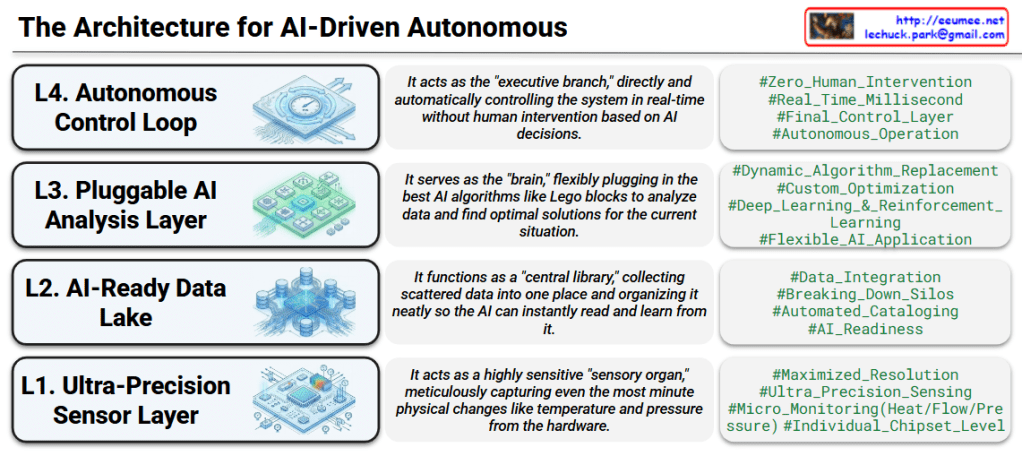
This slide effectively illustrates a complete, four-tier architecture required to build a fully autonomous AI system. Let’s walk through the framework from the foundation (data collection) to the top (autonomous execution):
- L1. Ultra-Precision Sensor Layer (The “Sensory Organ”)This foundational layer is all about high-resolution data capture. Acting as the system’s highly sensitive sensory organs, it meticulously monitors minute physical changes—such as heat, flow, and pressure—right down to the individual chipset level.
- L2. AI-Ready Data Lake (The “Central Library”)Once the data is captured, it flows into this layer to be consolidated. It breaks down data silos by collecting scattered facility data into one centralized library. It then automatically catalogs this information so that the AI can instantly access, read, and learn from it.
- L3. Pluggable AI Analysis Layer (The “Brain”)This is where the cognitive processing happens. Acting as the brain of the system, it analyzes the organized data to find optimal solutions. Its “pluggable” nature means you can dynamically swap in the best AI algorithms—like Deep Learning or Reinforcement Learning—just like snapping Lego blocks together to fit the specific situation.
- L4. Autonomous Control Loop (The “Executive Branch”)Finally, the insights from the brain are turned into action here. This layer operates in real-time (down to the millisecond) to send control signals back to the system. It executes decisions entirely on its own, achieving true autonomous operation with zero human intervention.
Summary
This architecture demonstrates a seamless, end-to-end operational flow: it starts by sensing microscopic hardware changes (L1), structures that raw data for immediate AI consumption (L2), applies dynamic and flexible algorithms to make smart decisions (L3), and ultimately executes those decisions autonomously in real-time (L4). It is a perfect blueprint for achieving a fully uncrewed, intelligent infrastructure.
#AIArchitecture #AutonomousSystems #EdgeComputing #DataLake #AIOps #SmartInfrastructure #MachineLearning #Automation
With Gemini