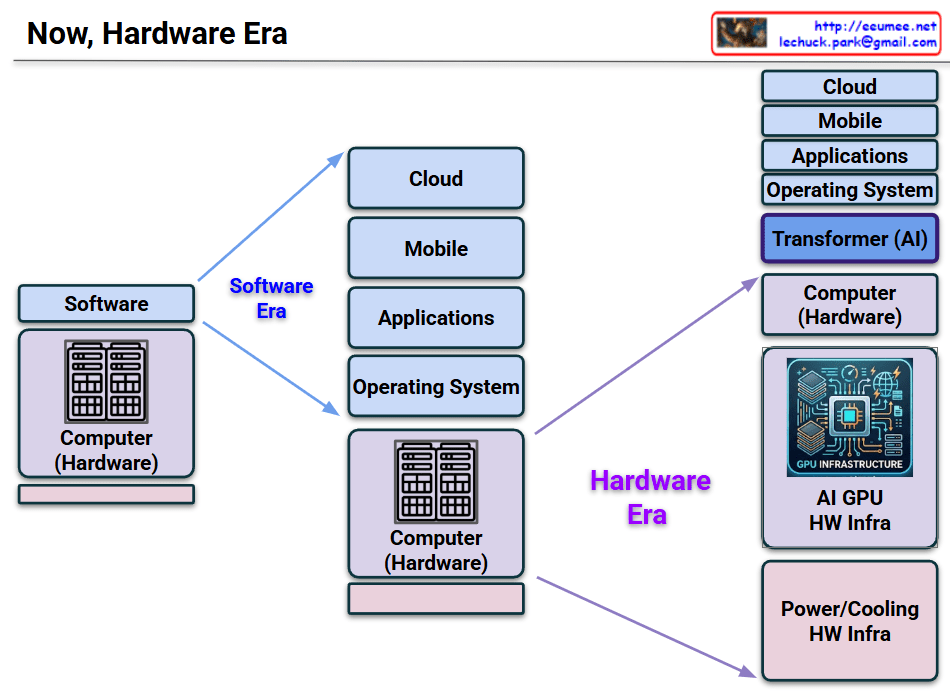
This image is an insightful architectural diagram illustrating the major paradigm shift in the IT industry, transitioning from the past “Software Era” to the current “Hardware Era.”
On the left side, representing the Software Era, the structure is heavily focused on software expansion. A single, traditional “Computer (Hardware)” block serves as a basic foundation to support a growing stack of software components: Operating System, Applications, Mobile, and Cloud. During this time, hardware was largely viewed as a standardized commodity to run software.
On the right side, representing the current Hardware Era, the diagram shows a significant architectural transformation driven by Artificial Intelligence.
Here are the key changes:
The Insertion of AI: A new, prominent purple block labeled “Transformer (AI)” is inserted right beneath the traditional software stack. This signifies that AI models have become the core engine and an indispensable layer for modern IT services.
Expansion of Hardware Infrastructure: To support the massive computational demands of the AI layer, the hardware section at the bottom has expanded dramatically into three distinct pillars:
Computer (Hardware): The traditional CPU-based computing servers.
AI GPU HW Infra: A large, specialized block featuring a detailed microchip icon. This highlights the absolute necessity of high-performance GPU clusters, high-bandwidth memory (HBM), and high-speed networking to process AI workloads.
Power/Cooling HW Infra: This is perhaps the most critical new addition. It visually emphasizes that running massive AI GPU clusters requires enormous energy and generates immense heat. Consequently, power supply and advanced cooling systems are no longer just facility management issues, but a core component of the IT infrastructure itself.
The diagram visualizes how the advent of AI has shifted the industry’s bottleneck and focus back to building robust, highly specialized hardware and the physical power/cooling infrastructure required to sustain it.
