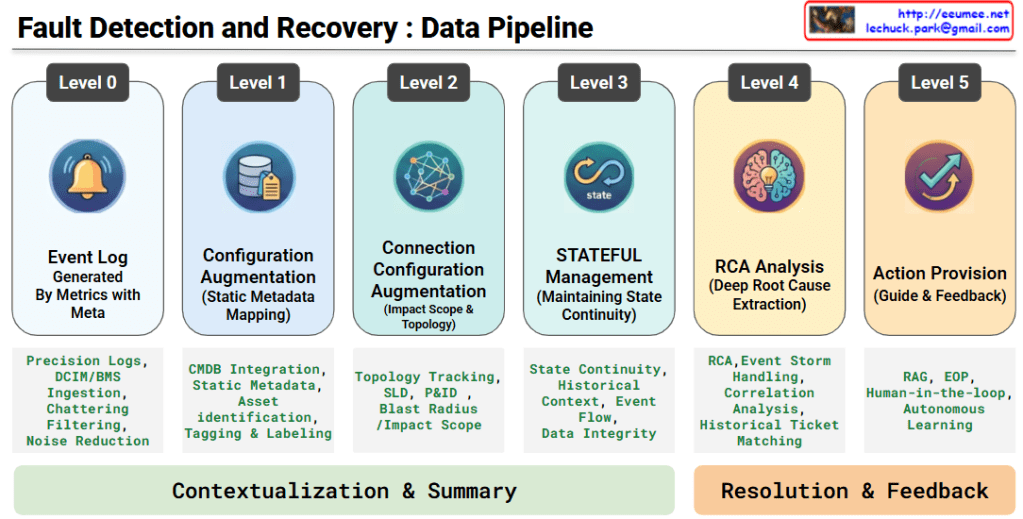
Fault Detection and Recovery: Data Pipeline
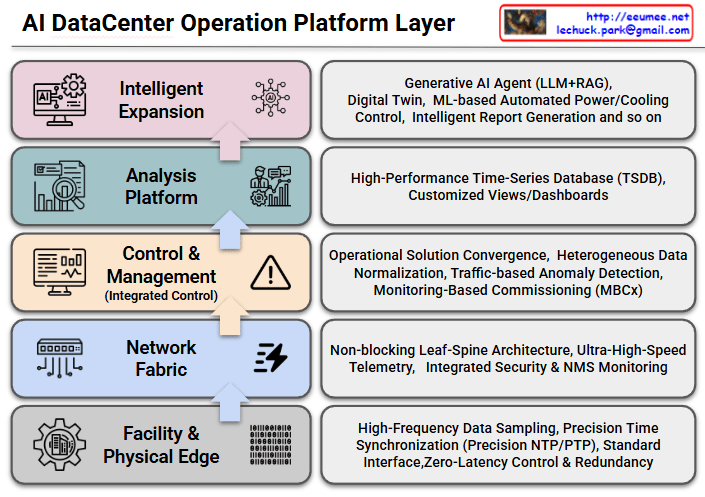
This architecture illustrates an advanced, six-stage, end-to-end data pipeline designed for an AI-driven infrastructure agent. It demonstrates how raw telemetry is systematically transformed into actionable, automated remediation through two primary phases.
Phase 1: Contextualization & Summary
This phase is dedicated to building a high-resolution, stateful understanding of the infrastructure. It takes raw alerts and layers them with critical physical and logical context.
