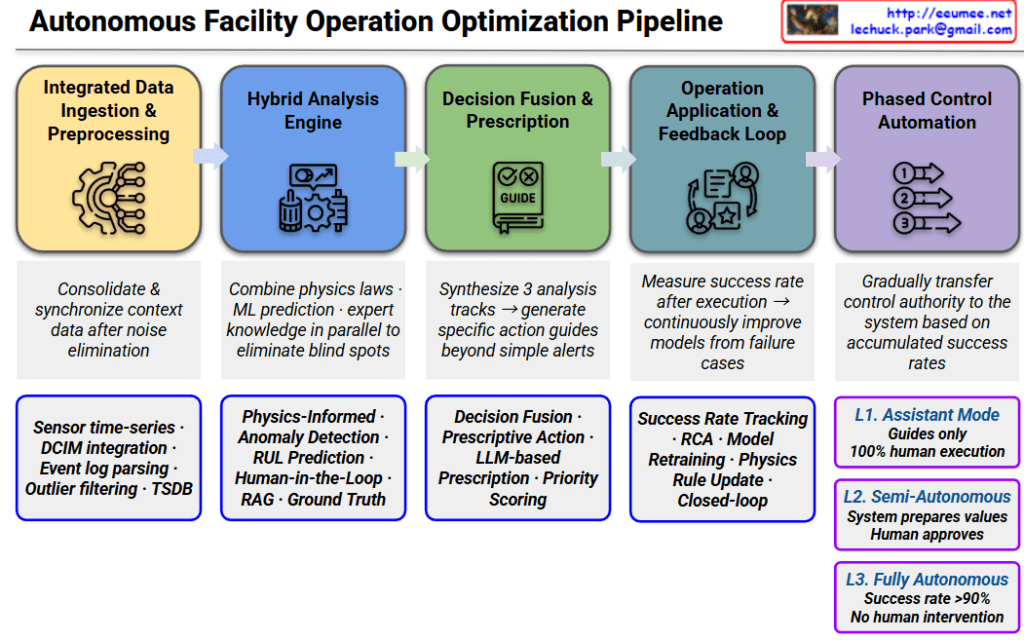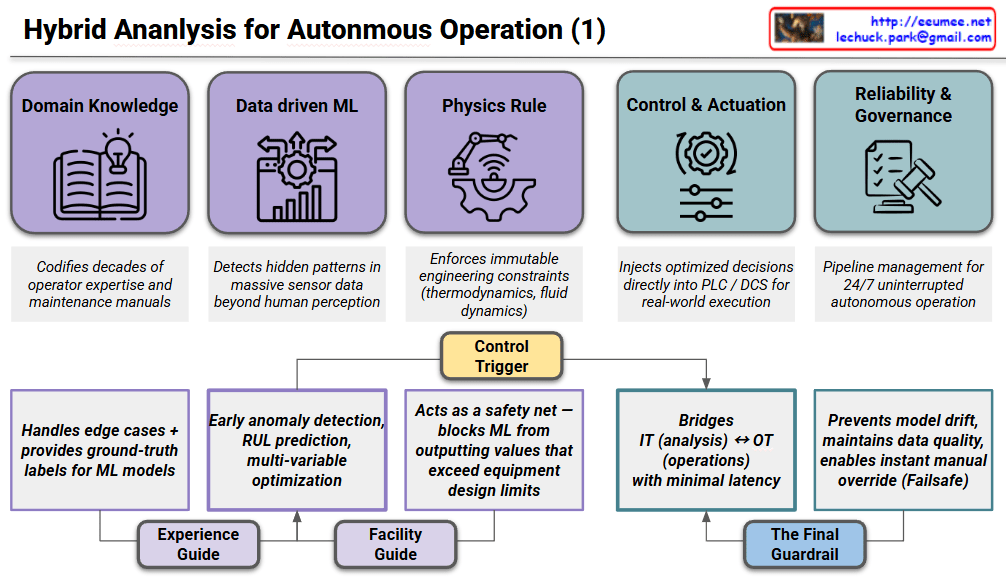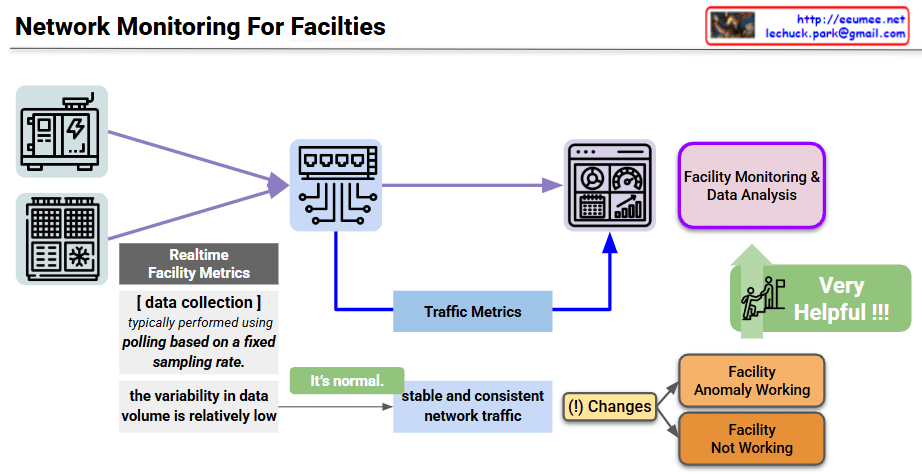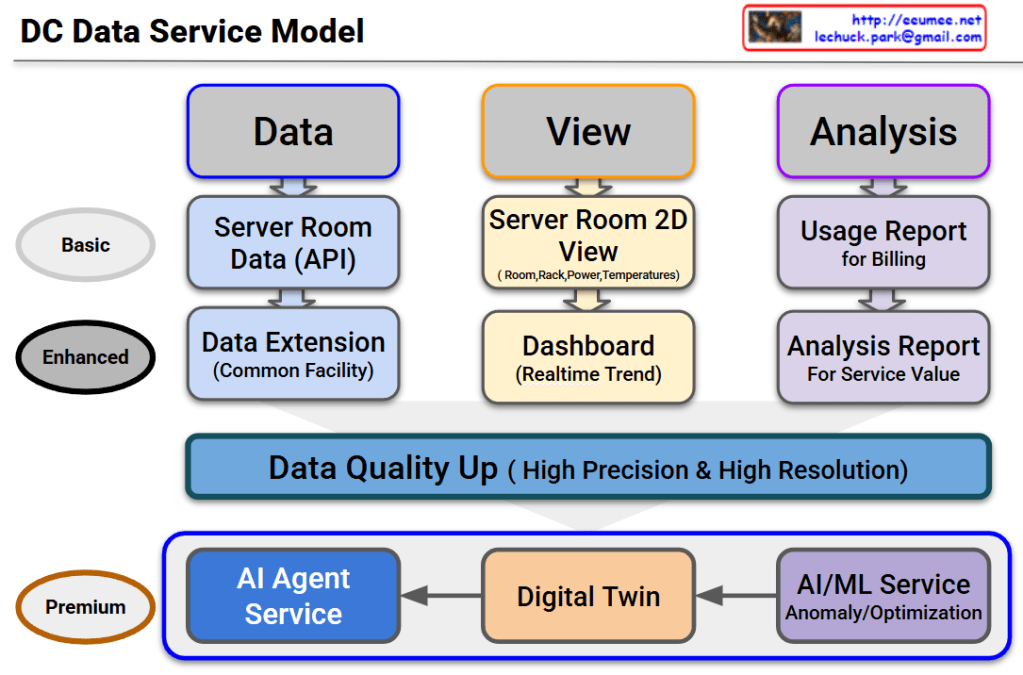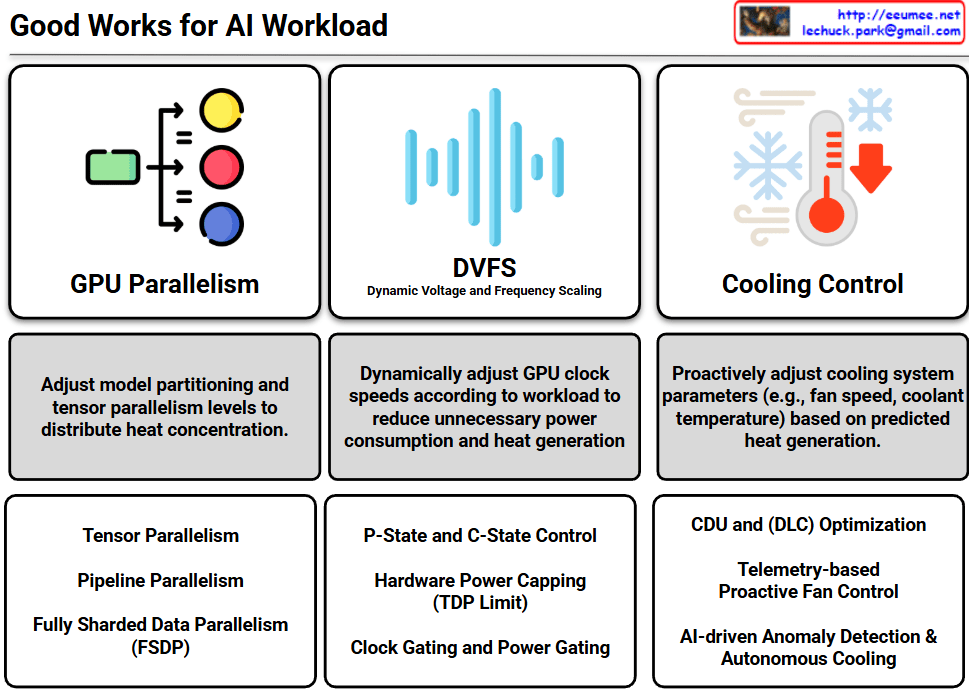
The infographic outlines a comprehensive strategy for optimizing AI workloads by balancing computational performance with power efficiency and thermal management.
1. GPU Parallelism
This section focuses on distributing the computational load to prevent “hot spots” (heat concentration) within the hardware.
- Core Strategy: Adjusting model partitioning and tensor parallelism levels to balance the thermal load across multiple GPUs.
- Key Techniques: * Tensor Parallelism: Splitting individual tensors across devices.
- Pipeline Parallelism: Distributing different layers of a model across various GPUs.
