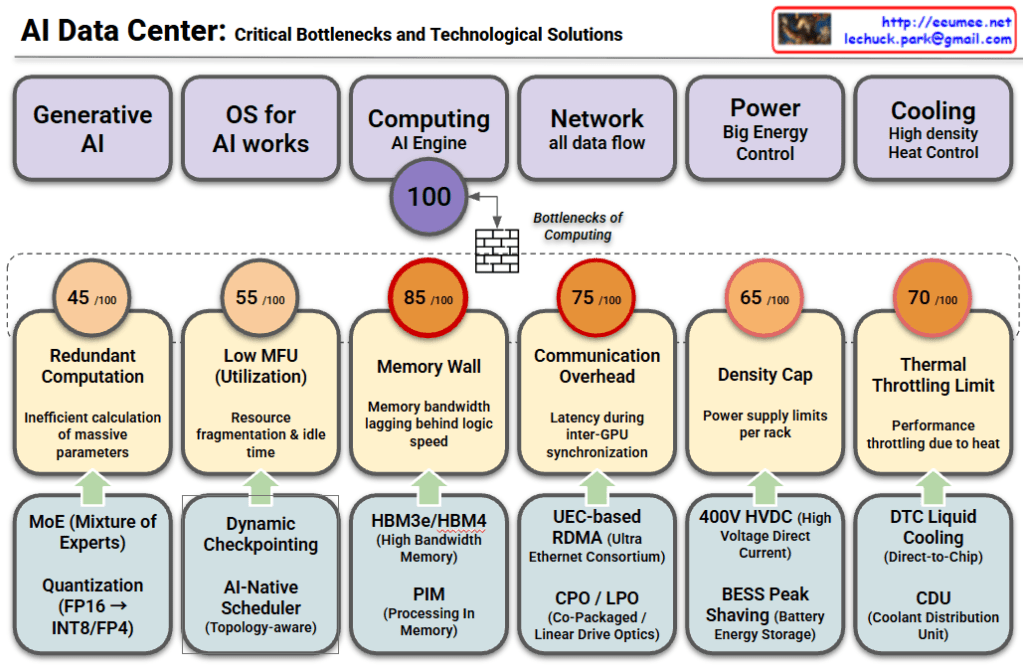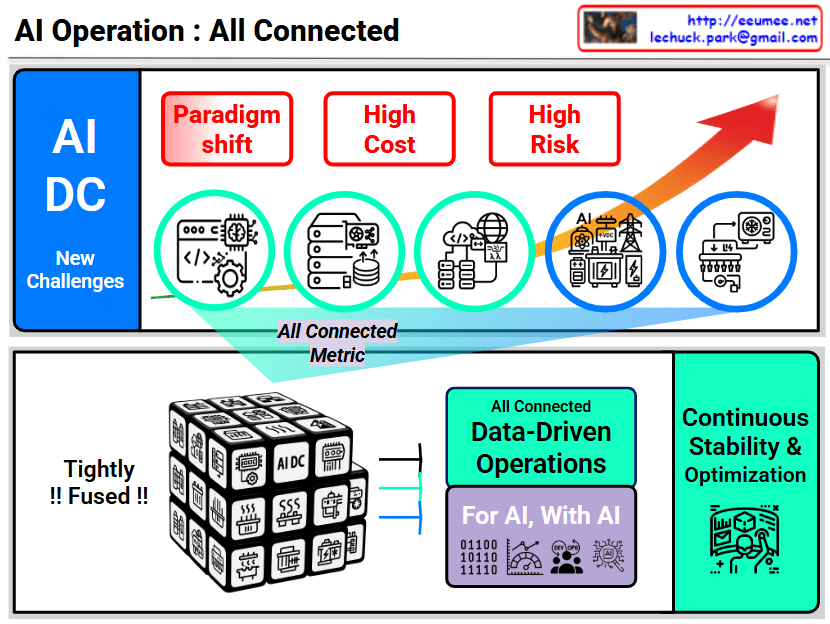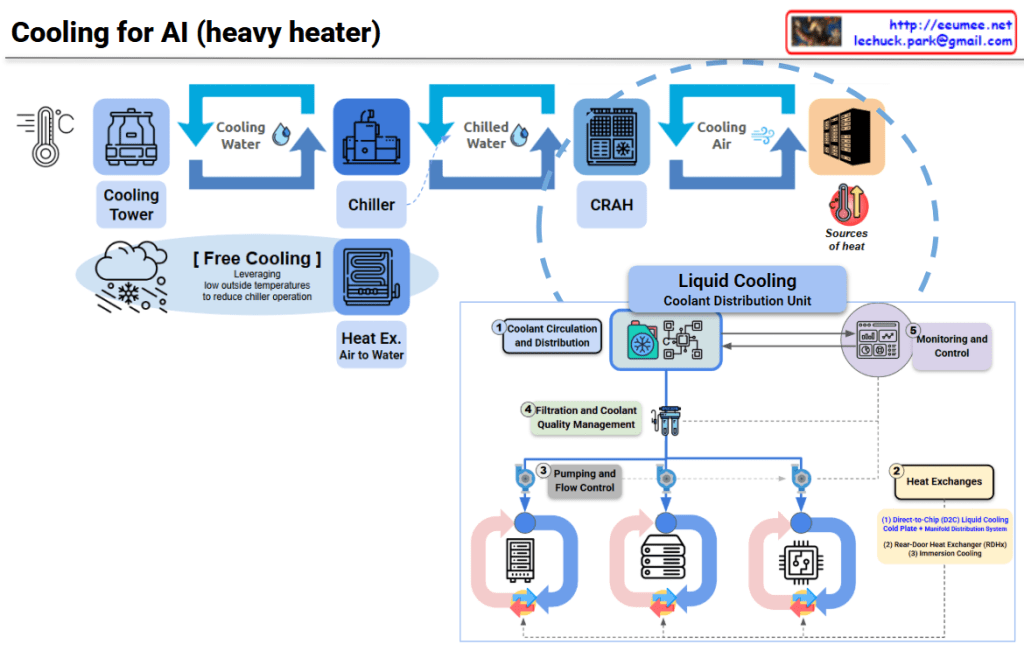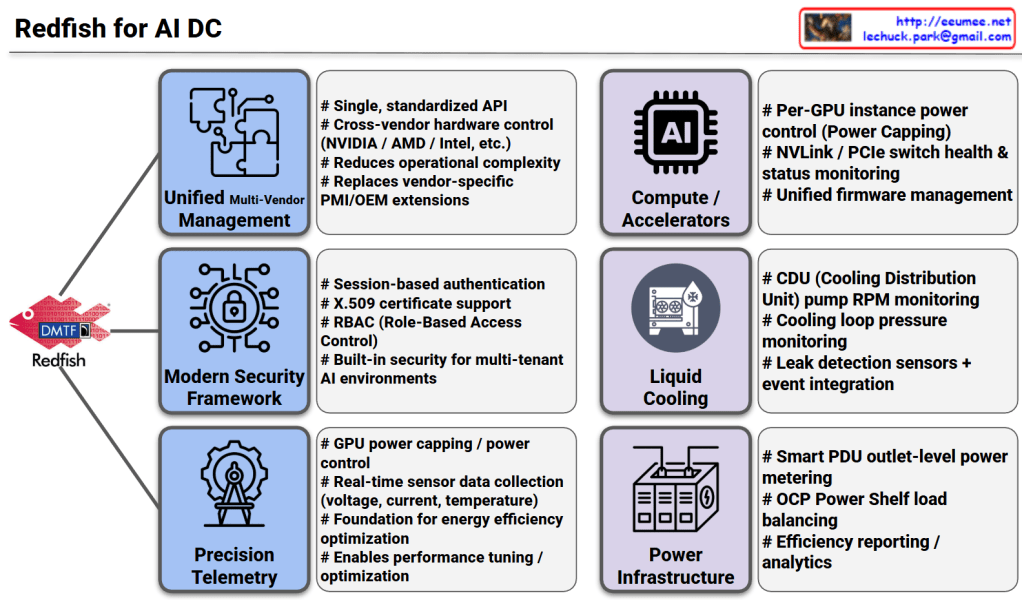
This image illustrates the pivotal role of the Redfish API (developed by DMTF) as the standardized management backbone for modern AI Data Centers (AI DC). As AI workloads demand unprecedented levels of power and cooling, Redfish moves beyond traditional server management to provide a unified framework for the entire infrastructure stack.
1. Management & Security Framework (Left Column)
- Unified Multi-Vendor Management:
- Acts as a single, standardized API to manage diverse hardware from different vendors (NVIDIA, AMD, Intel, etc.).
- It reduces operational complexity by replacing fragmented, vendor-specific IPMI or OEM extensions with a consistent interface.
- Modern Security Framework:
- Designed for multi-tenant AI environments where security is paramount.
- Supports robust protocols like session-based authentication, X.509 certificates, and RBAC (Role-Based Access Control) to ensure only authorized entities can modify critical infrastructure.
- Precision Telemetry:
- Provides high-granularity, real-time data collection for voltage, current, and temperature.
- This serves as the foundation for energy efficiency optimization and fine-tuning performance based on real-time hardware health.
