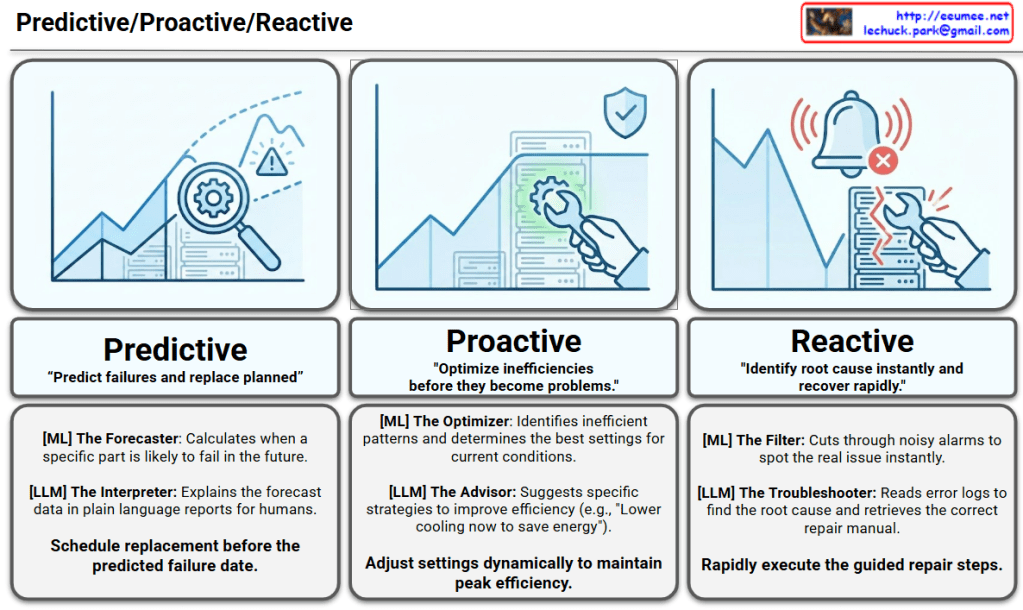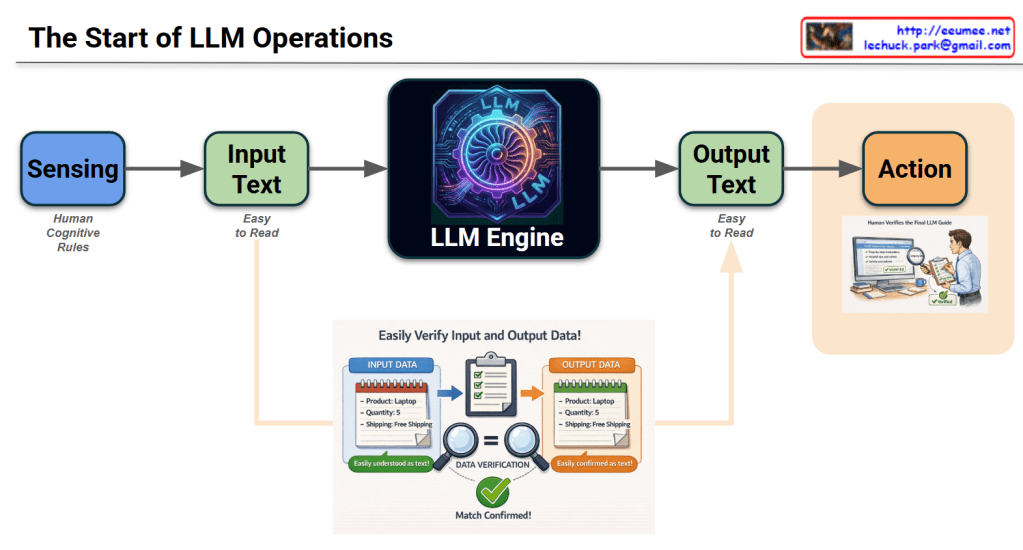
This infographic, titled “The Start of LLM Operations,” illustrates the end-to-end workflow of how a Large Language Model (LLM) processes information to drive real-world outcomes.
Detailed Breakdown of the Workflow
1. Core Process Flow (Horizontal Axis)
- Sensing: The initial stage where data is gathered based on Human Cognitive Rules. It represents the system “perceiving” the environment or requirements.
- Input Text: Data is converted into a format that is “Easy to Read” for humans, ensuring the prompt or command is transparent.
- LLM Engine: The central processing unit (symbolized by a high-tech gear) that analyzes the input and generates a response.
- Output Text: The engine produces a result, again in a human-readable format, to ensure clarity before execution.
- Action: The final stage where the output is translated into a functional task or operation.
2. Data Verification (Bottom Inset)
This section highlights the critical “Check & Balance” mechanism:
- Input Data vs. Output Data: It shows a specific example (Product: Laptop, Quantity: 5, Shipping: Free).
- Validation: The use of magnifying glasses and a green checkmark (Match Confirmed!) emphasizes that the output must strictly align with the input requirements to prevent hallucinations or errors.
3. Human-in-the-Loop (Right Section)
- The image of the person reviewing a checklist (“Human Verifies the Final LLM Guide”) signifies that human oversight is the final gatekeeper. Before the “Action” is taken, a person ensures the AI’s logic and results are safe and accurate.
Summary & Insight
The diagram suggests that successful LLM operations are not just about the model’s intelligence, but about transparency and verification. By keeping data “Easy to Read” and involving “Human Verification,” the system ensures that AI-driven actions are reliable and grounded in human-defined rules.
Hashtags
#LLMOps #GenerativeAI #AIWorkflow #DataVerification #HumanInTheLoop #ArtificialIntelligence #TechInfographic #AIOperations #MachineLearning #PromptEngineering
With Gemini