- FSDP (Fully Sharded Data Parallelism): Sharding model states to minimize memory overhead while maintaining high throughput.
2. DVFS (Dynamic Voltage and Frequency Scaling)
This represents the hardware-level power management used to reduce energy waste.
- Core Strategy: Dynamically adjusting GPU clock speeds and voltages based on the real-time workload to minimize unnecessary heat generation.
- Key Techniques:
- P-State and C-State Control: Managing active performance and idle power states.
- Hardware Power Capping (TDP Limit): Setting strict thermal design power limits to prevent overheating.
- Clock/Power Gating: Shutting down power to inactive portions of the chip.
3. Cooling Control
This shifts the focus from reactive cooling to proactive and autonomous thermal infrastructure management.
- Core Strategy: Pre-emptively adjusting cooling parameters (fan speeds, coolant temperatures) based on predicted heat generation from incoming workloads.
- Key Techniques:
- CDU and DLC Optimization: Maximizing the efficiency of Coolant Distribution Units and Direct Liquid Cooling systems.
- Telemetry-based Proactive Control: Using real-time data to adjust infrastructure before temperatures spike.
- AI-driven Autonomous Cooling: Utilizing AI for anomaly detection and self-regulating thermal environments.
#AIDataCenter #GPUOptimization #LiquidCooling #AIOps #EnergyEfficiency #ParallelComputing #SustainableAI #ThermalManagement #HPC #DeepLearningInfrastructure
With Gemini