A night
The Computing for the Fair Human Life.
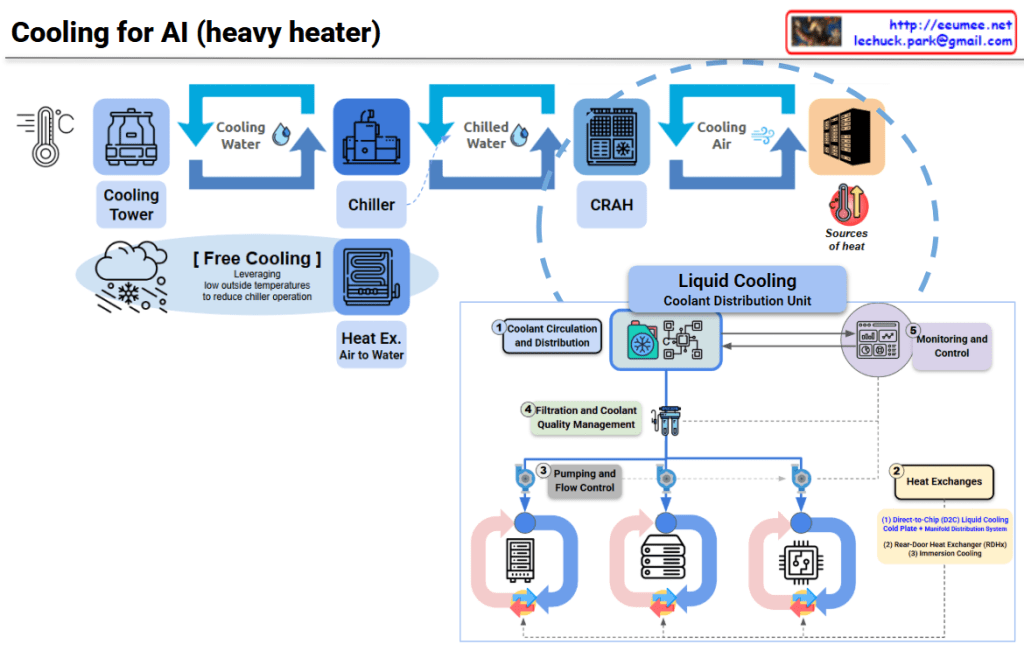
This diagram illustrates the evolution of data center cooling systems designed for high-heat AI workloads.
Three-Stage Cooling Process:
Free Cooling option is shown, which reduces chiller operation by leveraging low outside temperatures for energy savings.
To address extreme heat generation from high-density AI chips, a CDU (Coolant Distribution Unit) based liquid cooling system has been introduced.
① Coolant Circulation and Distribution
② Heat Exchanges (Two Methods)
③ Pumping and Flow Control
④ Filtration and Coolant Quality Management
⑤ Monitoring and Control
Traditional Method: Air cooling → Indirect, suitable for low-density workloads
AI DC Method: Liquid cooling → Direct, high-efficiency, capable of handling high TDP (Thermal Design Power) of AI chips
Liquid has approximately 25x better heat transfer efficiency than air, making it effective for cooling AI accelerators (GPUs, TPUs) that generate hundreds of watts to kilowatt-level heat.
#AIDataCenter #LiquidCooling #DataCenterInfrastructure #CDU #ThermalManagement #DirectToChip #AIInfrastructure #GreenDataCenter #HeatDissipation #HyperscaleComputing #AIWorkload #DataCenterCooling #ImmersionCooling #EnergyEfficiency #NextGenDataCenter
With Claude

This slide summarizes research findings on how AI workloads impact power grids and cooling systems.
