AI Scaling: The 6 Major Bottlenecks (2025)
1. Data
- High-quality text data expected to be depleted by 2026
- Solutions: Synthetic data (fraud detection in finance, medical data), Few-shot learning
2. LLM S/W (Algorithms)
- Ilya Sutskever: “The era of simple scaling is over. Now it’s about scaling the right things”
- Innovation directions: Test-time compute scaling (OpenAI o1), Mixture-of-Experts architecture, Hybrid AI
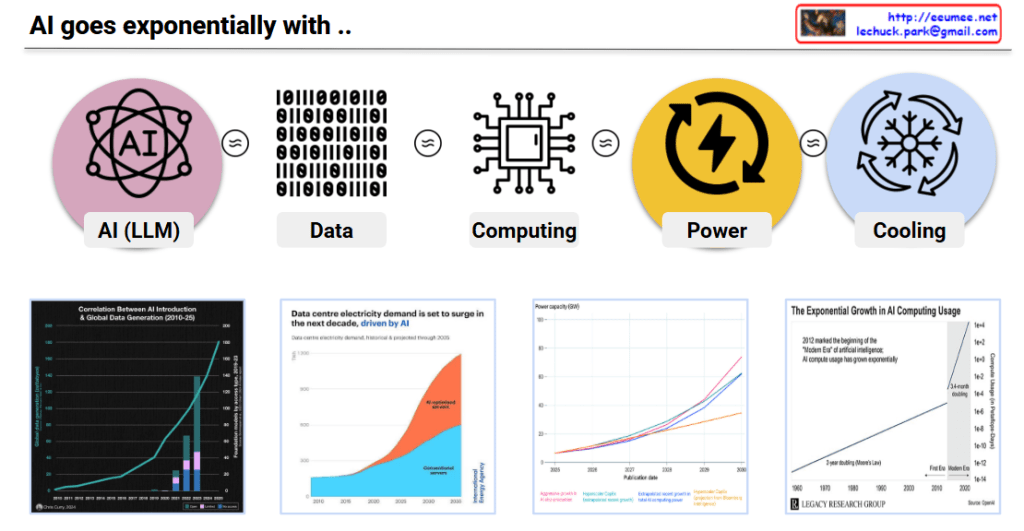
3. Computing → Heat
- GPT-3 training required 1,024 A100 GPUs for several months
- By 2030, largest training runs projected at 2-45GW scale
- GPU cluster heat generation makes cooling a critical challenge
4. Memory & Network ⚠️ Current Critical Bottleneck
Memory
- LLMs grow 410x/2yr, computing power 750x/2yr vs DRAM bandwidth only 2x/2yr
- HBM3E completely sold out for 2024-2025. AI memory market projected to grow at 27.5% CAGR
Network
- Speed of light limitation causes tens to hundreds of ms latency over distance. Critical for real-time applications (autonomous vehicles, AR)
- Large-scale GPU clusters require 800Gbps+, microsecond-level ultra-low latency
5. Power 💡 Long-term Core Constraint
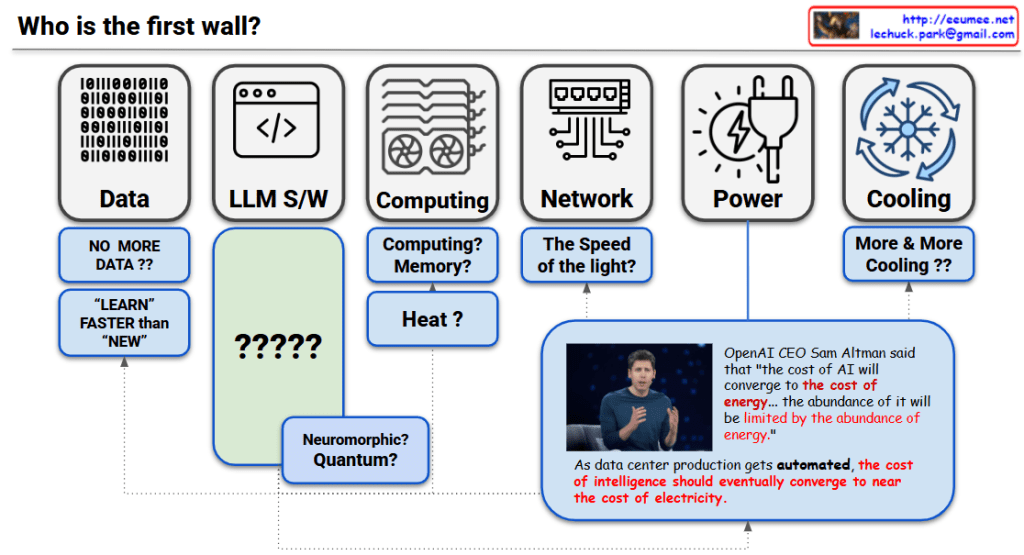
- Sam Altman: “The cost of AI will converge to the cost of energy. The abundance of AI will be limited by the abundance of energy”
