monitoring and billing.
- Data: It begins with collecting Server Room Data via APIs.
- View: Operators use a Server Room 2D View to track basic statuses like room layouts, rack placement, power consumption, and temperatures.
- Analysis: The collected data is used to generate a basic Usage Report, primarily for customer billing.
2. Enhanced Tier (Real-time & Expanded Scope)
This tier broadens the monitoring scope and provides deeper operational insights.
- Data: Data collection is expanded beyond the server room to include the Common Facility (Data Extension).
- View: The user interface upgrades to a dynamic Dashboard that displays real-time operational trends.
- Analysis: Reporting evolves into an Analysis Report, designed to extract deeper insights and improve overall service value.
3. The Bridge: Data Quality Up
Before transitioning to the ultimate AI-driven tier, there is a critical prerequisite layer. To effectively utilize AI, the system must secure data of High Precision & High Resolution. High-quality data is the fuel for the advanced services that follow.
4. Premium Tier (AI Agent as the Ultimate Orchestrator)
This is the ultimate goal of the model. The updated diagram highlights a clear, sequential flow where each advanced technology builds upon the last, culminating in a comprehensive AI Agent Service:
- AI/ML Service: The high-quality data is first processed here to automatically detect anomalies and calculate optimizations (e.g., maximizing cooling and power efficiency).
- Digital Twin: The analytical insights from the AI/ML layer are then integrated into a Digital Twin—a virtual, highly accurate replica of the physical data center used for real-time simulation and spatial monitoring.
- AI Agent Service: This is the final and most critical layer. The AI Agent does not just sit alongside the other tools; it acts as the central brain. Through this final Agent Service, the capabilities of all preceding services are expanded and put into action. By leveraging the predictive power of the AI/ML models and the comprehensive visibility of the Digital Twin, the AI Agent can autonomously manage, resolve issues, and optimize the data center, maximizing the ultimate value of the entire data pipeline.
#DataCenter #DCIM #AIAgent #DigitalTwin #MachineLearning #ITOperations #TechInfrastructure #FutureOfTech #SmartDataCenter