#AIInfrastructure #MLOps #DataCenterEfficiency #PowerManagement #AIReliability #LLMTraining #SilentDataCorruption #EnergyEfficiency #GridStability #AIatScale #HPC #CoolingSystem #AIFailures #SustainableAI #InferenceOptimization
With Claude
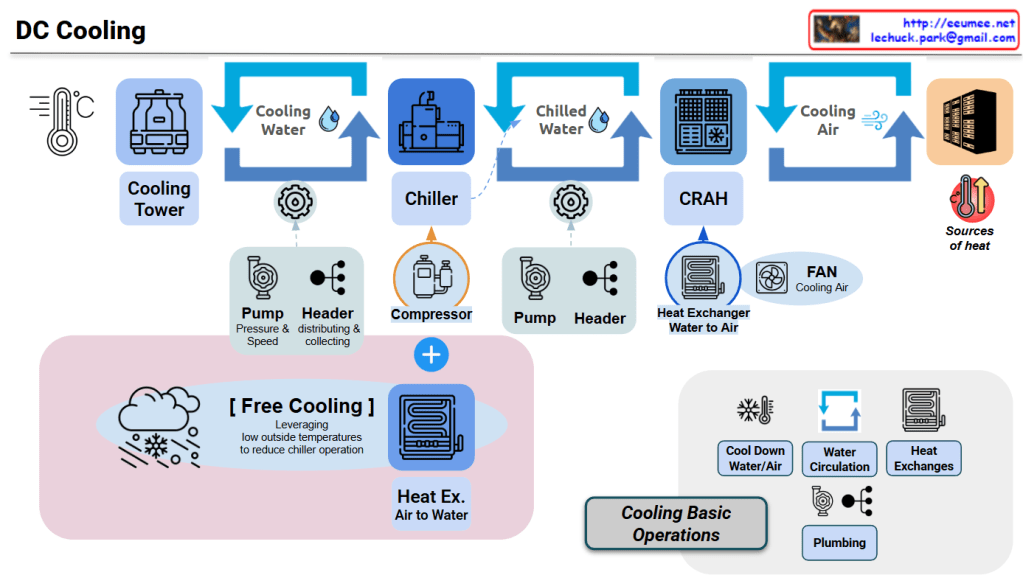
This diagram illustrates an integrated data center cooling system centered on chilled water/cooling water circulation and heat exchange.
Cooling Tower → Cooling Water → Chiller → (Heat Exchange) → Cooling Tower
Chiller → Chilled Water → CRAH → (Heat Exchange) → Chiller
CRAH → Cooling Air → Servers → Hot Air → CRAH
Low-Temperature Outdoor Air → Air-to-Water Heat Exchanger → Chilled Water Cooling → Reduced Chiller Load
Cooling Basic Operations Components:
Server Heat → Air → CRAH (Heat Exchange) → Chilled Water → Chiller (Heat Exchange) →
Cooling Water → Cooling Tower → Atmospheric Discharge
This system efficiently removes server heat to the outdoor atmosphere through three cascading circulation loops (air → chilled water → cooling water) and three strategic heat exchange points (CRAH, Chiller, Cooling Tower). Free cooling optimization reduces energy consumption by up to 50% when outdoor conditions permit. The integrated pump/header network ensures precise flow control across all loops for maximum cooling efficiency.
