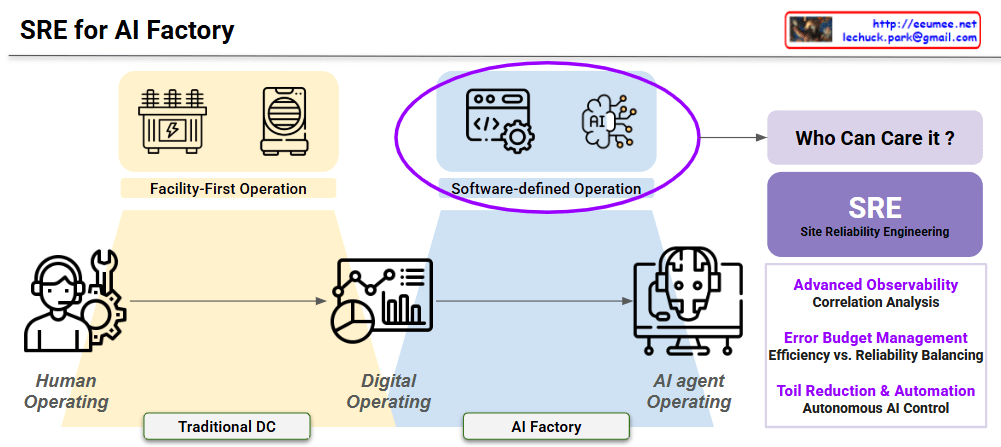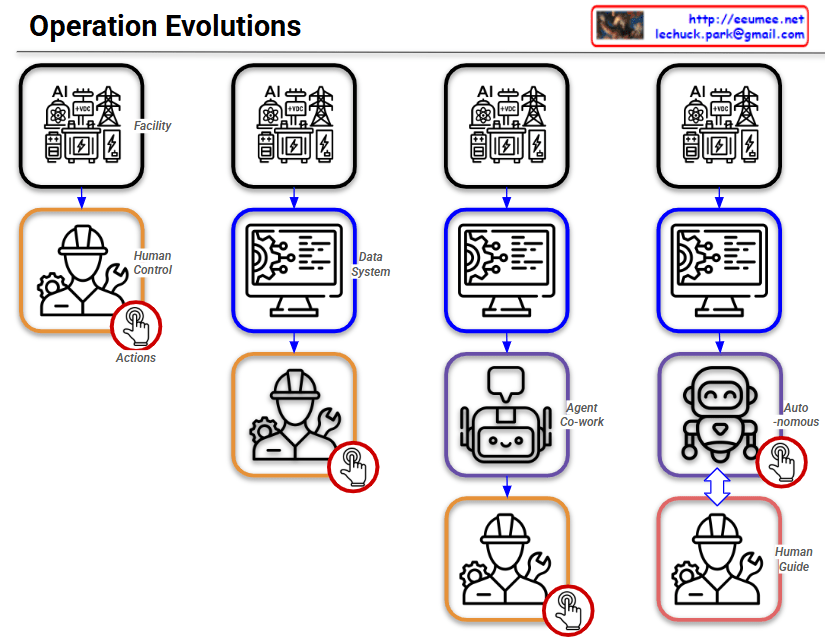
By following the red circle with the ‘Actions’ (clicking hand) icon, you can easily track how the control and operational authority shift throughout the four stages.
Stage 1: Human Control
- Structure: Facility ➡️ Human Control
- Description: This represents the most traditional, manual approach. Without a centralized data system, human operators directly monitor the facility’s status and manually execute all Actions based on their physical observations and judgment.
Stage 2: Data System
- Structure: Facility ➡️ Data System ➡️ Human Control
- Description: A monitoring or data system (like a dashboard) is introduced. Humans now rely on the data collected by the system to understand the facility’s condition. However, the final Actions are still manually performed by humans.
Stage 3: Agent Co-work
- Structure: Facility ➡️ Data System ➡️ Agent Co-work ➡️ Human Control
- Description: An AI Agent is introduced as an intermediary between the data system and the human operator. The AI analyzes the data and provides insights, recommendations, or assistance. Even with this support, the final decision-making and physical Actions remain entirely the human’s responsibility.
Stage 4: Autonomous (Auto-nomous)
- Structure: Facility ➡️ Data System ➡️ Auto-nomous ↔️ Human Guide
- Description: This is the ultimate stage of operational evolution. The authority to execute Actions has shifted from the human to the AI. The AI analyzes data, makes independent decisions, and autonomously controls the facility. The human’s role transitions from a direct controller to a ‘Human Guide’, supervising the AI and providing high-level directives. The two-way arrow indicates a continuous, interactive feedback loop where the human and AI collaborate to refine and optimize the system.
Summary:
This slide intuitively illustrates a paradigm shift in infrastructure operations: progressing from Direct Human Intervention ➡️ System-Assisted Cognition ➡️ AI-Assisted Operations (Co-work) ➡️ Fully Autonomous AI Control with Human Supervision.
#AIOps #AutonomousOperations #TechEvolution #DigitalTransformation #DataCenter #FacilityManagement #InfrastructureAutomation #SmartFacilities #AIAgents #FutureOfWork #HumanAndAI #Automation
with Gemini