- Power infrastructure (transmission lines, transformers) takes years to build
- Data centers projected to consume 7.5% of US electricity by 2030
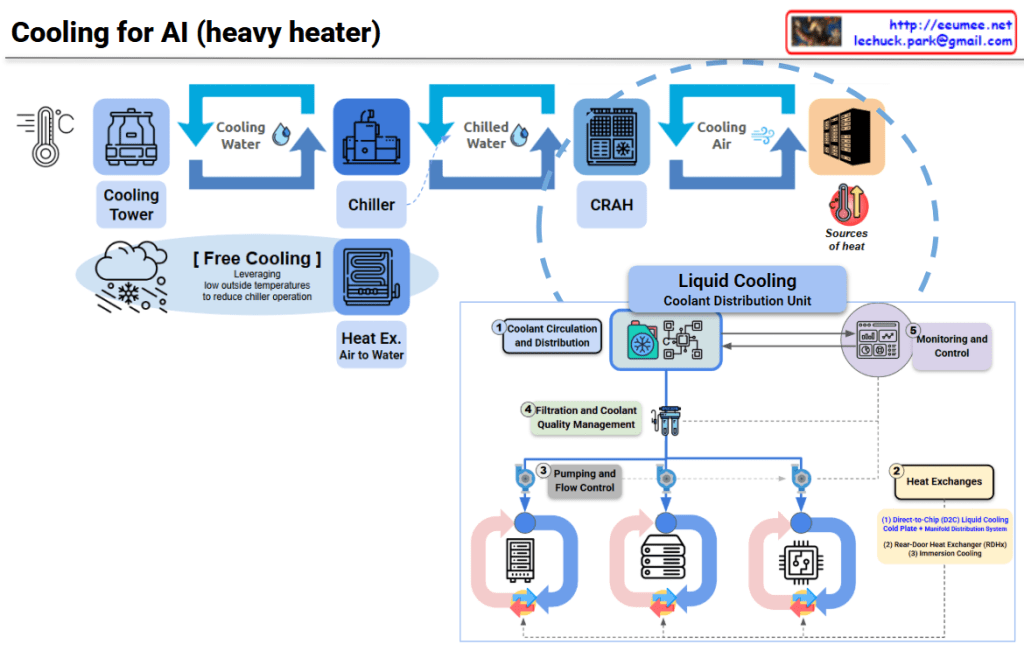
6. Cooling
- Advanced technologies like liquid cooling required. Infrastructure upgrades take 1+ year
“Who is the first wall?”
Critical Bottlenecks by Timeline:
- Current (2025): Memory bandwidth + Data quality
- Short-to-Mid term: Power infrastructure (5-10 years to build)
- Long-term: Physical limit of the speed of light
Summary
The “first wall” in AI scaling is not a single barrier but a multi-layered constraint system that emerges sequentially over time. Today’s immediate challenges are memory bandwidth and data quality, followed by power infrastructure limitations in the mid-term, and ultimately the fundamental physical constraint of the speed of light. As Sam Altman emphasized, AI’s future abundance will be fundamentally limited by energy abundance, with all bottlenecks interconnected through the computing→heat→cooling→power chain.
#AIScaling #AIBottleneck #MemoryBandwidth #HBM #DataCenterPower #AIInfrastructure #SpeedOfLight #SyntheticData #EnergyConstraint #AIFuture #ComputingLimits #GPUCluster #TestTimeCompute #MixtureOfExperts #SamAltman #AIResearch #MachineLearning #DeepLearning #AIHardware #TechInfrastructure
With Claude