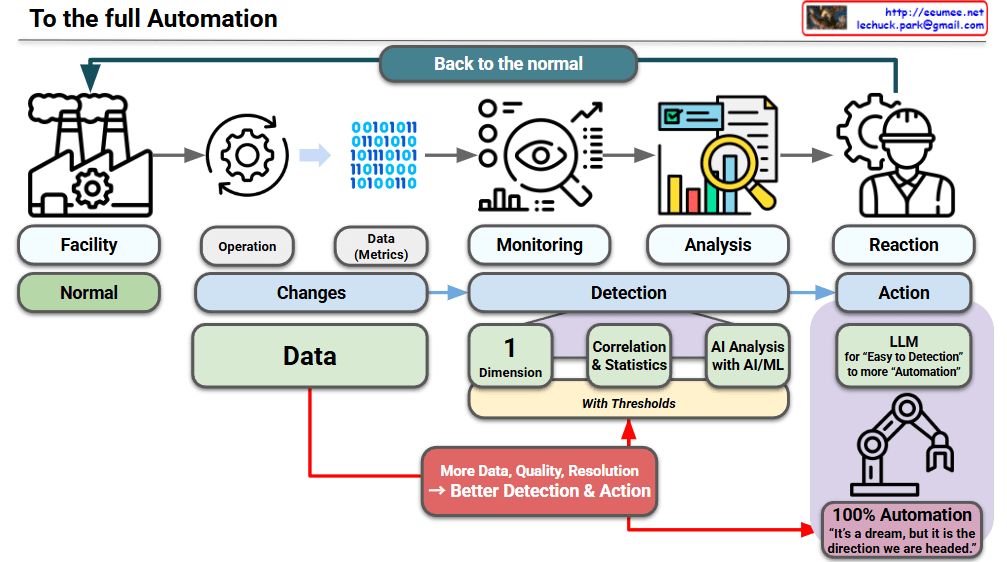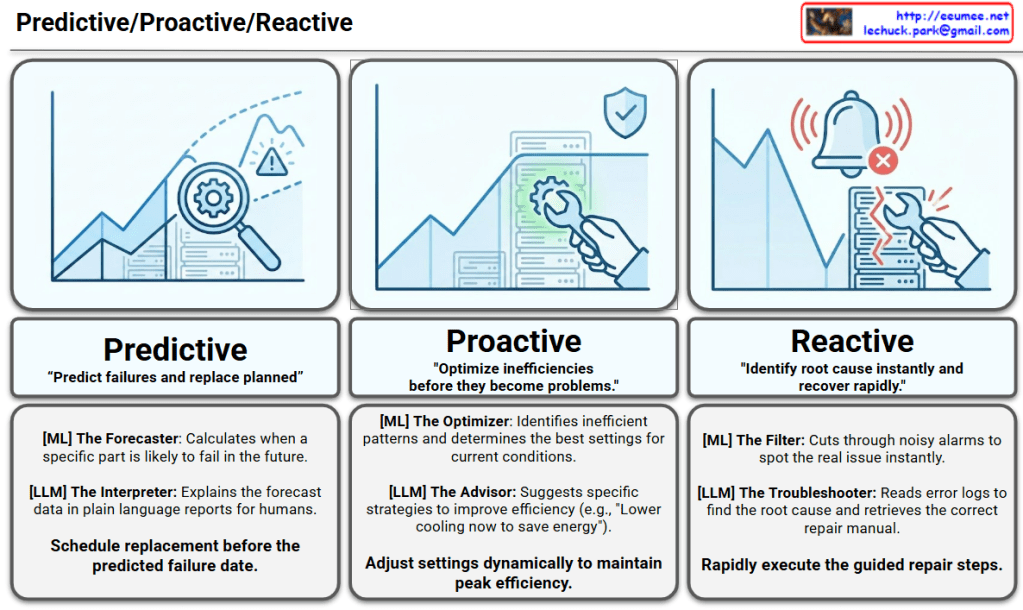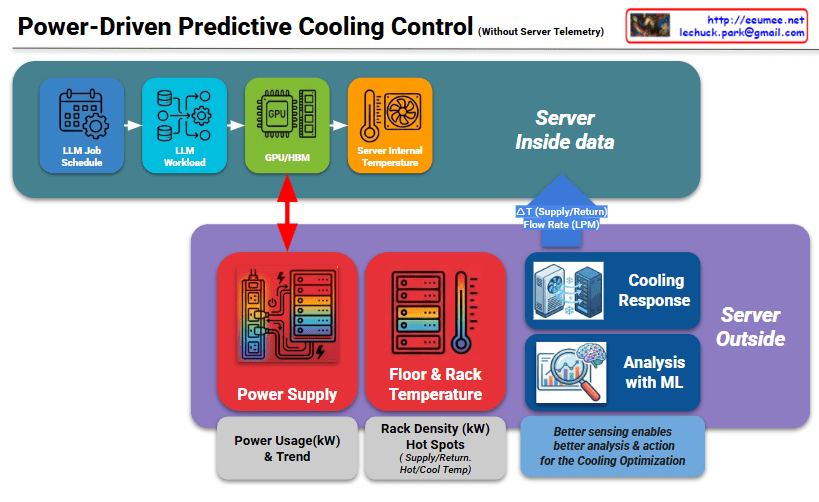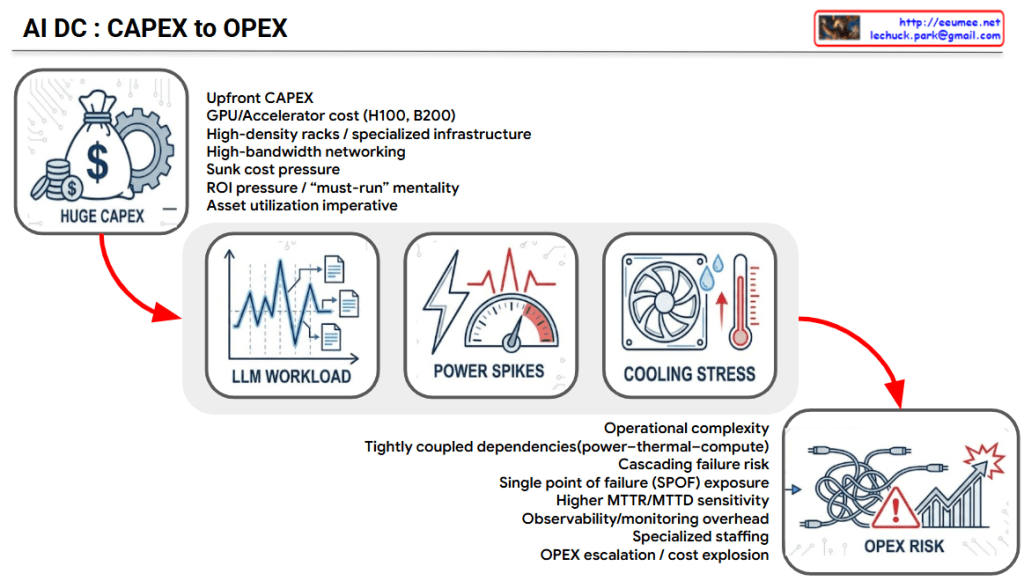
Thinking of an AI Data Center (DC) through the lens of a Rube Goldberg Machine is a brilliant way to visualize the “cascading complexity” of modern infrastructure. In this setup, every high-tech component acts as a trigger for the next, often leading to unpredictable and costly outcomes.
The AI DC Rube Goldberg Chain: From CAPEX to OPEX
1. The Heavy Trigger: Massive CAPEX
The machine starts with a massive “weighted ball”—the Upfront CAPEX.
- The Action: Billions are poured into H100/B200 GPUs and specialized high-density racks.
