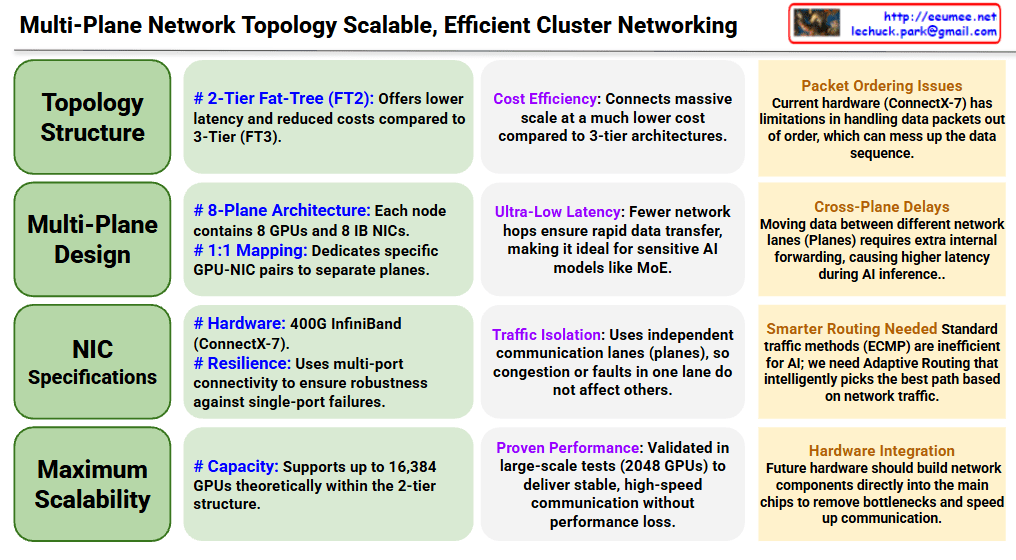
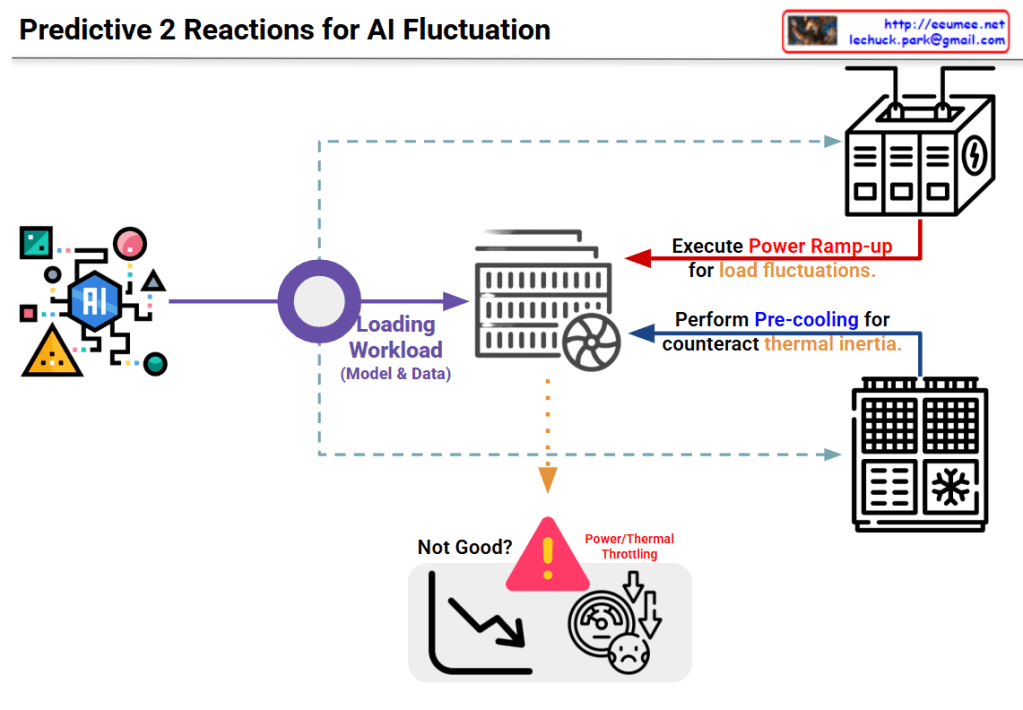
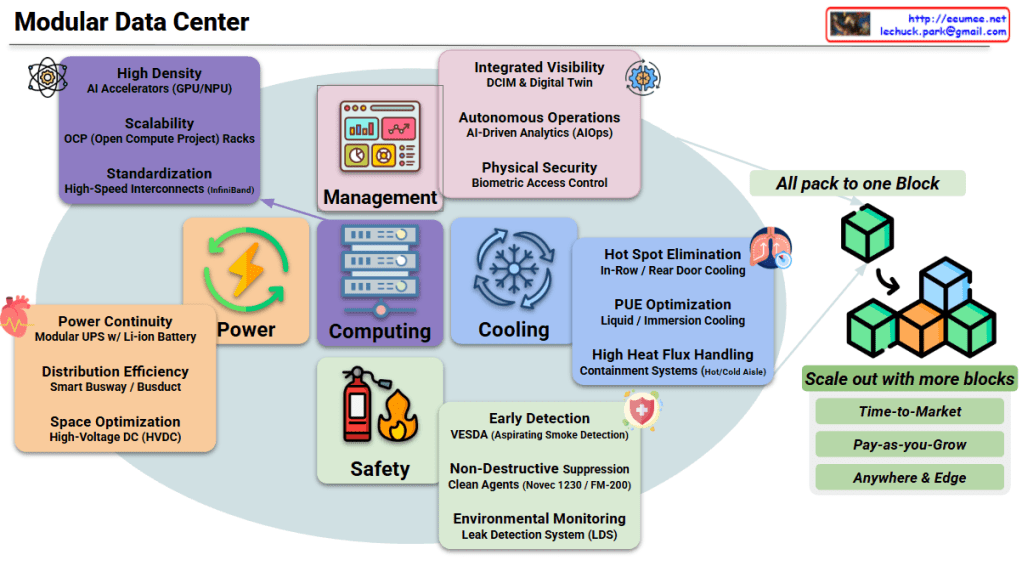
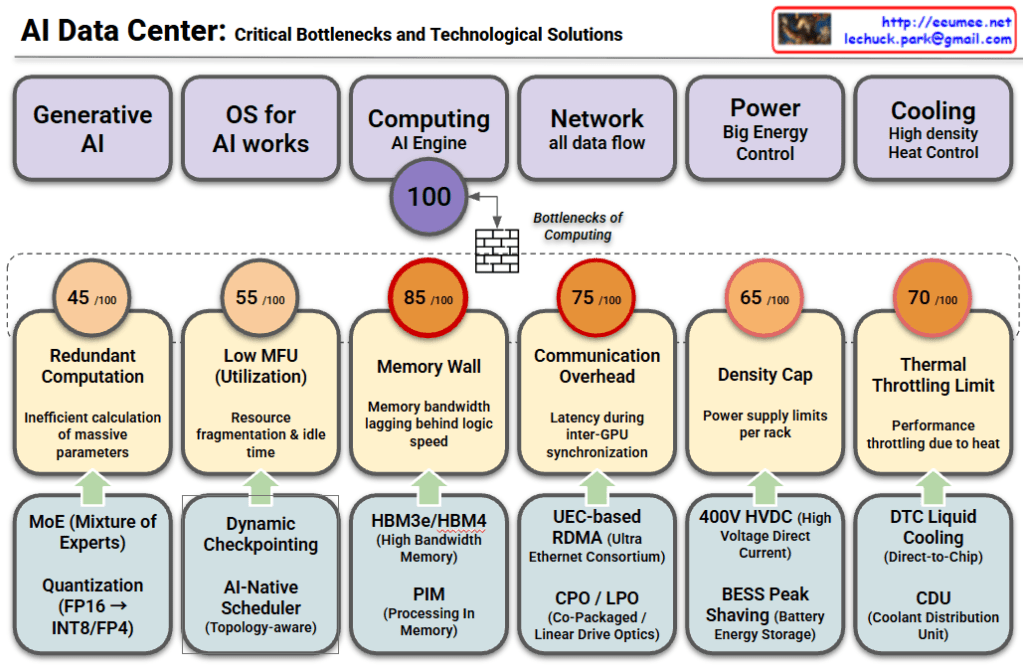
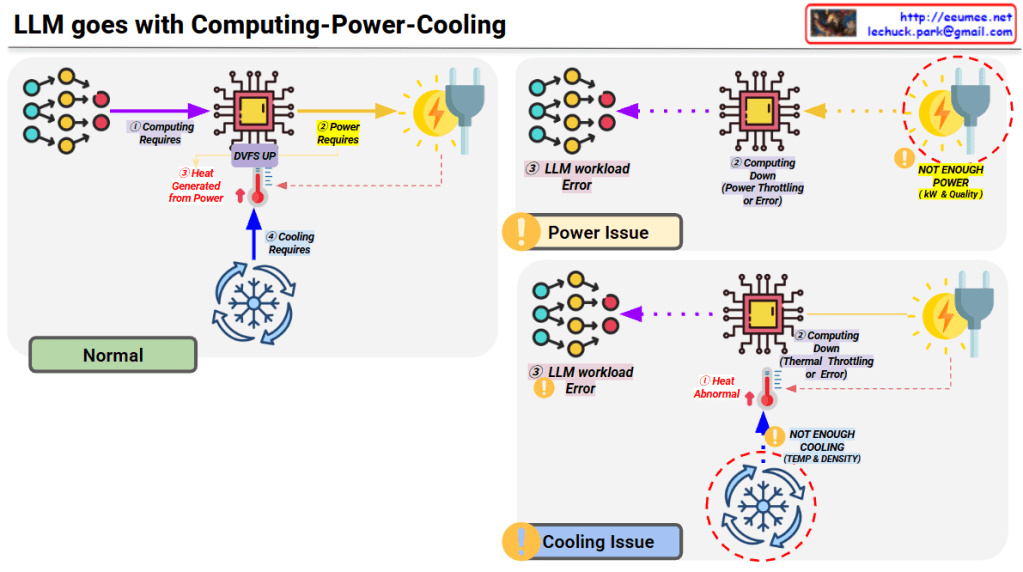
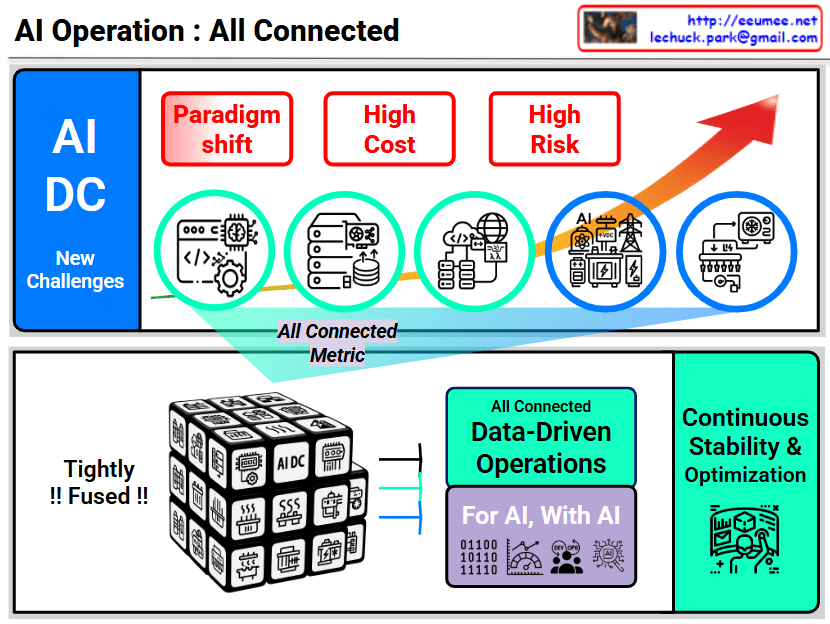
Interconnection Driven Design
This image outlines a technical approach to solving bottlenecks in High-Performance Computing (HPC) and AI/LLM infrastructure. It is categorized into three main rows, each progressing from a Problem to a Solution, and finally to a hardware-level Final Optimization.
1. Convergence of Scale-Up and Scale-Out
Focuses on resolving inefficiencies between server communication and GPU computation.
- Problem (IB Communication): The speed of inter-server connections (e.g., InfiniBand) creates a bottleneck for total system performance.
- Inefficiency (Streaming Multiprocessor): The GPU’s core computational units (SMs) waste resources handling network overhead instead of focusing on actual calculations.
- Solution (SM Offload): Communication tasks are delegated (offloaded) to dedicated coprocessors, allowing SMs to focus exclusively on computation.
