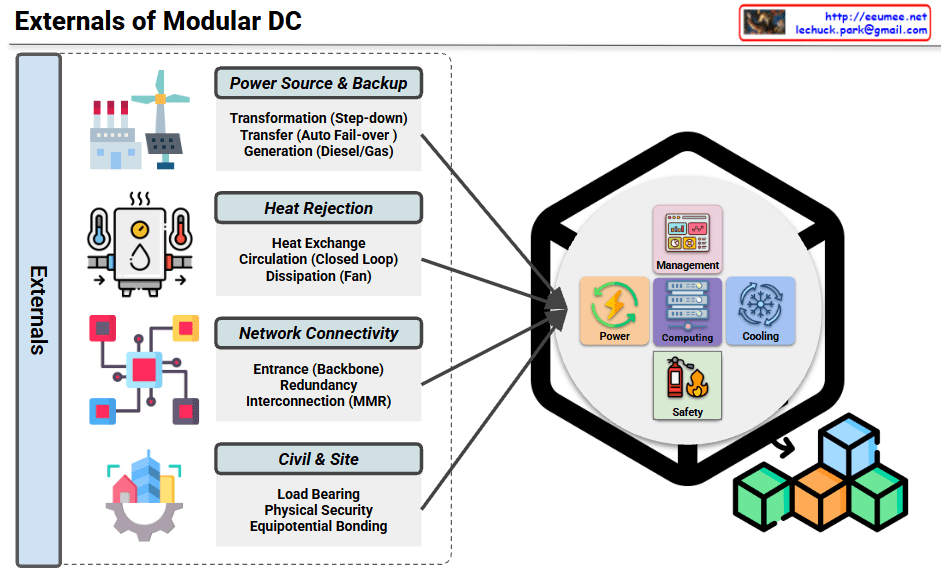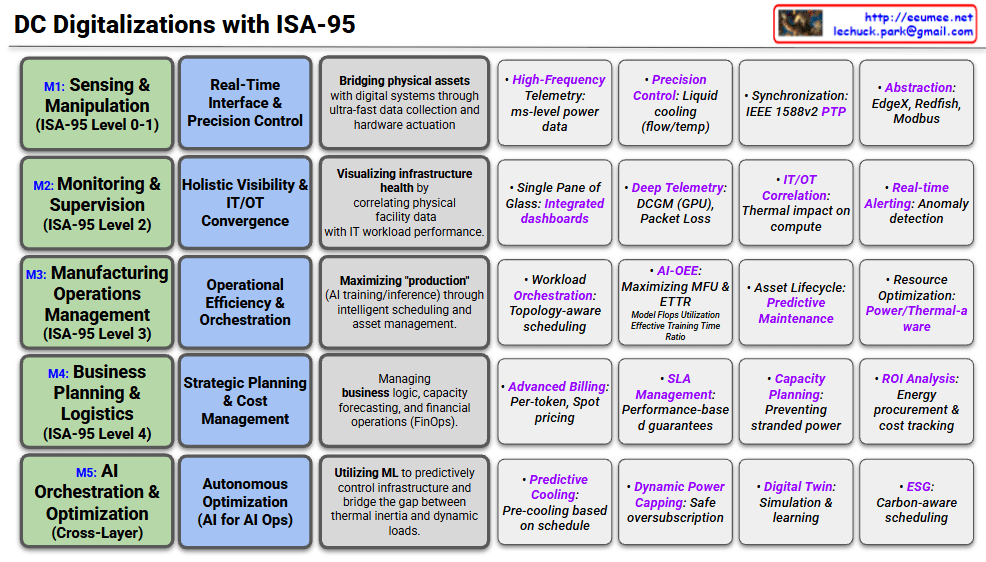
5-Layer Breakdown of DC Digitalization
M1: Sensing & Manipulation (ISA-95 Level 0-1)
- Focus: Bridging physical assets with digital systems.
- Key Activities: Ultra-fast data collection and hardware actuation.
- Examples: High-frequency power telemetry (ms-level), precision liquid cooling control, and PTP (Precision Time Protocol) for synchronization.
M2: Monitoring & Supervision (ISA-95 Level 2)
- Focus: Holistic visibility and IT/OT Convergence.
- Key Activities: Correlating physical facility health (cooling/power) with IT workload performance.
- Examples: Integrated dashboards (“Single Pane of Glass”), GPU telemetry via DCGM, and real-time anomaly detection.
M3: Manufacturing Operations Management (ISA-95 Level 3)
- Focus: Operational efficiency and workload orchestration.
- Key Activities: Maximizing “production” (AI output) through intelligent scheduling.
- Examples: Topology-aware scheduling, AI-OEE (maximizing Model Flops Utilization), and predictive maintenance for assets.
M4: Business Planning & Logistics (ISA-95 Level 4)
- Focus: Strategic planning, FinOps, and cost management.
- Key Activities: Managing business logic, forecasting capacity, and financial tracking.
- Examples: Per-token billing, SLA management with performance guarantees, and ROI analysis on energy procurement.
M5: AI Orchestration & Optimization (Cross-Layer)
- Focus: Autonomous optimization (AI for AI Ops).
- Key Activities: Using ML to predictively control infrastructure and bridge the gap between thermal inertia and dynamic loads.
- Examples: Predictive cooling (cooling down before a heavy job starts), Digital Twins, and Carbon-aware scheduling (ESG).
Summary of Core Concepts
- IT/OT Convergence: Integrating Information Technology (servers/software) with Operational Technology (power/cooling).
- AI-OEE: Adapting the “Overall Equipment Effectiveness” metric from manufacturing to measure how efficiently a DC produces AI models.
- Predictive Control: Moving from reactive monitoring to proactive, AI-driven management of power and heat.
#DataCenter #DigitalTransformation #ISA95 #AIOps #SmartFactory #ITOTConvergence #SustainableIT #GPUOrchestration #FinOps #LiquidCooling
With Gemini