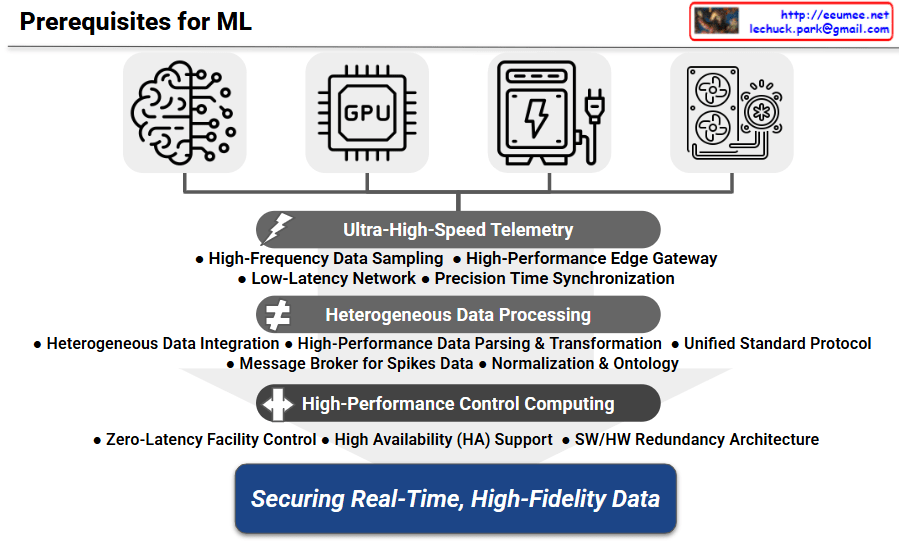
Architecture Overview: Prerequisites for ML
1. Data Sources: Convergence of IT and OT (Top Layer)
The diagram outlines four core domains essential for machine learning-based control in an AI data center. The top layer illustrates the necessary integration of IT components (AI workloads and GPUs) and Operational Technology (Power/ESS and Cooling systems). It emphasizes that the first prerequisite for an AI data center agent is to aggregate status data from these historically siloed equipment groups into a unified pipeline.
2. Collection Phase: Ultra-High-Speed Telemetry
The subsequent layer focuses on data collection. Because power spikes unique to AI workloads occur in milliseconds, the architecture demands High-Frequency Data Sampling and a Low-Latency Network. Furthermore, Precision Time Synchronization is highlighted as a critical requirement; the timestamps of a sudden GPU load spike must perfectly align with temperature changes in the cooling system for the ML model to establish accurate causal relationships.
3. Processing Phase: Heterogeneous Data Processing
As incoming data points utilize varying communication protocols and polling intervals, the third layer addresses data refinement. It employs a Unified Standard Protocol to convert heterogeneous data, along with Normalization & Ontology mapping so the ML model can comprehend the physical relationships between IT servers and facility cooling units. Additionally, a Message Broker for Spikes Data is included as a buffer to prevent system bottlenecks or data loss during the massive influx of telemetry that occurs at the onset of large-scale distributed training.
4. Execution Phase: High-Performance Control Computing
Following data processing, the execution layer is designed to take direct action on the facility infrastructure. This phase requires Zero-Latency Facility Control computing power to enable immediate physical responses. To meet the zero-downtime demands of data center operations, this layer incorporates a comprehensive SW/HW Redundancy Architecture to guarantee absolute High Availability (HA).
5. Ultimate Goal: Securing Real-Time, High-Fidelity Data
The foundational layers culminate in the ultimate goal shown at the bottom: Securing Real-Time, High-Fidelity Data. This emphasizes that predictive control algorithms cannot function effectively with noisy or delayed inputs. A robust data infrastructure is the definitive prerequisite for enabling proactive pre-cooling and ESS optimization.
📝 Summary
- A successful ML-driven data center operation requires a robust, high-speed data foundation prior to deploying predictive algorithms.
- Bridging the gap between IT (GPUs) and OT (Power/Cooling) through synchronized, high-frequency telemetry forms the core of this architecture.
- Securing real-time, high-fidelity data enables the crucial transition from delayed reactive responses to proactive predictive cooling and energy optimization.
#AIDataCenter #MachineLearning #ITOTConvergence #DataPipeline #PredictiveControl #Telemetry