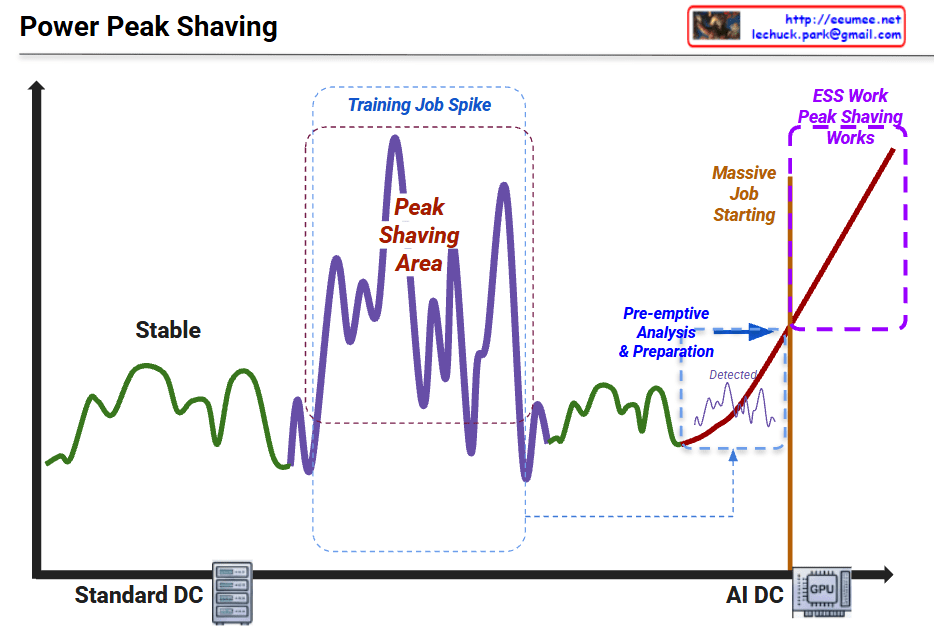
Graph Interpretation: Power Peak Shaving in AI Data Centers
This graph illustrates the shift in power consumption patterns from traditional data centers to AI-driven data centers and the necessity of “Peak Shaving” strategies.
1. Standard DC (Green Line – Left)
- Characteristics: Shows “Stable” power consumption.
- Interpretation: Traditional server workloads are relatively predictable with low volatility. The power demand stays within a consistent range.
2. Training Job Spike (Purple Line – Middle)
- Characteristics: Significant fluctuations labeled “Peak Shaving Area.”
- Interpretation: During AI model training, power demand becomes highly volatile. The spikes (peaks) and valleys represent the intensive GPU cycles required during training phases.
3. AI DC & Massive Job Starting (Red Line – Right)
- Characteristics: A sharp, vertical-like surge in power usage.
- Interpretation: As massive AI jobs (LLM training, etc.) start, the power load skyrockets. The graph shows a “Pre-emptive Analysis & Preparation” phase where the system detects the surge before it hits the maximum threshold.
4. ESS Work & Peak Shaving (Purple Dotted Box – Top Right)
- The Strategy: To handle the “Massive Job Starting,” the system utilizes ESS (Energy Storage Systems).
- Action: Instead of drawing all power from the main grid (which could cause instability or high costs), the ESS discharges stored energy to “shave” the peak, smoothing out the demand and ensuring the AI DC operates safely.
Summary
- Volatility Shift: AI workloads (GPU-intensive) create much more extreme and unpredictable power spikes compared to standard data center operations.
- Proactive Management: Modern AI Data Centers require pre-emptive detection and analysis to prepare for sudden surges in energy demand.
- ESS Integration: Energy Storage Systems (ESS) are critical for “Peak Shaving,” providing the necessary power buffer to maintain grid stability and cost efficiency.
#DataCenter #AI #PeakShaving #EnergyStorage #ESS #GPU #PowerManagement #SmartGrid #TechInfrastructure #AIDC #EnergyEfficiency
with Gemini