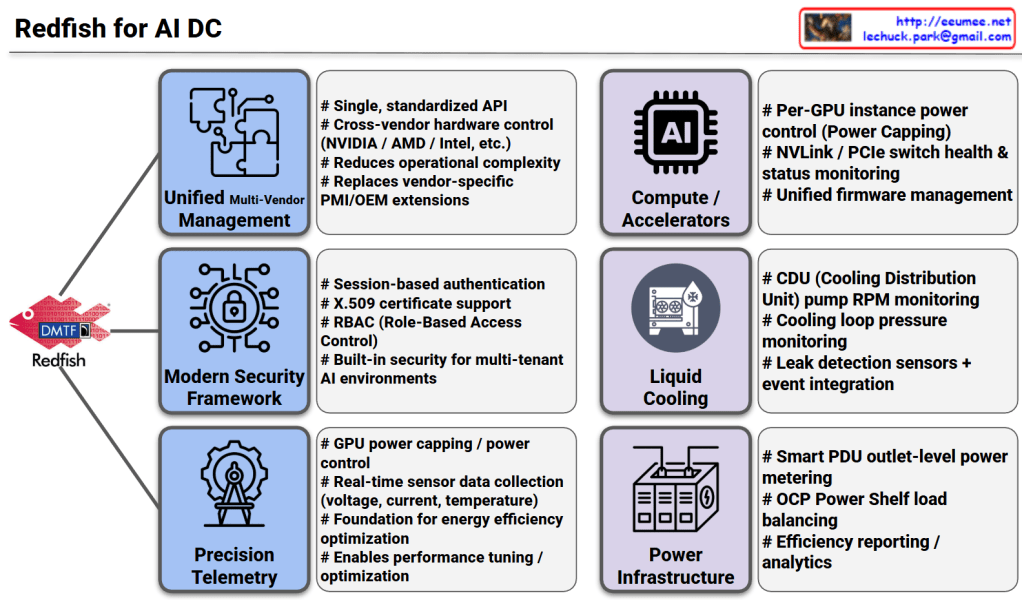
This image illustrates the pivotal role of the Redfish API (developed by DMTF) as the standardized management backbone for modern AI Data Centers (AI DC). As AI workloads demand unprecedented levels of power and cooling, Redfish moves beyond traditional server management to provide a unified framework for the entire infrastructure stack.
1. Management & Security Framework (Left Column)
Unified Multi-Vendor Management:
Acts as a single, standardized API to manage diverse hardware from different vendors (NVIDIA, AMD, Intel, etc.).
It reduces operational complexity by replacing fragmented, vendor-specific IPMI or OEM extensions with a consistent interface.
Modern Security Framework:
Designed for multi-tenant AI environments where security is paramount.
Supports robust protocols like session-based authentication, X.509 certificates, and RBAC (Role-Based Access Control) to ensure only authorized entities can modify critical infrastructure.
Precision Telemetry:
Provides high-granularity, real-time data collection for voltage, current, and temperature.
This serves as the foundation for energy efficiency optimization and fine-tuning performance based on real-time hardware health.
2. Infrastructure & Hardware Control (Right Column)
Compute / Accelerators:
Enables per-GPU instance power capping, allowing operators to limit power consumption at a granular level.
Monitors the health of high-speed interconnects like NVLink and PCIe switches, and simplifies firmware lifecycle management across the cluster.
Liquid Cooling:
As AI chips run hotter, Redfish integrates with CDU (Cooling Distribution Unit) systems to monitor pump RPM and loop pressure.
It includes critical safety features like leak detection sensors and integrated event handling to prevent hardware damage.
Power Infrastructure:
Extends management to the rack level, including Smart PDU outlet metering and OCP (Open Compute Project) Power Shelf load balancing.
Facilitates advanced efficiency analytics to drive down PUE (Power Usage Effectiveness).
Summary
For an AI DC Optimization Architect, Redfish is the essential “language” that enables Software-Defined Infrastructure. By moving away from manual, siloed hardware management and toward this API-driven approach, data centers can achieve the extreme automation required to shift OPEX structures predominantly toward electricity costs rather than labor.
End-to-End AI Factory Optimization: Bridging Infrastructure and Business Value
This diagram outlines a comprehensive framework for optimizing an “AI Factory”—a modern data center dedicated to AI workloads. The core message is that optimizing AI performance and cost requires a holistic view that connects physical infrastructure realities directly to high-level business Service Level Agreements (SLAs).
