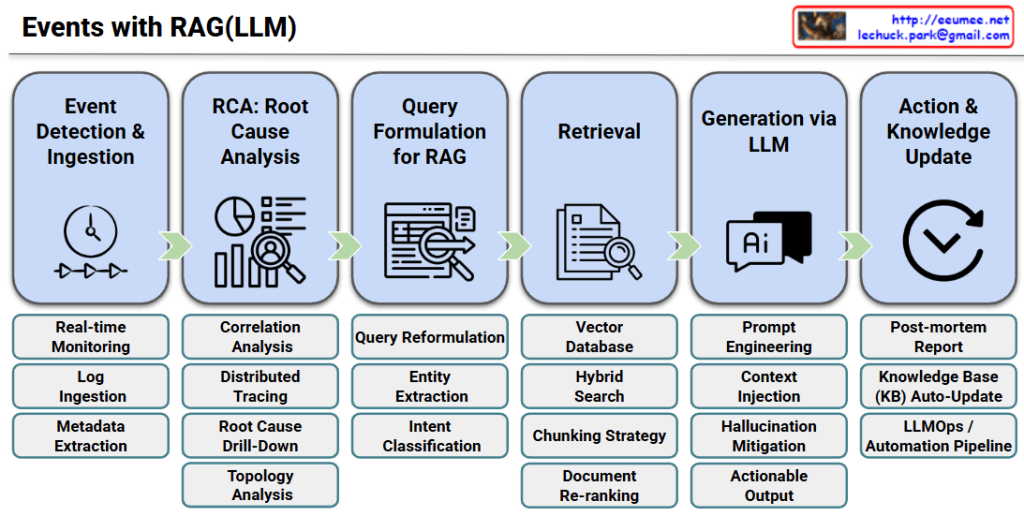
Step 1: Event Detection & Ingestion
This initial stage focuses on capturing system anomalies through real-time monitoring, collecting necessary logs, and extracting essential metadata to understand the context of the event.
Step 2: RCA: Root Cause Analysis
It identifies the fundamental issue behind the surface-level symptoms by utilizing correlation analysis, distributed tracing, root cause drill-down, and infrastructure topology analysis.
Step 3: Query Formulation for RAG
The system translates the RCA findings into an optimized search prompt through query reformulation, entity extraction, and intent classification to fetch the most accurate solutions.
Step 4: Retrieval
It searches for the most relevant technical documents or past incident records from a Vector Database, leveraging hybrid search, chunking strategies, and document re-ranking techniques.
Step 5: Generation via LLM
The LLM generates an actionable troubleshooting guide by combining prompt engineering and context injection, strictly mitigating any AI hallucinations.
Step 6: Action & Knowledge Update
Finally, after the issue is resolved, the system automatically updates its knowledge base with post-mortem reports, ensuring a continuous feedback loop through an automated LLMOps pipeline.
Summary
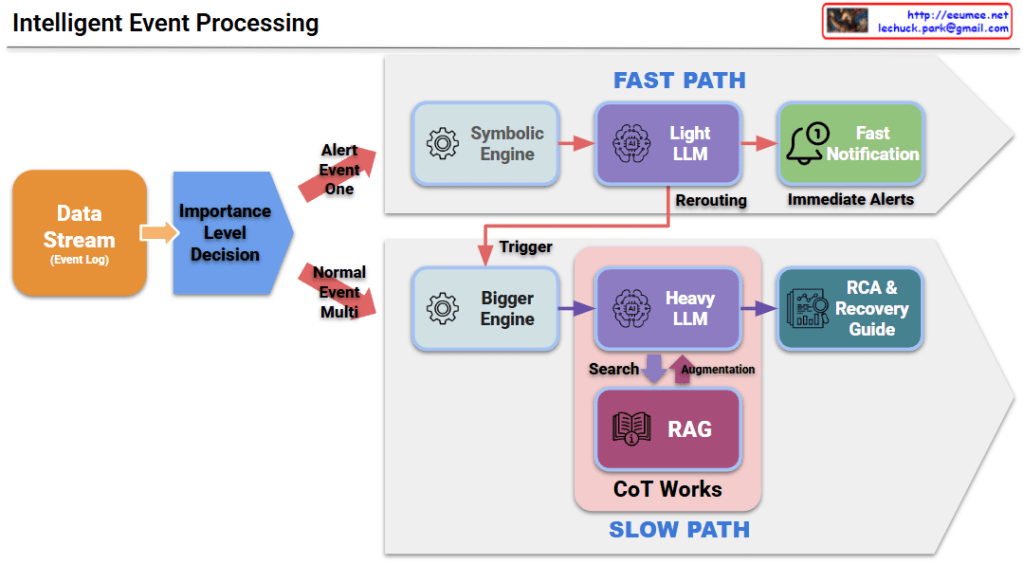
- Event Detection & Root Cause Analysis: When a system incident occurs, it is captured in real-time, and the system deeply traces the actual root cause rather than just addressing surface-level symptoms.
- Knowledge Retrieval & Solution Generation: The analyzed root cause is transformed into a RAG-optimized query to retrieve the best reference documents from the internal knowledge base, allowing the LLM to generate an immediately actionable troubleshooting guide.
- Knowledge Capitalization & Virtuous Cycle: Once the issue is resolved, a post-mortem report is generated and automatically fed back into the knowledge base, creating a continuously evolving and automated pipeline.
#AIOps #RAG_Architecture #RootCauseAnalysis #LLMOps #IncidentManagement #TroubleshootingAutomation #VectorDatabase
With Gemini