- The Consequence: This creates immense “Sunk Cost Pressure.” Because the investment is so high, there is a “must-run” mentality to ensure maximum asset utilization. You cannot afford to let these expensive chips sit idle.
2. The Erratic Spinner: LLM Workload Volatility
As the ball rolls, it hits an unpredictable spinner: the Workload.
- The Action: Unlike traditional steady-state cloud tasks, LLM workloads (training vs. inference) are highly “bursty”.
- The Consequence: The demand for compute fluctuates wildly and unpredictably, making it impossible to establish a smooth operational rhythm.
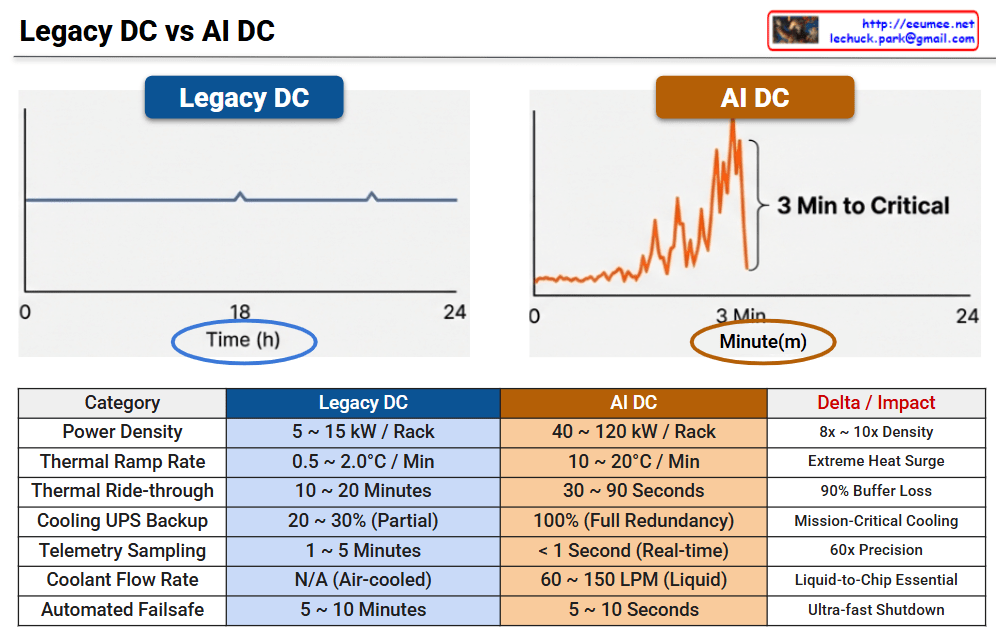
3. The Power Lever: Energy Spikes
The erratic workload flips a lever that controls the Power Grid.