2. Infrastructure & Hardware Control (Right Column)
- Compute / Accelerators:
- Enables per-GPU instance power capping, allowing operators to limit power consumption at a granular level.
- Monitors the health of high-speed interconnects like NVLink and PCIe switches, and simplifies firmware lifecycle management across the cluster.
- Liquid Cooling:
- As AI chips run hotter, Redfish integrates with CDU (Cooling Distribution Unit) systems to monitor pump RPM and loop pressure.
- It includes critical safety features like leak detection sensors and integrated event handling to prevent hardware damage.
- Power Infrastructure:
- Extends management to the rack level, including Smart PDU outlet metering and OCP (Open Compute Project) Power Shelf load balancing.
- Facilitates advanced efficiency analytics to drive down PUE (Power Usage Effectiveness).
Summary
For an AI DC Optimization Architect, Redfish is the essential “language” that enables Software-Defined Infrastructure. By moving away from manual, siloed hardware management and toward this API-driven approach, data centers can achieve the extreme automation required to shift OPEX structures predominantly toward electricity costs rather than labor.
#AIDataCenter #RedfishAPI #DMTF #DataCenterInfrastructure #GPUComputing #LiquidCooling #SustainableIT #SmartPDU #OCP #InfrastructureAutomation #TechArchitecture #EnergyEfficiency
With Gemini