CPU Again for AI: The Evolution of Computing Paradigms
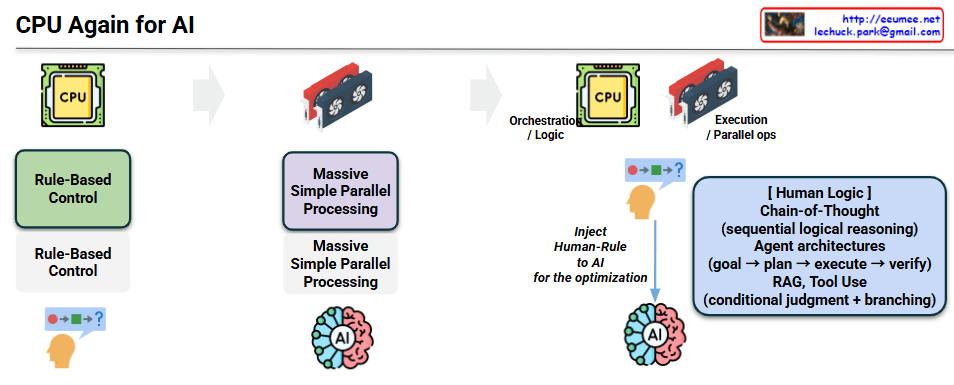
This diagram illustrates the evolutionary journey of computing architectures, highlighting why the CPU is reclaiming its pivotal role in the modern AI era. The flow is divided into three distinct phases:
1. The Era of Traditional Computing (CPU-Centric)
- Core Concept: Rule-Based Control.
- Mechanism: Historically, computing relied on explicit human logic. Developers hardcoded sequential rules and conditional branching (represented by the sequence 🔴 ➡️ 🟩 ➡️ ❓).
- Role: The CPU was the undisputed core, designed specifically to handle complex control flows, logic execution, and sequential operations.
2. The Deep Learning Boom (GPU-Centric)
- Core Concept: Massive Simple Parallel Processing.
- Mechanism: With the rise of neural networks and deep learning, the focus shifted from complex branching logic to processing vast amounts of data simultaneously.
- Role: The GPU took center stage. Its architecture, built for massive parallel operations, was perfectly suited for the mathematical matrix multiplications required by AI models, temporarily overshadowing the CPU’s control capabilities.
3. The Emergence of Agentic AI (CPU + GPU Synergy)
This represents the core message of the diagram. As AI systems become more sophisticated, they require more than just raw processing power; they need structured logic and control.
- Division of Labor:
- CPU (Orchestration / Logic): Reclaims its role as the system’s brain for control flow. It manages the overall pipeline, making conditional judgments and coordinating tasks.
- GPU (Execution / Parallel Ops): Remains the workhorse for heavy computational lifting and model inference.
- Injecting Human Logic: To optimize AI and make it capable of solving complex, real-world problems, we are injecting “Human-Rule” back into the system. This is achieved through advanced frameworks:
- Chain-of-Thought: Enabling sequential, logical reasoning rather than instant, black-box outputs.
- Agent Architectures: Implementing autonomous workflows that follow human-like cognitive steps (Goal ➡️ Plan ➡️ Execute ➡️ Verify).
- RAG & Tool Use: Requiring conditional judgment and branching to fetch external data, trigger APIs, or utilize specific tools.
Summary
While the initial AI boom was heavily reliant on the sheer parallel processing power of GPUs, the current transition towards advanced AI Agents and RAG systems necessitates complex workflow management, conditional branching, and logical reasoning. Consequently, the CPU is once again becoming a critical component within AI architectures, serving as the essential orchestrator that guides, plans, and controls the raw execution power of the GPU.
#AIArchitecture #ComputingParadigm #AgenticAI #LLMOps #RAG #CPUvsGPU #SystemArchitecture #AIOrchestration #TechTrends
With Gemini