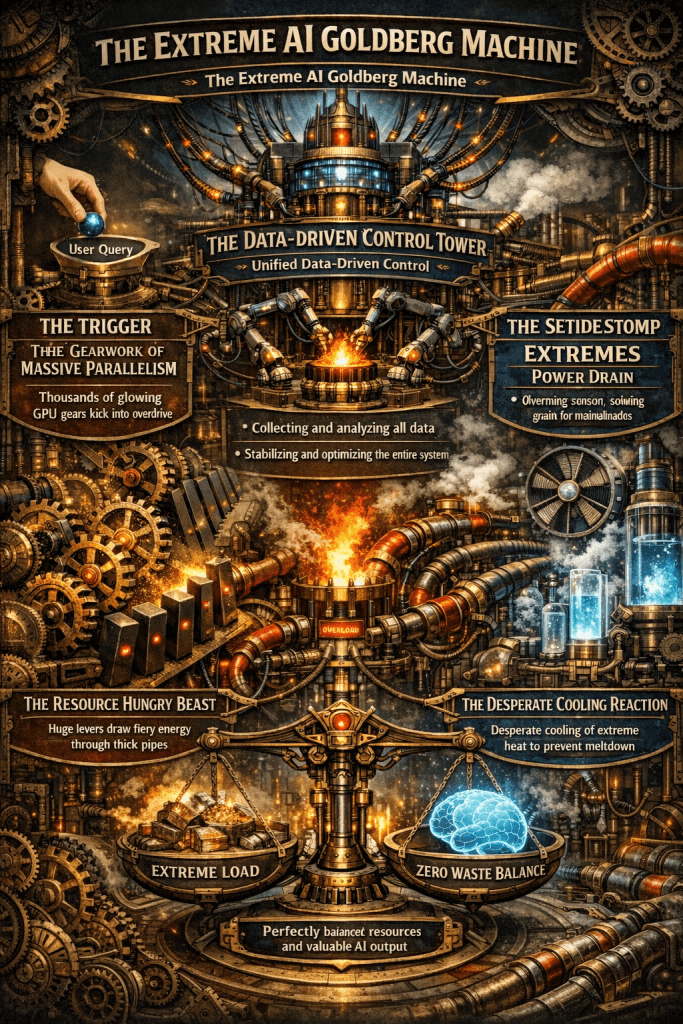
A single AI response triggers a massive chain reaction of compute, power, and cooling.
Only unified, data-driven control can stabilize this fragile system and eliminate waste.
The Computing for the Fair Human Life.
A single AI response triggers a massive chain reaction of compute, power, and cooling.
Only unified, data-driven control can stabilize this fragile system and eliminate waste.
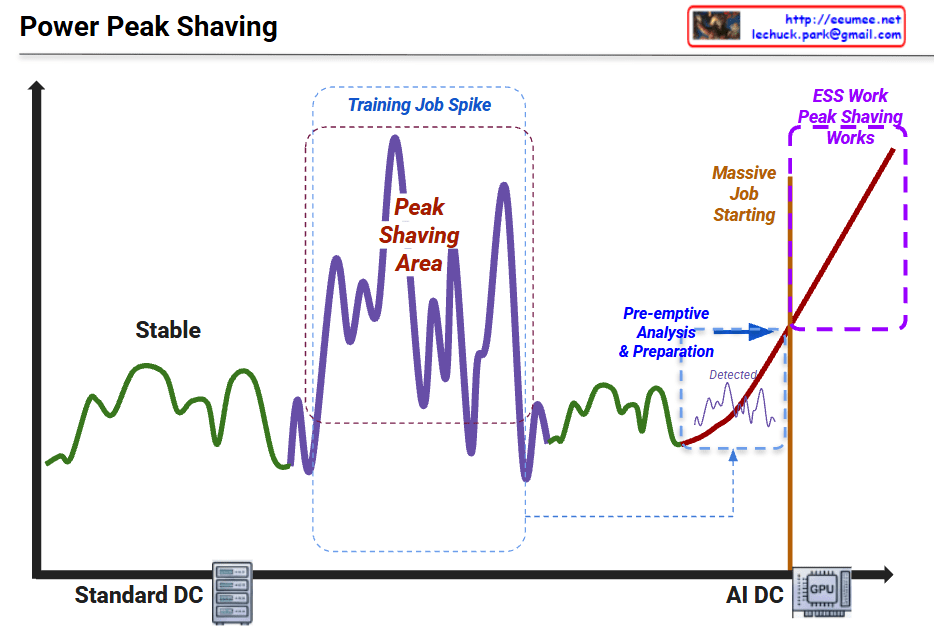
This graph illustrates the shift in power consumption patterns from traditional data centers to AI-driven data centers and the necessity of “Peak Shaving” strategies.
1. Standard DC (Green Line – Left)
2. Training Job Spike (Purple Line – Middle)
3. AI DC & Massive Job Starting (Red Line – Right)
4. ESS Work & Peak Shaving (Purple Dotted Box – Top Right)
#DataCenter #AI #PeakShaving #EnergyStorage #ESS #GPU #PowerManagement #SmartGrid #TechInfrastructure #AIDC #EnergyEfficiency
with Gemini
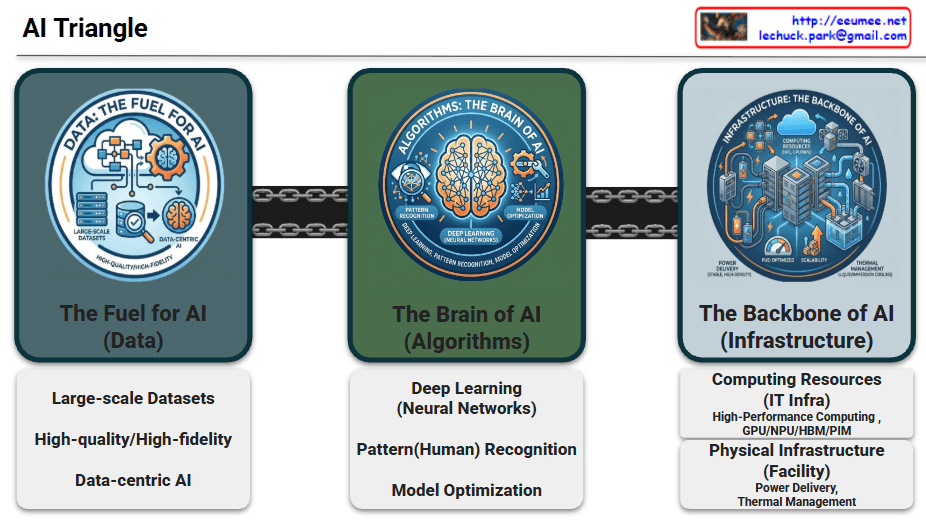
Data serves as the essential raw material that determines the intelligence and accuracy of AI models.
Algorithms provide the logical framework and mathematical structures that allow machines to learn from data.
The physical and digital foundation that enables massive computations and ensures system stability.
#AITriangle #AIInfrastructure #DataCenter #DeepLearning #GPU #LiquidCooling #DataCentric #Sustainability #PUE #TechArchitecture
With Gemini