- The Action: When the LLM workload spikes, the power draw follows instantly. This creates Power Spikes ($\Delta P$) that strain the electrical infrastructure.
- The Consequence: These spikes threaten grid stability and increase the sensitivity of Power Distribution Units (PDUs) and UPS systems.
4. The Thermal Valve: Cooling Stress
The surge in power generates intense heat, triggering the Cooling System.
- The Action: Heat is the literal byproduct of energy consumption. As power spikes, the temperature rises sharply, forcing cooling fans and liquid cooling loops into overdrive.
- The Consequence: This creates Cooling Stress. If the cooling cannot react as fast as the power spike, the system faces “Thermal Throttling,” which slows down the compute and ruins efficiency.
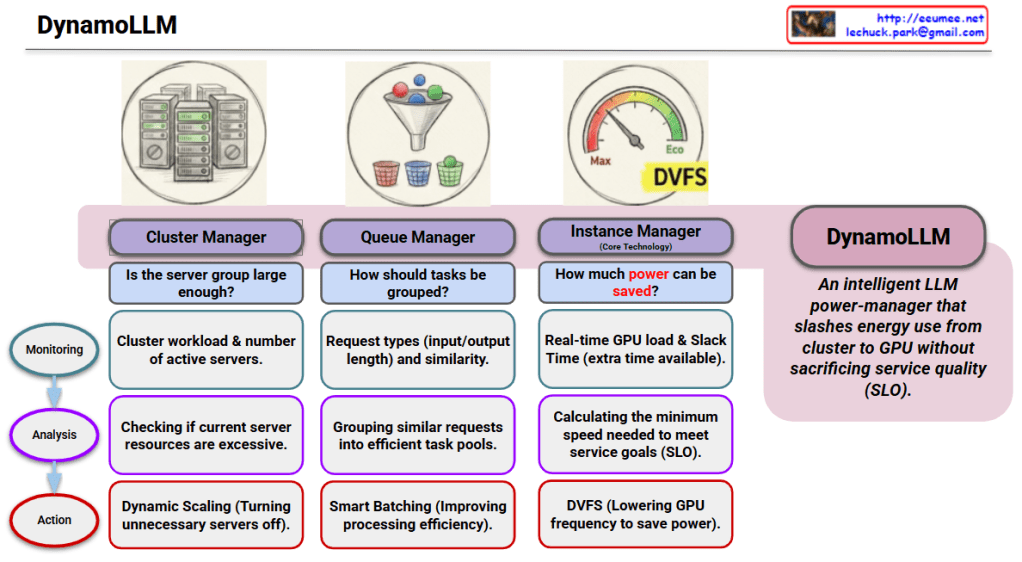
5. The Tangled Finish: Escalating OPEX Risk
Finally, all these moving parts lead to a messy, high-risk conclusion: Operational Complexity.
- The Action: Because power, thermal, and compute are “Tightly Coupled,” a failure in one area causes a Cascading Failure across the others.
- The Consequence: You now face a “Single Point of Failure” (SPOF) risk. Managing this requires specialized staffing and expensive observability tools, leading to an OPEX Explosion.
Summary
- Massive CAPEX creates a “must-run” pressure that forces GPUs to operate at high intensity to justify the investment.
- The interconnected volatility of workloads, power, and cooling creates a fragile “Rube Goldberg” chain where a single spike can cause a system-wide failure.
- This complexity shifts the financial burden from initial hardware costs to unpredictable OPEX, requiring expensive specialized management to prevent a total crash.
#AIDC #CAPEXtoOPEX #LLMWorkload #DataCenterManagement #OperationalRisk #InfrastructureComplexity #GPUComputing
With Gemini