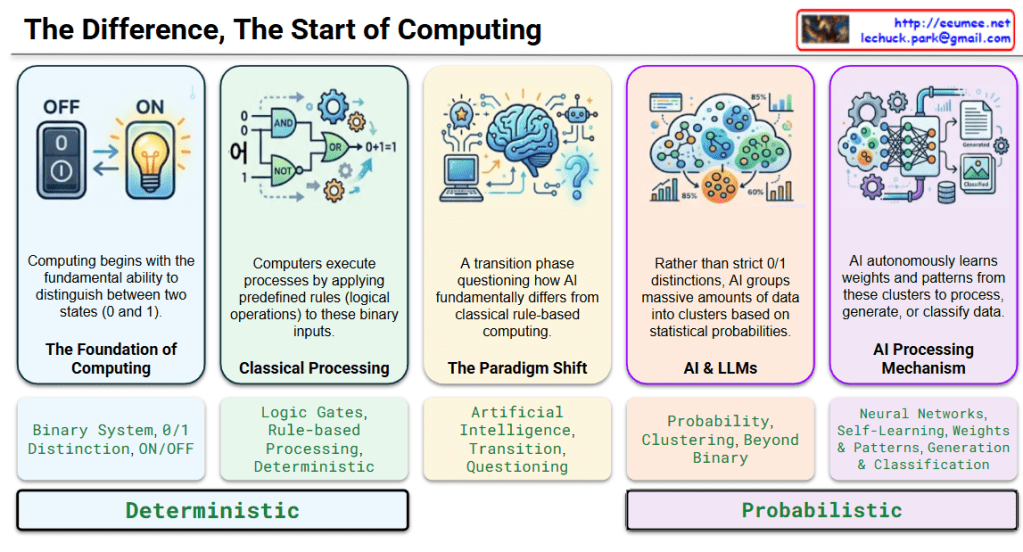
The provided image is an infographic that visually compares the operational mechanisms of traditional computing and modern Artificial Intelligence (AI). The addition of the keywords “Deterministic” and “Probabilistic” at the bottom perfectly summarizes the core difference between these two paradigms.
1. The World of Deterministic Computing
This section explains the traditional computer mechanism, which consistently produces the same output based on predefined, rigid rules.
- Step 1: The Foundation of Computing
- Visuals: An intuitive ON/OFF power switch and an illuminated lightbulb.
- Meaning: Computing begins with the fundamental Binary System, which distinguishes between two clear states: 0 (OFF) and 1 (ON).
- Step 2: Classical Processing
- Visuals: Logic gate symbols (AND, OR, NOT) interlocked with gears.
- Meaning: It illustrates how conventional computers process binary inputs mechanically by applying predefined human rules and logical operations (Rule-based Processing).
2. The Paradigm Shift
- Step 3: Questioning and Transition
- Visuals: A brain integrated with electronic circuits, a computer, a robot icon, and a large question mark in the center.
- Meaning: This represents a technological leap, asking the core question: “How does AI fundamentally differ from classical rule-based computing?”
3. The World of Probabilistic Computing
This section explains AI’s mechanism, which relies on data statistics and probabilities to self-learn and generate flexible outcomes.
- Step 4: AI & LLMs (Large Language Models)
- Visuals: A cloud containing clustered data nodes of various colors and statistical charts showing probabilities like 85% and 60%.
- Meaning: Instead of making strict 0/1 distinctions, AI groups massive amounts of data into Clusters based on statistical Probabilities.
- Step 5: AI Processing Mechanism
- Visuals: A complex Artificial Neural Network structure combined with processing gears, leading to output files labeled “Generated” (images) and “Classified” (documents).
- Meaning: Without relying on explicit human programming, AI autonomously learns weights and internal patterns (Self-Learning) from these probabilistic clusters to create new content or classify data.
📌 Summary
This infographic acts as a visual map showcasing the evolution of computing history from the era of “Deterministic Rules” to the era of “Probabilistic Self-Learning.”
It intuitively conveys the core difference: while early computers relied on clear 0/1 distinctions and explicit human-written code, modern AI (like LLMs) groups vast amounts of data by probability and autonomously learns internal patterns and weights to deliver flexible, creative, and highly advanced results.
#ArtificialIntelligence #AIComputing #HistoryOfComputing #Deterministic #Probabilistic #LLM #MachineLearning #TechInfographic #TechTrends #TechExplanation
With Gemini