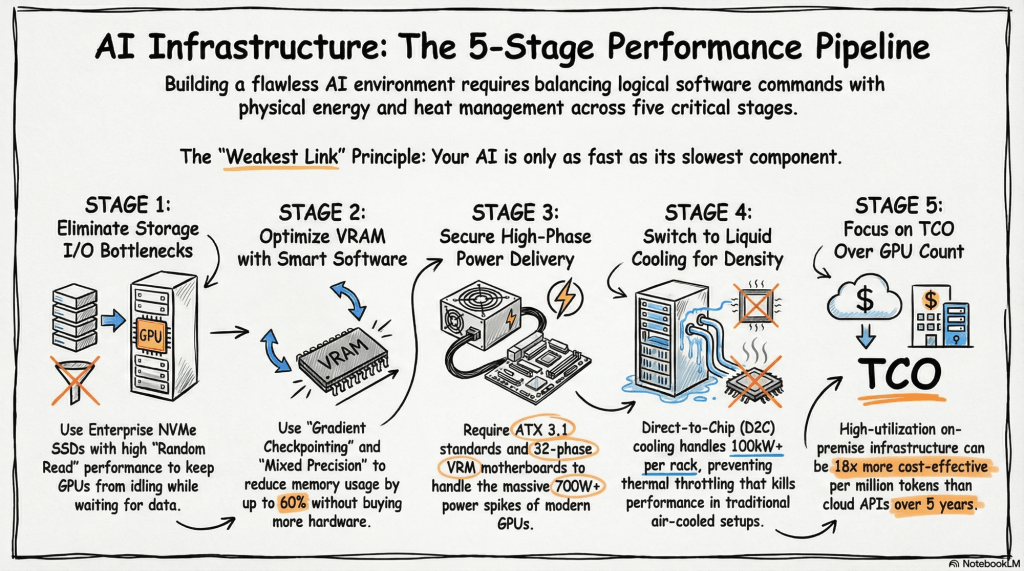
AI infrastructure pipeline
The Computing for the Fair Human Life.
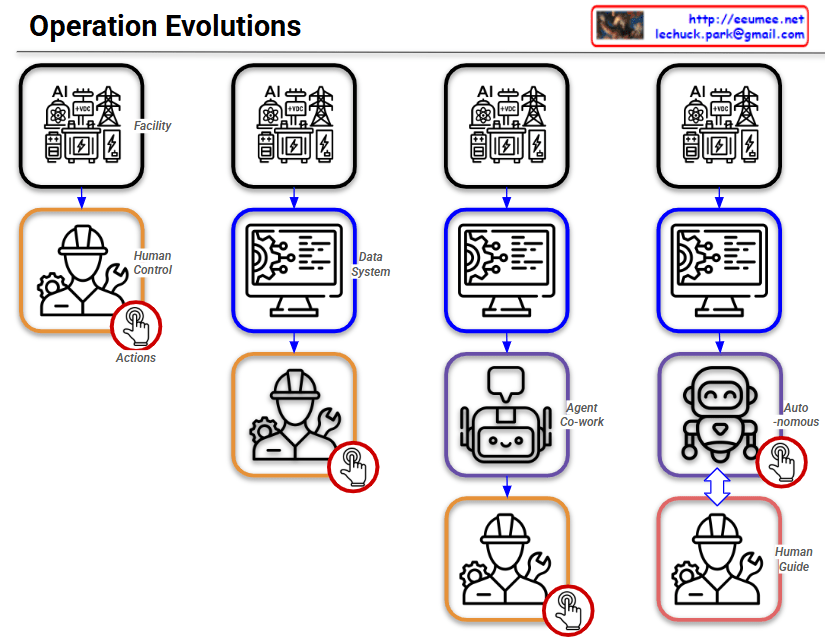
By following the red circle with the ‘Actions’ (clicking hand) icon, you can easily track how the control and operational authority shift throughout the four stages.
