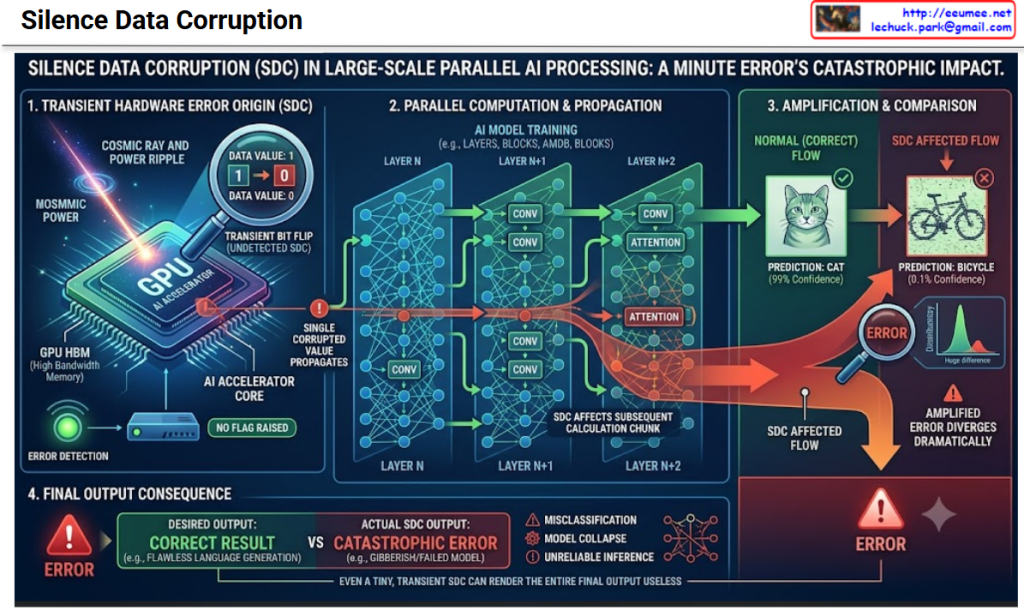
This infographic diagram illustrates the lifecycle of a single, minute, and transient error, showing how it goes undetected and exponentially amplifies through the layers of an AI model to cause a catastrophic final failure.
Step-by-Step Breakdown of the Diagram
The diagram is organized horizontally into four sequential stages, moving from the physical hardware level to the final AI application output.
Step 1: Transient Hardware Error Origin (SDC)
The leftmost section focuses on the physical cause of the error.
- Context: We see a stylized GPU AI Accelerator and GPU HBM (High Bandwidth Memory), which represent the hardware infrastructure.
- The Cause: An external physical event strikes the chip.
- COSMIC RAY AND POWER RIPPLE: This represents high-energy particles from space or a minor voltage instability in the power supply. These events can deliver a tiny electrical charge to a critical component.
- The Immediate Effect (Zoom in): This tiny charge hits a memory cell. As seen in the magnified view, it causes a TRANSIENT BIT FLIP (UNDETECTED SDC), instantly changing a data bit from
1to0. - The Essence of SDC (Red ‘!’): Crucially, the ERROR DETECTION sensor incorrectly assesses the situation, showing a green light and labeling it ‘NO FLAG RAISED.’ The system continues, unaware that the data has been corrupted. This is the ‘Silent’ aspect of SDC.
Step 2: Parallel Computation & Propagation
The central section illustrates how the corrupted value enters the AI model.
- Structure: We see an AI MODEL TRAINING flow, distributed across massive parallel blocks (e.g., LAYERS, BLOCKS, AMDB, CONV, ATTENTION) like LAYER N, LAYER N+1, and LAYER N+2.
- The Propagation Path:
- Green Arrows (Normal Flow): Most of the data processed across the millions of nodes is correct.
- Orange Arrows (SDC Affected Flow): The single flipped bit affects a small chunk of calculation in LAYER N. The diagram shows how this corruption (SDC AFFECTS SUBSEQUENT CALCULATION CHUNK) is passed on to LAYER N+1 and LAYER N+2, infecting and merging with a growing number of subsequent nodes as it progresses.
Step 3: Amplification & Comparison
The third section provides a striking side-by-side comparison of the final processed state.
- Comparison:
- Normal Flow: Had the error not occurred, the model would have made a PREDICTION: CAT (99% Confidence) with a high degree of accuracy and certainty.
- SDC Affected Flow: The minute error, after cascading through thousands of parallel nodes and multiple layers, has been dramatically amplified. The model now makes a complete misclassification, with a non-sensical and low-confidence PREDICTION: BICYCLE (0.1% Confidence).
- Graph (Error Divergence): The small SDC input (seen earlier as the single bit flip) has caused the entire output distribution to AMPLIFIED ERROR DIVERGES DRAMATICALLY.
Step 4: Final Output Consequence
The final, largest section at the bottom summarizes the real-world impact.
- The Contrast:
- Desired Output: The perfect outcome, like a flawless language generation or a critical diagnostic result (DESIRED OUTPUT: CORRECT RESULT).
- Actual SDC Output: What actually occurs due to the SDC (ACTUAL SDC OUTPUT: CATASTROPHIC ERROR). This is not just a slightly wrong answer; it can be complete gibberish, a crashed model, or a dangerously incorrect real-world action.
- Summary of Impact: The diagram lists the core failures: MISCLASSIFICATION, MODEL COLLAPSE, and UNRELIABLE INFERENCE, rendering the entire output useless.
Conclusion: Why SDC is a Catastrophic Danger
The ultimate takeaway, as stated in the title and the final caption, is that EVEN A TINY, TRANSIENT SDC CAN RENDER THE ENTIRE FINAL OUTPUT USELESS. In large-scale, massive parallel AI processing, a single, undetectable bit flip can cascade and multiply, causing a model that looks perfect to fail catastrophically.
#SilentDataCorruption #SDC #AI #MachineLearning #DeepLearning #LargeScaleAI #DistributedComputing #ParallelProcessing #HighPerformanceComputing #HPC
With Gemini (inc. infographic)

