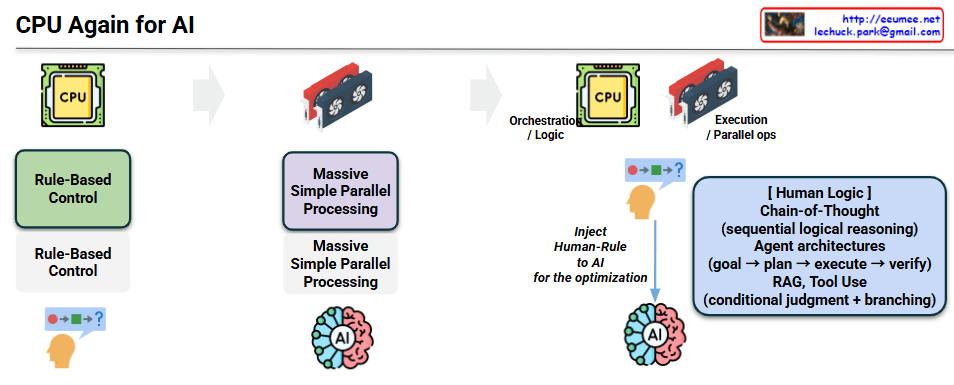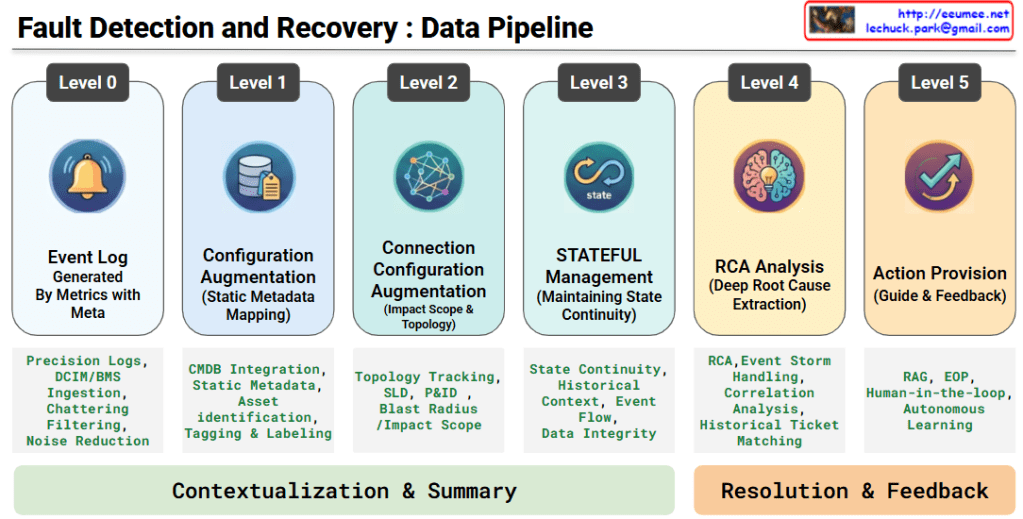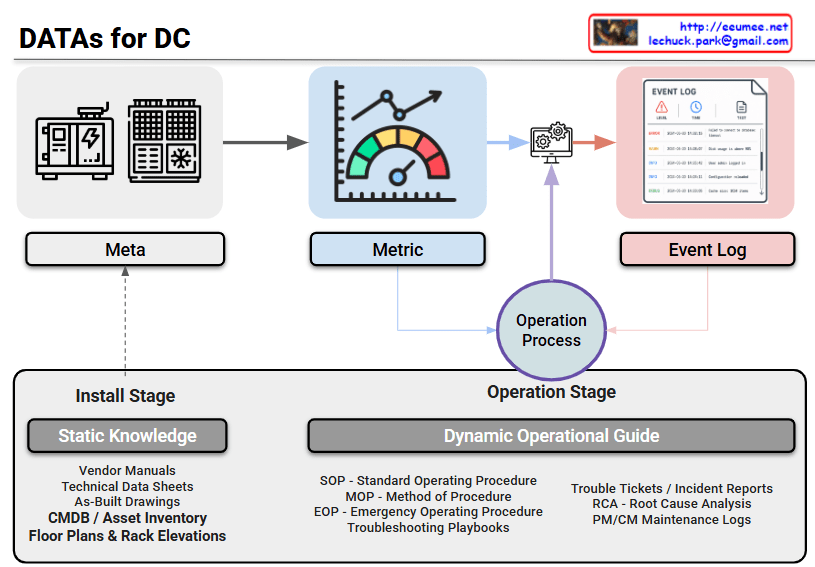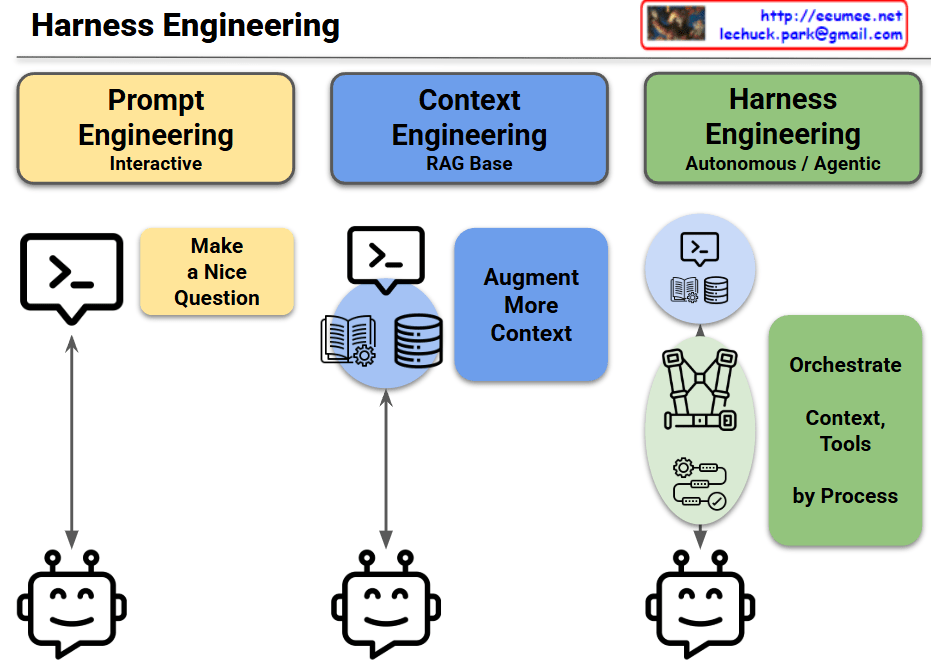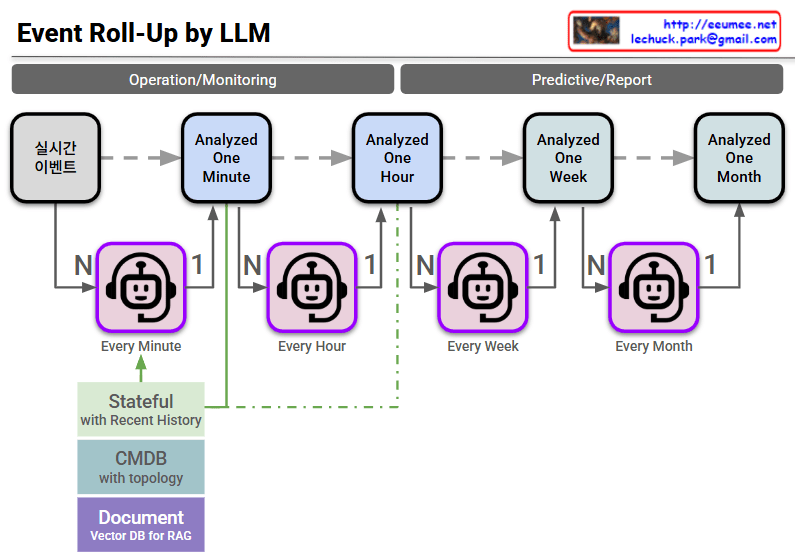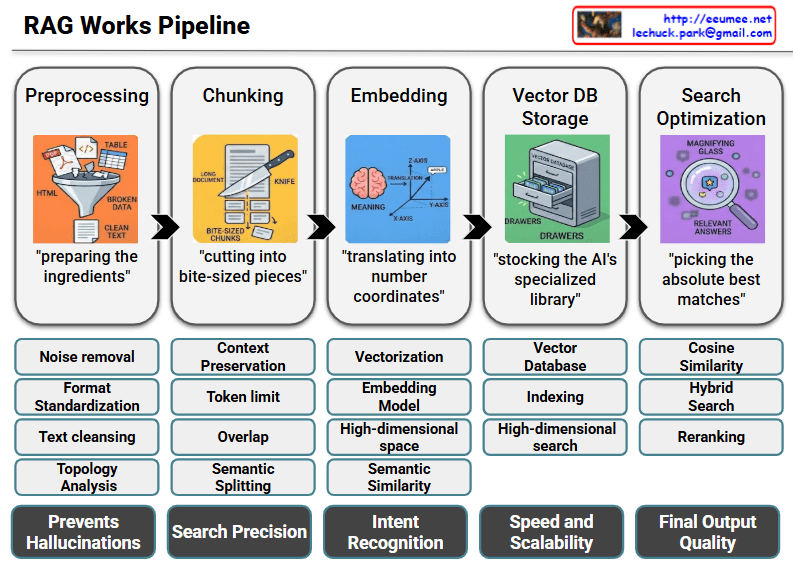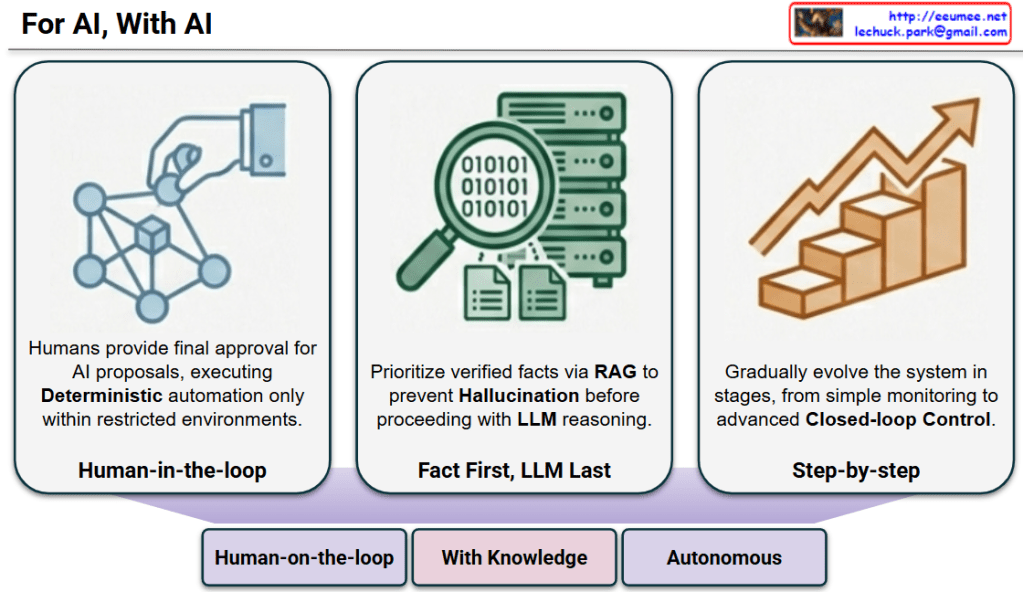
The provided image illustrates the three core operational principles of ‘For AI, With AI’ in English and outlines the future evolutionary direction of each principle through the bottom panels.
‘For AI, With AI’ Strategy and Evolutionary Direction
1. Evolution of Control: From Intervention to Supervision
- Current (Human-in-the-loop): Humans must directly intervene to provide “final approval” for AI proposals before executing deterministic automation in restricted environments.