This diagram illustrates the flow of Power and Cooling changes throughout the execution stages of an AI workload. It divides the process into five phases, explaining how data center infrastructure (Power, Cooling) reacts and responds from the start to the completion of an AI job.
Here are the key details for each phase:
This diagram demonstrates that managing AI infrastructure goes beyond simply “running a job.” It requires active control of the infrastructure (e.g., PreCooling, Throttling, Ramp-down) to handle the specific characteristics of AI workloads, such as rapid power spikes and high heat generation.
Phase 1 (PreCooling) for proactive heat management and Phase 4 (Throttling) for hardware protection are the core mechanisms determining the stability and efficiency of an AI Data Center.
#AI #ArtificialIntelligence #GPU #HPC #DataCenter #AIInfrastructure #DataCenterOps #GreenIT #SustainableTech #SmartCooling #PowerEfficiency #PowerManagement #ThermalEngineering #TDP #DVFS #Semiconductor #SystemArchitecture #ITOperations
With Gemini

This diagram illustrates how data centers are transforming as they enter the AI era.
The top section shows major technology revolutions and their timelines:
Conventional data centers consisted of the following core components:
These were designed as relatively independent layers.
With the introduction of AI (especially LLMs), data centers require specialized infrastructure:
The circular connection in the center of the diagram represents the most critical feature of AI data centers:
Unlike traditional data centers, in AI data centers:
These elements must be closely integrated in design, and optimizing just one element cannot guarantee overall system performance.
AI workloads require moving beyond the traditional layer-by-layer independent design approach of conventional data centers, demanding that computing-network-power-cooling be designed as one integrated system. This demonstrates that a holistic approach is essential when building AI data centers.
AI data centers fundamentally differ from traditional data centers through the tight integration of computing, networking, power, and cooling systems. GPU-based AI workloads create unprecedented power density and heat generation, requiring liquid cooling and HVDC power systems. Success in AI infrastructure demands holistic design where all components are co-optimized rather than independently engineered.
#AIDataCenter #DataCenterEvolution #GPUInfrastructure #LiquidCooling #AIComputing #LLM #DataCenterDesign #HighPerformanceComputing #AIInfrastructure #HVDC #HolisticDesign #CloudComputing #DataCenterCooling #AIWorkloads #FutureOfDataCenters
With Claude

OCP CDU (Deschutes) Standard Overview
The provided visual summarizes the key performance metrics of the CDU (Cooling Distribution Unit) that adheres to the OCP (Open Compute Project) ‘Project Deschutes’ specification. This CDU is designed for high-performance computing environments, particularly for massive-scale liquid cooling of AI/ML workloads.
Cooling has a direct and significant impact on GPU performance and stability. Because GPUs are highly sensitive to heat, if they are not maintained within an optimal temperature range, they will automatically reduce their performance through a process called thermal throttling to prevent damage.
The ‘Project Deschutes’ CDU is engineered to prevent this by handling a massive thermal load of 2,000 kW with a powerful 500 GPM flow rate and a low approach temperature of ≤3∘C. This robust cooling capability ensures that GPUs can operate at their maximum potential without being limited by heat, which is essential for maximizing performance in demanding AI workloads.
with Gemini

Before: CPU [Memory] ←PCIe→ [Memory] GPU (Separated)
After: CPU ←CXL→ GPU → Shared Memory Pool (Unified)
| Metric | PCIe 4.0 | CXL 2.0 | Improvement |
|---|---|---|---|
| Bandwidth | 64 GB/s | 128 GB/s | 2x |
| Latency | 1-2μs | 200-400ns | 5-10x |
| Memory Copy | Required | Eliminated | Complete Removal |
AI/ML: 90% reduction in training data loading time, larger model processing capability
HPC: Real-time large dataset exchange, memory constraint elimination
Cloud: Maximized server resource efficiency through memory pooling
The key technical improvements of CXL – Zero-Copy sharing and hardware-based cache coherency – are emphasized as the most revolutionary aspects that fundamentally solve the traditional PCIe bottlenecks.
With Claude