Summary:
This slide intuitively illustrates a paradigm shift in infrastructure operations: progressing from Direct Human Intervention ➡️ System-Assisted Cognition ➡️ AI-Assisted Operations (Co-work) ➡️ Fully Autonomous AI Control with Human Supervision.
#AIOps #AutonomousOperations #TechEvolution #DigitalTransformation #DataCenter #FacilityManagement #InfrastructureAutomation #SmartFacilities #AIAgents #FutureOfWork #HumanAndAI #Automation
with Gemini
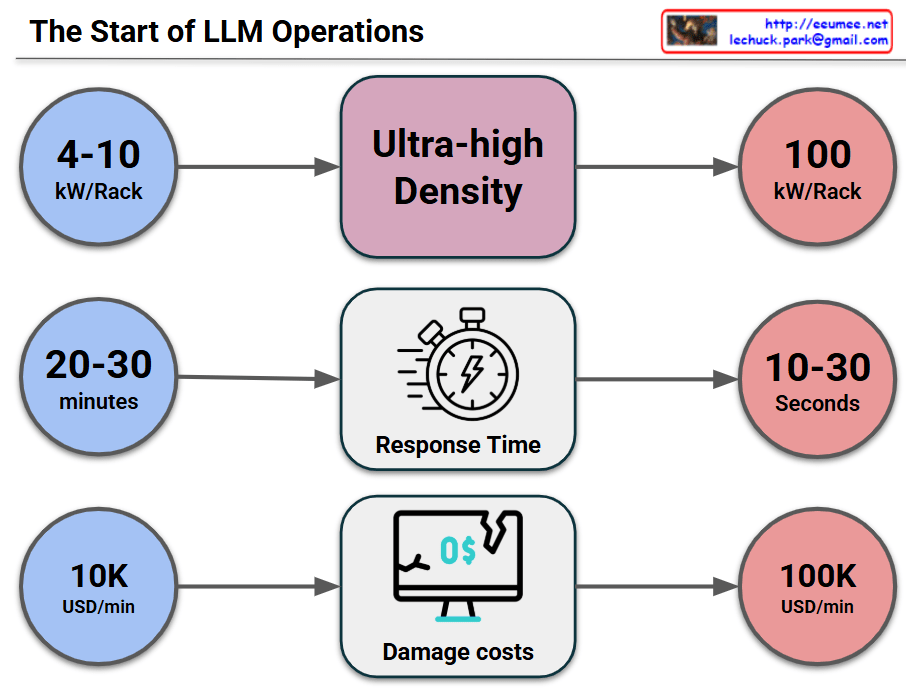
This image visually compares the critical changes and risks that occur when a data center or IT infrastructure transitions to an “Ultra-high Density” environment across three key metrics.
1. Surge in Power Density (Top Row)
2. Drastic Drop in Response Time (Middle Row)
3. Explosion of Damage Costs (Bottom Row)
The core message of this infographic is a strong warning: “In ultra-high density environments reaching 100kW per rack, the window for disaster response shrinks from minutes to mere seconds, while the financial loss per minute multiplies tenfold.” This perfectly illustrates why immediate, automated cooling and response systems (such as liquid cooling or AI-driven automation) are no longer optional, but mandatory for modern data centers.