Here is a breakdown of the three main pillars of this framework:
1. The AI Factory (Infrastructure Foundation)
On the far left, we see the AI Factory itself. This represents the converged physical infrastructure required to run massive AI models (indicated by the neural network icons).
It emphasizes that the critical hardware components—GPUs (Compute), Networking, Power, and Cooling—cannot be managed in silos. They are marked as “ULTRA CONNECTED,” meaning the behavior of one directly impacts the others (e.g., intense GPU activity spikes power demand and generates immediate heat, requiring instant cooling response).
2. Ultra Data Quality (The Intelligence Layer)
In the center, the diagram highlights the necessity of Ultra Data Quality. To optimize such a complex, interconnected system, standard logging isn’t enough. The telemetry data collected from the infrastructure must meet three critical criteria:
Ultra Precision & Resolution: Capturing minute details of operations.
Ultra Time-Sync: The ability to perfectly synchronize timestamps across different hardware types (e.g., nanosecond-level GPU events vs. millisecond-level cooling events) to understand cause-and-effect relationships accurately.
3. Cost & SLA vs. Usage+Performance (The Value Realization)
The right section is the most critical, showing the direct mapping between physical operational metrics (Usage+Performance) and business outcomes (Cost & SLA). It argues that physical stability directly dictates business success:
TOKEN (Output/Revenue) ↔ Clock Consistency: To maintain a steady stream of AI output (tokens), the GPU clock speeds must remain consistent and stable without fluctuating.
FLOPS (Peak Compute Power) ↔ Zero Throttling Events: Achieving maximum floating-point operations per second requires eliminating “throttling”—performance downgrades caused by overheating or power constraints.
Watt (Operational Cost) ↔ Power Draw vs TDP: Managing operational expenses (electricity bills) requires optimizing the actual power draw relative to the hardware’s Thermal Design Power (TDP) limits.
PUE (Data Center Efficiency) ↔ Thermal Headroom: The overall Power Usage Effectiveness of the facility depends on optimizing “thermal headroom”—managing how close the cooling systems run to their limits without wasting energy.
This diagram illustrates that optimizing an AI business isn’t just about better code or faster chips; it requires an end-to-end approach where the physical realities of power, cooling, and hardware are tightly integrated with data analytics to ensure performance promises (SLAs) are met cost-effectively.
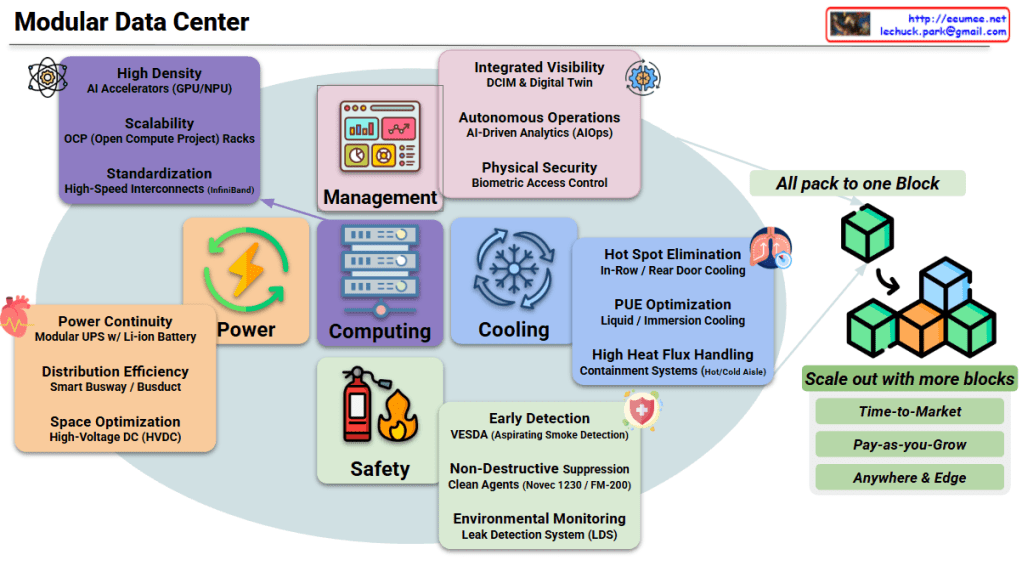
This image illustrates a comprehensive Modular Data Center architecture designed specifically for modern AI/ML workloads, showcasing integrated systems and their key capabilities.
