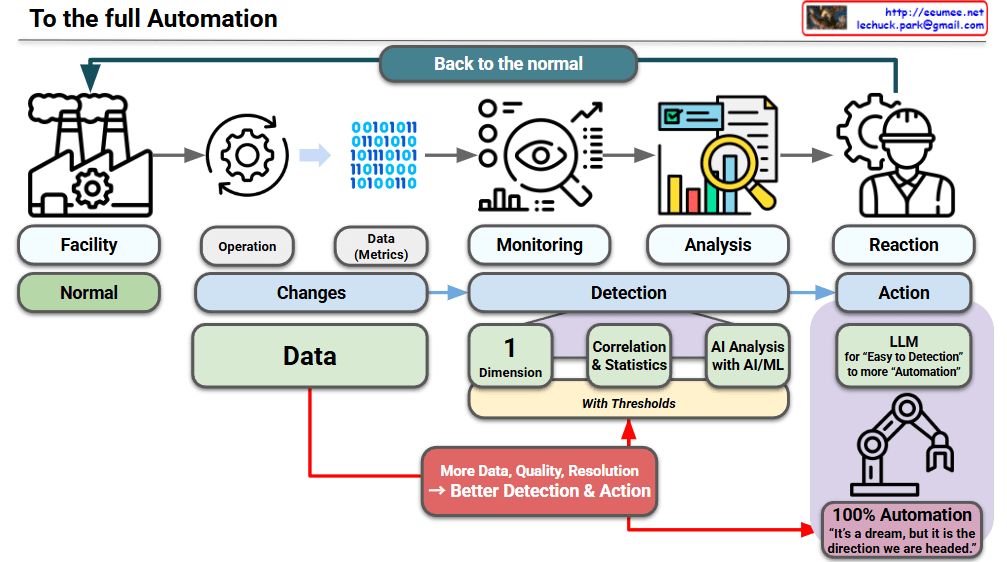
This visual emphasizes the critical role of high-quality data as the engine driving the transition from human-led reactions to fully autonomous operations. This roadmap illustrates how increasing data resolution directly enhances detection and automated actions.
Comprehensive Analysis of the Updated Roadmap
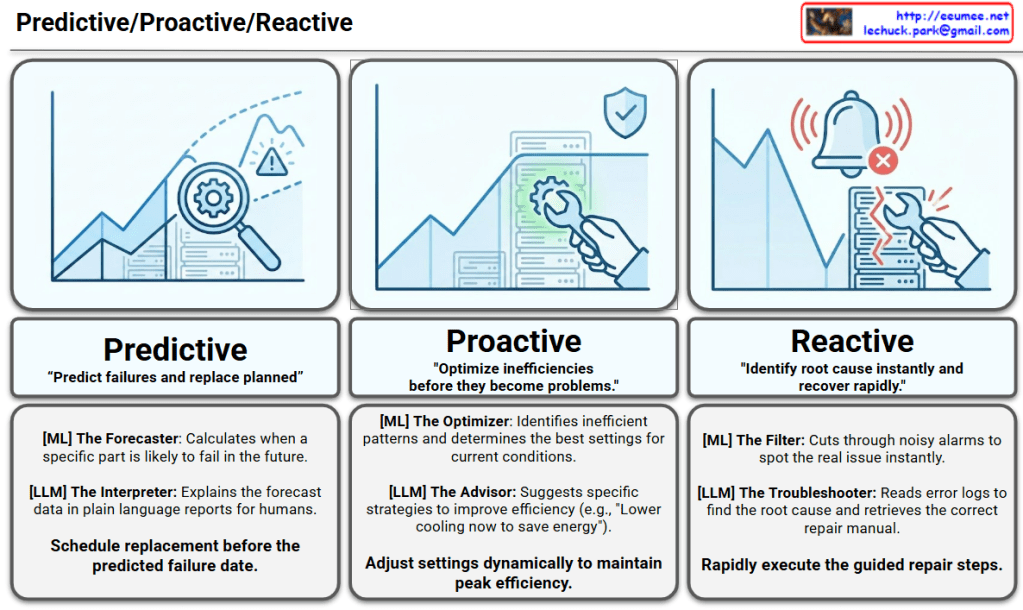
1. The Standard Operational Loop
The top flow describes the current state of industrial maintenance:
- Facility (Normal): The baseline state where everything functions correctly.
- Operation (Changes) & Data: Any deviation in operation produces data metrics.
- Monitoring & Analysis: The system observes these metrics to identify anomalies.
- Reaction: Currently, a human operator (the worker icon) must intervene to bring the system “Back to the normal”.
2. The Data Engine
The most significant addition is the emphasized Data block and its impact on the automation cycle:
- Quality and Resolution: The diagram highlights that “More Data, Quality, Resolution” are the foundation.
- Optimization Path: This high-quality data feeds directly into the “Detection” layer and the final “100% Automation” goal, stating that better data leads to “Better Detection & Action”.
3. Evolution of Detection Layers
Detection matures through three distinct levels, all governed by specific thresholds:
- 1 Dimension: Basic monitoring of single variables.
- Correlation & Statistics: Analyzing relationships between different data points.
- AI Analysis with AI/ML: Utilizing advanced machine learning for complex pattern recognition.
4. The Goal: 100% Automation
The final stage replaces human “Reaction” with autonomous “Action”:
- LLM Integration: Large Language Models are utilized to bridge the gap from “Easy Detection” to complex “Automation”.
- The Vision: The process culminates in 100% Automation, where a robotic system handles the recovery loop independently.
- The Philosophy: It concludes with the defining quote: “It’s a dream, but it is the direction we are headed”.
Summary
- The roadmap evolves from human intervention (Reaction) to autonomous execution (Action) powered by AI and LLMs.
- High-resolution data quality is identified as the core driver that enables more accurate detection and reliable automated outcomes.
- The ultimate objective is a self-correcting system that returns to a “Normal” state without manual effort.
#HyperAutomation #DataQuality #IndustrialAI #SmartManufacturing #LLM #DigitalTwin #AutonomousOperations #AIOp
With Gemini