#DataCenter#UltraHighDensity#HighDensityComputing#ITInfrastructure#Downtime#CostOfDowntime#RiskManagement
With Gemini
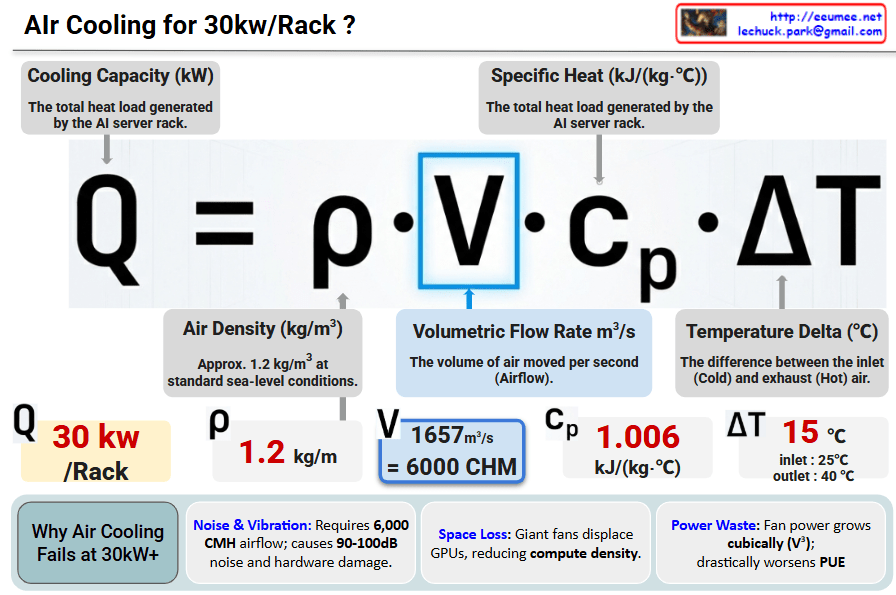
Conclusion: At 30kW/Rack, air cooling hits a physical and economic “wall”. Transitioning to Liquid Cooling is mandatory for next-generation AI Data Centers.
#AIDataCenter #LiquidCooling #ThermalManagement #30kWRack #DataCenterEfficiency #PUE #HighDensityComputing #GPUCooling
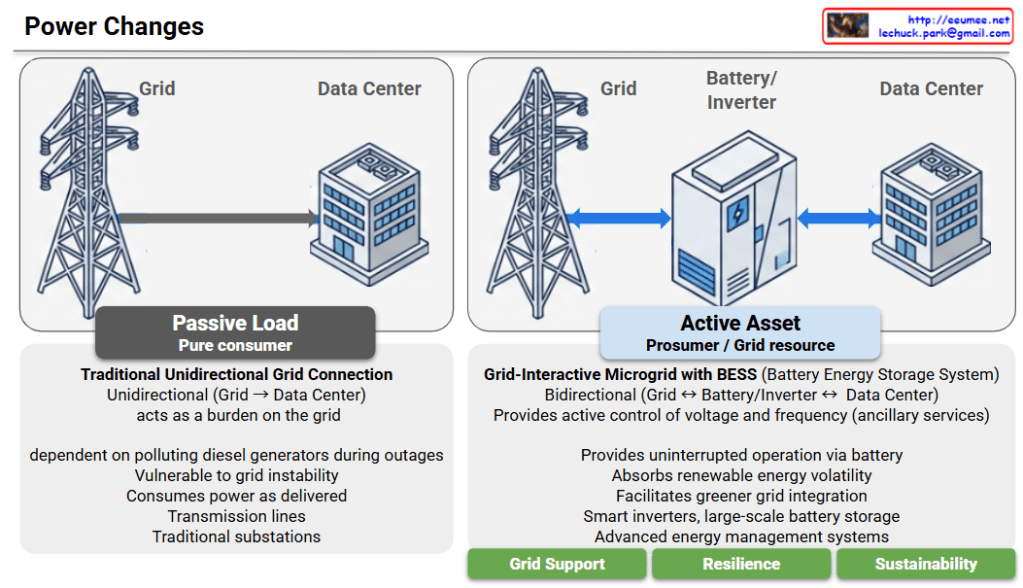
Power Architecture Evolution: From Passive Load to Active Asset
This diagram illustrates the critical evolution of data center power systems, highlighting the shift from a traditional “Passive Load” model to an “Active Asset” model. This transition is emerging as an essential power architecture and strategic direction for future AI Data Centers (AI DCs), which demand massive energy consumption and absolute operational stability.