Core Components
1. Management Layer
Integrated Visibility: DCIM & Digital Twin for real-time monitoring
Autonomous Operations: AI-Driven Analytics (AIOps) for predictive maintenance
Physical Security: Biometric Access Control for enhanced protection
2. Computing Infrastructure
High Density AI Accelerators: GPU/NPU optimized for AI workloads
Scalability: OCP (Open Compute Project) Racks for standardized deployment
Standardization: High-Speed Interconnects (InfiniBand) for low-latency communication
3. Power Systems
Power Continuity: Modular UPS with Li-ion Battery for reliable uptime
Distribution Efficiency: Smart Busway/Busduct for optimized power delivery
Space Optimization: High-Voltage DC (HVDC) for reduced footprint
4. Cooling Solutions
Hot Spot Elimination: In-Row/Rear Door Cooling for targeted heat removal
PUE Optimization: Liquid/Immersion Cooling for maximum efficiency
High Heat Flux Handling: Containment Systems (Hot/Cold Aisle) for AI density
5. Safety & Environmental
Early Detection: VESDA (Very Early Smoke Detection Apparatus)
Environmental Monitoring: Leak Detection System (LDS)
Why Modular DC is Critical for AI Data Centers
Speed & Agility
Traditional data centers take 18-24 months to build, but AI demands are exploding NOW. Modular DCs deploy in 3-6 months, allowing organizations to capture market opportunities and respond to rapidly evolving AI compute requirements without lengthy construction cycles.
AI-Specific Thermal Challenges
AI workloads generate 3-5x more heat per rack (30-100kW) compared to traditional servers (5-10kW). Modular designs integrate advanced liquid cooling and containment systems from day one, purpose-built to handle GPU/NPU thermal density that would overwhelm conventional infrastructure.
Elastic Scalability
AI projects often start experimental but can scale exponentially. The “pay-as-you-grow” model lets organizations deploy one block initially, then add capacity incrementally as models grow—avoiding massive upfront capital while maintaining consistent architecture and avoiding stranded capacity.
Edge AI Deployment
AI inference increasingly happens at the edge for latency-sensitive applications (autonomous vehicles, smart manufacturing). Modular DCs’ compact, self-contained design enables AI deployment anywhere—from remote locations to urban centers—with full data center capabilities in a standardized package.
Operational Efficiency
AI workloads demand maximum PUE efficiency to manage operational costs. Modular DCs achieve PUE of 1.1-1.3 through integrated cooling optimization, HVDC power distribution, and AI-driven management—versus 1.5-2.0 in traditional facilities—critical when GPU clusters consume megawatts.
Key Advantages
📦 “All pack to one Block” – Complete infrastructure in pre-integrated modules 🧩 “Scale out with more blocks” – Linear, predictable expansion without redesign
⏱️ Time-to-Market: 4-6x faster deployment vs traditional builds
💰 Pay-as-you-Grow: CapEx aligned with revenue/demand curves
🌍 Anywhere & Edge: Containerized deployment for any location
Summary
Modular Data Centers are essential for AI infrastructure because they deliver pre-integrated, high-density compute, power, and cooling blocks that deploy 4-6x faster than traditional builds, enabling organizations to rapidly scale GPU clusters from prototype to production while maintaining optimal PUE efficiency and avoiding massive upfront capital investment in uncertain AI workload trajectories.
The modular approach specifically addresses AI’s unique challenges: extreme thermal density (30-100kW/rack), explosive demand growth, edge deployment requirements, and the need for liquid cooling integration—all packaged in standardized blocks that can be deployed anywhere in months rather than years.
This architecture transforms data center infrastructure from a multi-year construction project into an agile, scalable platform that matches the speed of AI innovation, allowing organizations to compete in the AI economy without betting the company on fixed infrastructure that may be obsolete before completion.