#DataCenterCooling #ChilledWater #CRAH #FreeCooling #HeatExchange #CoolingTower #ThermalManagement #DataCenterInfrastructure #EnergyEfficiency #HVACSystem #CoolingLoop #WaterCirculation #ServerCooling #DataCenterDesign #GreenDataCenter
With Claude
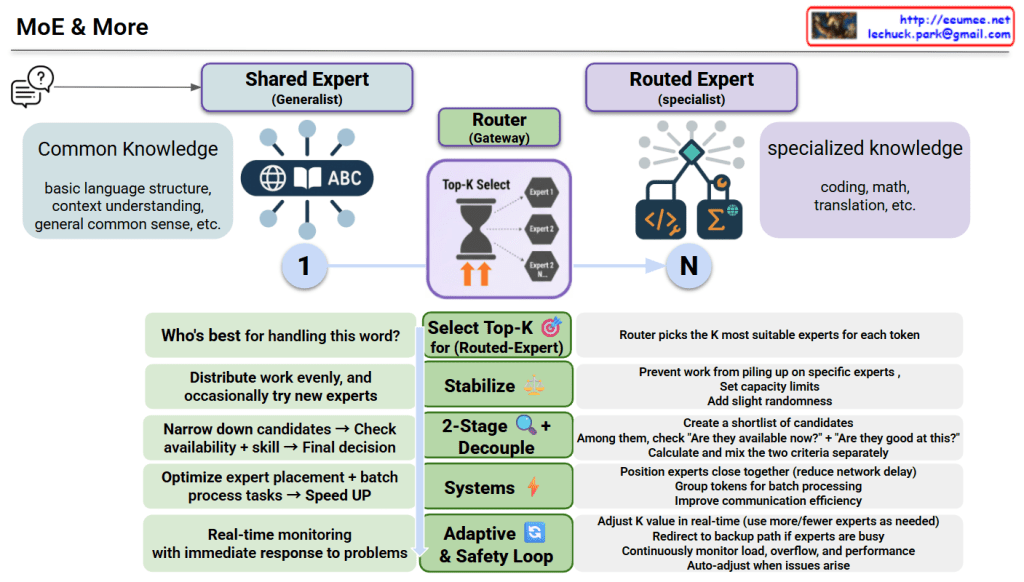
This diagram illustrates an advanced Mixture of Experts (MoE) model architecture.
For each token, determines “Who’s best for handling this word?” by:
This system enhances both efficiency and performance through:
MoE & More combines generalist experts (common knowledge) with specialist experts (domain-specific skills), using an intelligent router to dynamically select the best K experts for each token. Advanced techniques like 2-stage decoupling, stabilization, and adaptive safety loops ensure optimal load balancing, prevent bottlenecks, and enable real-time adjustments for maximum efficiency. The result is a faster, more efficient, and more reliable AI system that scales intelligently.
#MixtureOfExperts #MoE #AIArchitecture #MachineLearning #DeepLearning #LLM #NeuralNetworks #AIOptimization #ScalableAI #RouterMechanism #ExpertSystems #AIEfficiency #LoadBalancing #AdaptiveAI #MLOps
With Claude

Power Grid → Transformer → UPS → Server (220V AC)
Key Changes:
Why: AI chips (GPU/TPU) consume kW to tens of kW per server
Key Changes:
Why: AI workload characteristics
Key Changes:
Why: Maximize efficiency
| Category | Traditional DC | AI Data Center |
|---|---|---|
| Power Scale | Few MW | Hundreds of MW |
| Rack Density | 5-10 kW/rack | 30-100+ kW/rack |
| Power Method | AC-centric | HVDC + Direct DC |
| Backup Power | UPS (10-15 min) | Multi-tier (Generator+ESS+UPS) |
| Power Stability | Standard | Extremely high reliability |
| Energy Sources | Single grid | Multiple sources (Nuclear+Renewable) |
✅ AI data centers require 25-50x more power per server, demanding massive power infrastructure with diversified sources including SMRs and renewables
✅ Extreme workload stability needs drive multi-tier backup systems (ESS+UPS+Generator) and advanced power conditioning with 800V HVDC
✅ Direct-to-chip DC power delivery eliminates conversion losses, achieving 5-15% efficiency gains critical for 100+ kW/rack densities
#AIDataCenter #DataCenterPower #HVDC #DirectDC #EnergyStorageSystem #PeakShaving #SMR #PowerInfrastructure #HighDensityComputing #GPUPower #DataCenterDesign #EnergyEfficiency #UPS #BackupPower #AIInfrastructure #HyperscaleDataCenter #PowerConditioning #DCPower #GreenDataCenter #FutureOfComputing
With Claude

This image contrasts traditional programming, where developers must explicitly code rules and logic (shown with a flowchart and a thoughtful programmer), with AI, where neural networks automatically learn patterns from large amounts of data (depicted with a network diagram and a smiling programmer). It illustrates the paradigm shift from manually defining rules to machines learning patterns autonomously from data.
#AI #MachineLearning #Programming #ArtificialIntelligence #AIvsTraditionalProgramming