1. AS-IS: Passive Load (Pure Consumer)
2. TO-BE: Active Asset (Prosumer / Grid Resource)
Conclusion: An Indispensable Power Direction for AI DCs
Rather than simply acting as facilities that drain massive amounts of electricity, modern data centers must evolve into grid-interactive assets. Given the exponential surge in power demands and the strict continuous operation requirements of AI workloads, adopting this “Active Asset” architecture with BESS and smart inverters is no longer just an eco-friendly alternative—it is an essential and inevitable power infrastructure direction for the successful deployment and scaling of AI Data Centers.
#AIDC #AIDataCenter #DataCenterInfrastructure #ESS #Inverter #GridInteractive
With Gemini
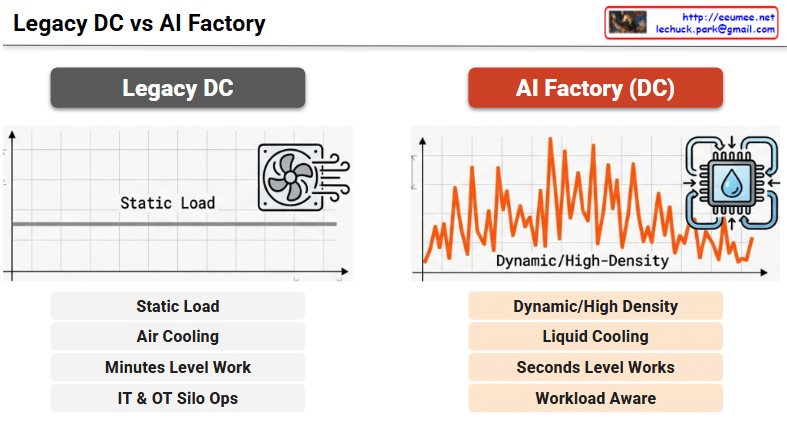
1. Legacy Data Center
2. AI Factory (DC)
#AIFactory #DataCenter #LiquidCooling #WorkloadAware #ITOTConvergence #HighFidelityData #Digitalization #AIInfrastructure
With Gemini
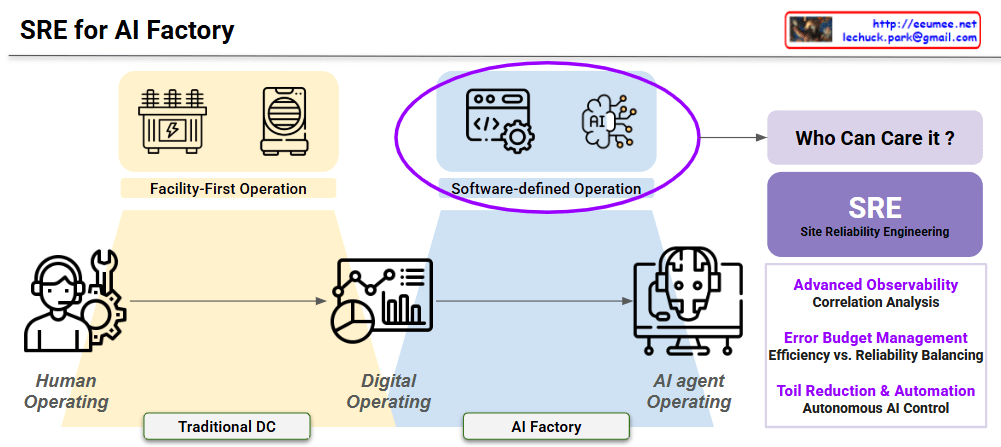
1. Operational Evolution (Bottom Flow)
2. Shift in Core Methodology (Top Transition)
3. The Solution: SRE (Site Reliability Engineering)
The image identifies SRE as the definitive answer to the question “Who can care for it?” by applying three technical pillars:
#AIFactory #SRE #SoftwareDefinedOperation #AIOps #DataCenterAutomation #Observability #InfrastructureAsCode
with Gemini
