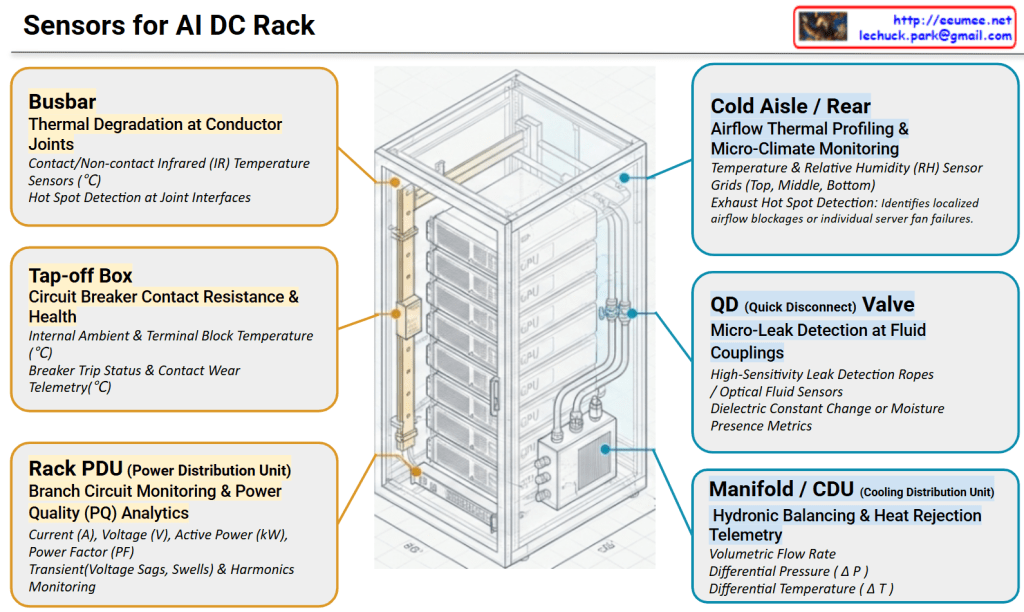
Architecture Walkthrough: High-Density AI Rack Monitoring Topology
This diagram illustrates a comprehensive monitoring framework tailored for next-generation, high-density AI Data Centers. As rack power densities scale upward of 40kW to over 100kW, the integration of high-density power delivery and advanced liquid cooling demands a unified telemetry layer. The architecture symmetrically bifurcates these critical operations into two primary domains: Power Distribution & Electrical Infrastructure (left, in yellow) and Liquid Cooling & Thermal Management (right, in blue).
1. Power Infrastructure Telemetry (Left Domain)
- Busbar (Top Left): Focuses on tracking surface temperatures at copper/aluminum busway joints using contact or non-contact infrared (IR) sensors. This mitigates the risk of thermal runaway caused by mechanical loosening or joint degradation.
- Tap-off Box (Middle Left): Monitors the critical junction where power is tapped from the main busway to individual racks. Telemetry captures internal ambient temperatures and circuit breaker contact wear to prevent nuisance tripping under heavy GPU loads.
- Rack PDU (Bottom Left): Delivers granular power quality (PQ) analytics. Beyond basic billing metrics, it utilizes high-speed sampling to capture transient events—such as voltage sags, swells, and total harmonic distortion (THD)—triggered by sudden LLM training state transitions.
2. Liquid Cooling & Thermal Management (Right Domain)
- Cold Aisle / Rear (Top Right): Provides 3D micro-climate profiling of the rack enclosure. Using sensor grids (top, middle, bottom), it tracks cold air intake and maps exhaust air behavior to instantaneously flag localized hot spots or individual server fan failures.
- QD (Quick Disconnect) Valve (Middle Right): Positions high-sensitivity leak detection ropes or optical fluid sensors directly at the fluid mating interfaces of individual GPU server blades. This safeguards expensive IT assets against coolant escape.
- Manifold / CDU (Bottom Right): Serves as the central hydronic balancing hub. By cross-referencing volumetric flow rate (LPM), differential pressure (Delta P), and differential temperature ($\Delta T$) across supply and return lines, the system continuously calculates the exact real-time heat rejection load in kW.
Executive Summary: The Imperative of High-Fidelity Infrastructure Telemetry
In a modern AI Data Center, the sheer density of accelerated computing clusters renders traditional, coarse facility monitoring completely obsolete. To ensure maximum uptime and operational efficiency, telemetry must undergo a paradigm shift governed by two critical vectors:
1. High Precision & High Resolution
Because GPU workloads scale from idle to maximum power in microseconds, sensors must feature ultra-high sampling rates (millisecond-level resolution for electrical transients) and high precision (milli-degree sensitivity for liquid thermal loops). Coarse, averaged data masks dangerous micro-spikes that degrade hardware components over time. High-resolution telemetry is the baseline requirement for capturing the true, unvarnished physical state of the infrastructure.
2. From Phenomena to Precursors (Omens)
Traditional data center monitoring is reactive—it alerts operators to a phenomenon (e.g., “Rack temperature has exceeded $85^\circ\text{C}$”), which usually means the failure has already occurred.
Conversely, high-fidelity, continuous data allows an AIOps engine to identify precursors or omens—the microscopic anomalies that precede a disaster. For instance:
- A fractional, steady rise in busbar temperature relative to a static workload implies micro-vibration joint loosening (Thermal Degradation Precursor).
- A subtle drift in the dielectric constant near a fluid coupling signals a microscopic weep before it transforms into a catastrophic spray (Leak Precursor).
- A minor, localized spike in differential pressure (Delta P) combined with a micro-drop in flow rate alerts the system to initial strainer clogging before fluid starvation throttles the GPUs.
By capturing these subtle “signs” rather than waiting for the “symptom,” data centers can transition from reactive firefighting to fully automated, self-healing predictive maintenance.
#AIDataCenter #LiquidCooling #DirectToChip #AIOps #InfrastructureTelemetry #HighDensityComputing #PredictiveMaintenance #DataCenterArchitecture #TechnicalVisualization #SmartInfrastructure
With Gemini