- Final Optimization (Unified Network Adapter): Physically integrating intra-node and inter-node communication into a single Network Interface Card (NIC) to minimize data movement paths.
2. Bandwidth Contention & Latency
Addresses the limitations of data bandwidth and processing delays.
- Problem (KV Cache): Reusable token data for LLM inference frequently travels between the CPU and GPU, consuming significant bandwidth.
- Bottleneck (PCIe): The primary interconnect has limited bandwidth, leading to contention and performance degradation during traffic spikes.
- Solution (Traffic Class – TC): A prioritization mechanism (QoS) ensures urgent, latency-sensitive traffic is processed before less critical data.
- Final Optimization (I/O Die Chiplet Integration): Integrating network I/O directly alongside the GPU die bypasses PCIe entirely, eliminating contention and drastically reducing latency.
3. Node-Limited Routing
Optimizes data routing strategies for distributed neural networks.
- Key Tech (NVLink): A high-speed, intra-node GPU interconnect strategically used to maximize local data transfer.
- Context (Experts): Neural network modules (MoE – Mixture of Experts) are distributed across various nodes, requiring activation for specific tokens.
- Solution/Strategy (Minimize IB Cost): Reducing overhead by restricting slow inter-node usage (InfiniBand) to a single hop while distributing data internally via fast NVLink.
- Final Optimization (Node-Limited): Algorithms restrict the selection of “Experts” (modules) to a limited node group, reducing inter-node traffic and guaranteeing communication efficiency.
Summary
- Integration: The design overcomes system bottlenecks by physically unifying network adapters and integrating I/O dies directly with GPUs to bypass slow connections like PCIe.
- Offloading & Prioritization: It improves efficiency by offloading network tasks from GPU cores (SMs) and prioritizing urgent traffic (Traffic Class) to reduce latency.
- Routing Optimization: It utilizes “Node-Limited” routing strategies to maximize high-speed local connections (NVLink) and minimize slower inter-server communication in distributed AI models.
#InterconnectionDrivenDesign #AIInfrastructure #GPUOptimization #HPC #ChipletIntegration #NVLink #LatencyReduction #LLMHardware #infiniband
With Gemini