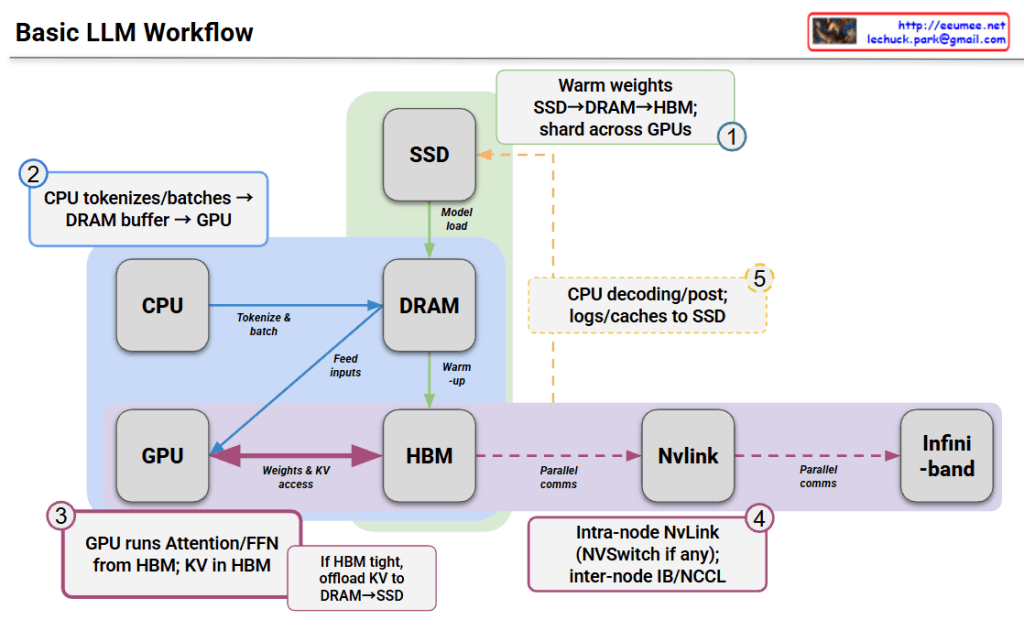
When model size exceeds GPU memory, strategies include distributing across multiple GPUs or offloading data to higher-level memory tiers.
Summary
This diagram shows how LLMs process data through a memory hierarchy (SSD→DRAM→HBM) across CPU and GPU components. The workflow involves loading model weights, tokenizing inputs on CPU, running inference on GPU with HBM, and using distributed communication (NvLink/InfiniBand) for multi-GPU setups. Memory management strategies like KV cache offloading enable efficient execution of large models that exceed single GPU capacity.
These three elements must be organically combined – this is the core message of the diagram.
Summary
LLM optimization requires integrating traditional deterministic SW/HW optimization with new paradigms: probabilistic/statistical approaches that mirror human language understanding and learning, plus hardware architectures designed for massive parallel processing. This represents a fundamental shift from conventional optimization, where human-centric probabilistic thinking and large-scale parallelism are not optional but essential dimensions.
PUE Improvement: Power Usage Effectiveness (overall power efficiency metric)
Key Message
This diagram emphasizes that for successful AI implementation:
Technical Foundation: Both Data/Chips (Computing) and Power/Cooling (Infrastructure) are necessary
Tight Integration: These two axes are not separate but must be firmly connected like a chain and optimized simultaneously
Implementation Technologies: Specific advanced technologies for stability and optimization in each domain must provide support
The central link particularly visualizes the interdependent relationship where “increasing computing power requires strengthening energy and cooling in tandem, and computing performance cannot be realized without infrastructure support.”
Summary
AI systems require two inseparable pillars: Computing (Data/Chips) and Infrastructure (Power/Cooling), which must be tightly integrated and optimized together like links in a chain. Each pillar is supported by advanced technologies spanning from AI model optimization (FlashAttention, Quantization) to next-gen hardware (GB200, TPU) and sustainable infrastructure (SMR, Liquid Cooling, AI-driven optimization). The key insight is that scaling AI performance demands simultaneous advancement across all layers—more computing power is meaningless without proportional energy supply and cooling capacity.