- Evolution Direction (➡️ Human-on-the-loop): As the system advances, the human role shifts from a constant approver to an “Overseer” who monitors the system’s automated operations and intervenes only when necessary.
2. Evolution of Knowledge Utilization: From Fact-Checking to Knowledge Internalization
- Current (Fact First, LLM Last): To prevent AI hallucination, verified facts are prioritized and provided via RAG before the LLM proceeds with reasoning.
- Evolution Direction (➡️ With Knowledge): Moving beyond simple fact retrieval, the system evolves into a “Knowledge-Based System” that integrates and internalizes vast domain expertise for deeper and more accurate reasoning.
3. Evolution of Automation: From Gradual Steps to Full Autonomy
- Current (Step-by-step): The system gradually evolves in stages, starting from simple monitoring and steadily advancing toward Closed-loop Control.
- Evolution Direction (➡️ Autonomous): The ultimate goal of this gradual progression is to reach a fully “Autonomous” state, where the system can recognize, judge, and control operations independently without human intervention.
In summary:
This diagram visually presents a roadmap transitioning from the current conservative, human-controlled AI operational methods (top panels) to future AI systems that are autonomous, knowledge-embedded, and capable of independent operation (bottom panels).
#AIStrategy #ForAIWithAI #HumanInTheLoop #HumanOnTheLoop #RAG #LLM #AutonomousAI #ClosedLoopControl #AIAutomation #FutureOfAI
With Gemini