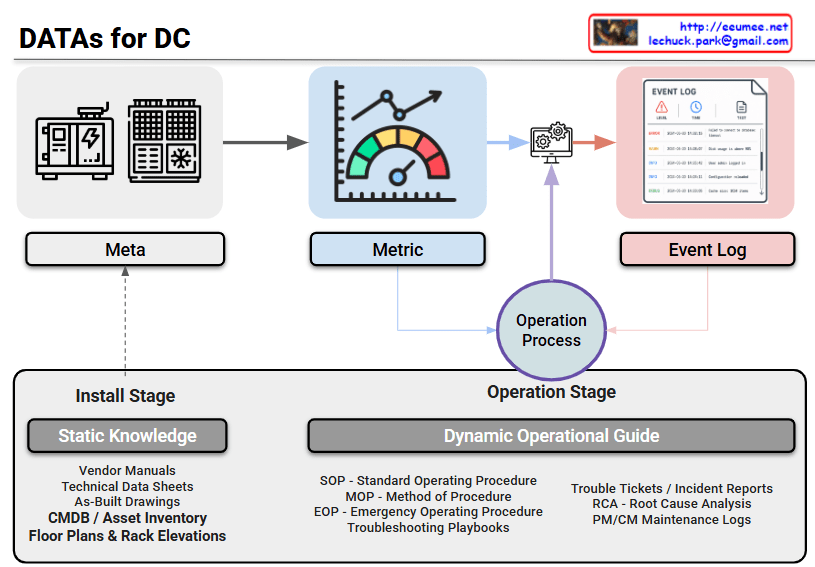
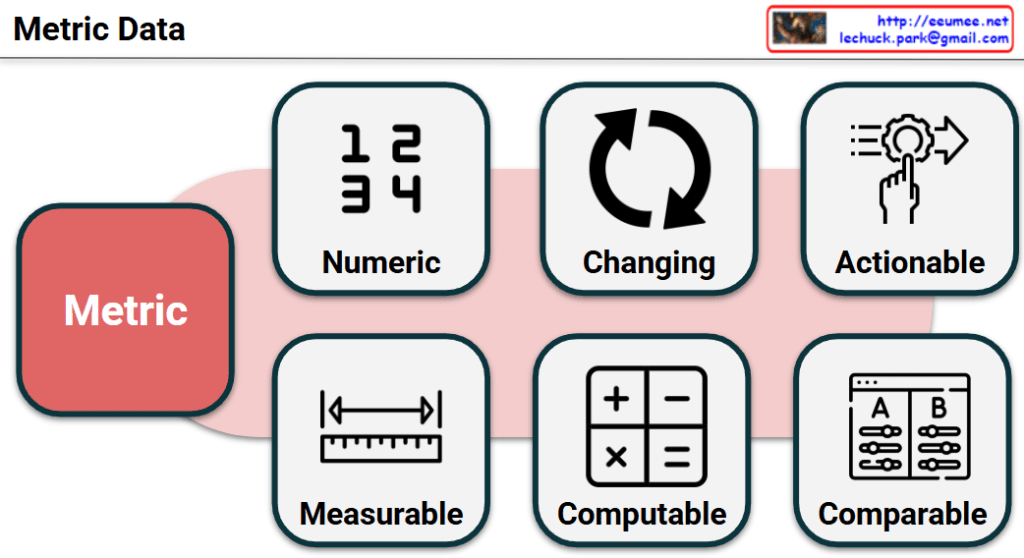
- Level 0: Event Log (Generated By Metrics with Meta)The foundation of the pipeline. High-precision logs and telemetry are ingested from DCIM/BMS systems. Crucially, this stage performs chattering filtering and noise reduction to isolate genuine anomalies from meaningless alerts.
- Level 1: Configuration Augmentation (Static Metadata Mapping)Raw events are enriched by integrating with the CMDB. By mapping static metadata to the alerts, the system performs precise asset identification, tagging, and labeling to know exactly which component is affected.
- Level 2: Connection Configuration Augmentation (Impact Scope & Topology)The pipeline maps the isolated asset against physical and logical topologies (such as Single Line Diagrams and P&IDs). This enables the system to track dependencies and accurately calculate the blast radius or impact scope of a fault.
- Level 3: STATEFUL Management (Maintaining State Continuity)Moving beyond isolated, point-in-time alerts, this level links current events with historical context and event flows. It ensures data integrity and maintains a continuous, stateful tracking of the system’s health.
Phase 2: Resolution & Feedback
With a fully contextualized baseline established, the pipeline shifts from situational awareness to intelligent diagnosis and automated remediation.
- Level 4: RCA Analysis (Deep Root Cause Extraction)During an event storm, the system performs advanced correlation analysis and historical trouble-ticket matching. It sifts through the cascading symptoms to pinpoint the deep root cause (RCA) of the failure.
- Level 5: Action Provision (Guide & Feedback)In the final stage, the platform leverages RAG (Retrieval-Augmented Generation) to instantly surface the most relevant Emergency Operating Procedures (EOP). By incorporating a Human-in-the-loop (HITL) feedback mechanism, expert operators validate the actions, allowing the AI model to continuously undergo autonomous learning and refine its future responses.
Summary
This data pipeline elegantly maps the journey from raw infrastructure noise to intelligent, automated resolution. By progressively layering static configuration data, topology mapping, and stateful tracking over high-precision logs, the architecture effectively neutralizes event storms. Ultimately, it empowers AI-driven agents to deliver highly accurate root cause analyses and RAG-assisted operational guides, creating a resilient system that continuously learns and improves through expert human feedback.
#AIOps #DataCenterArchitecture #RootCauseAnalysis #SystemObservability #RAG #FaultDetection #Telemetry #HumanInTheLoop #InfrastructureAutomation #TechInfographic
With Gemini