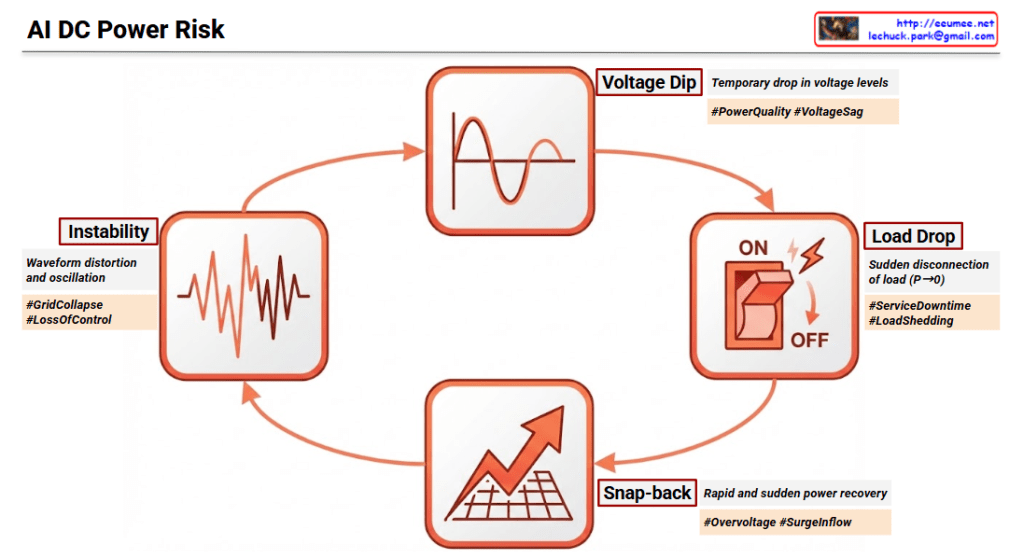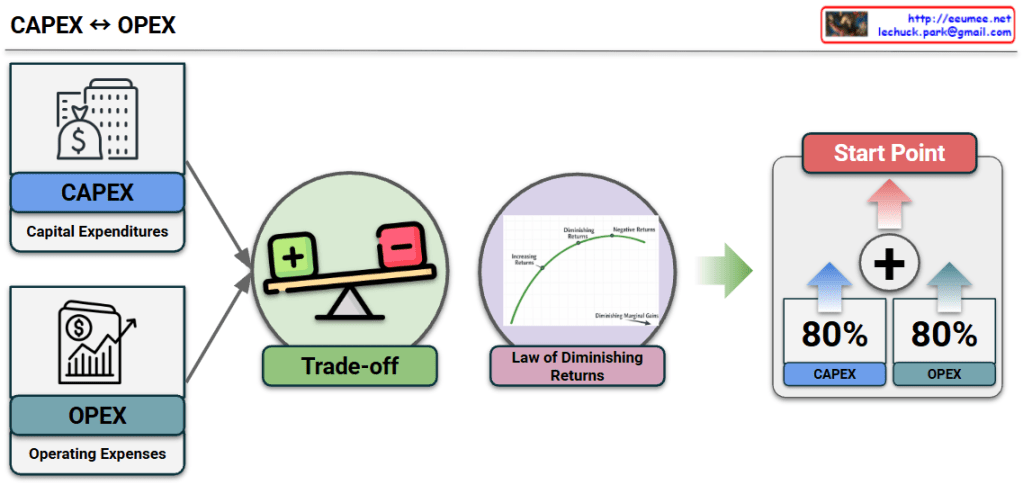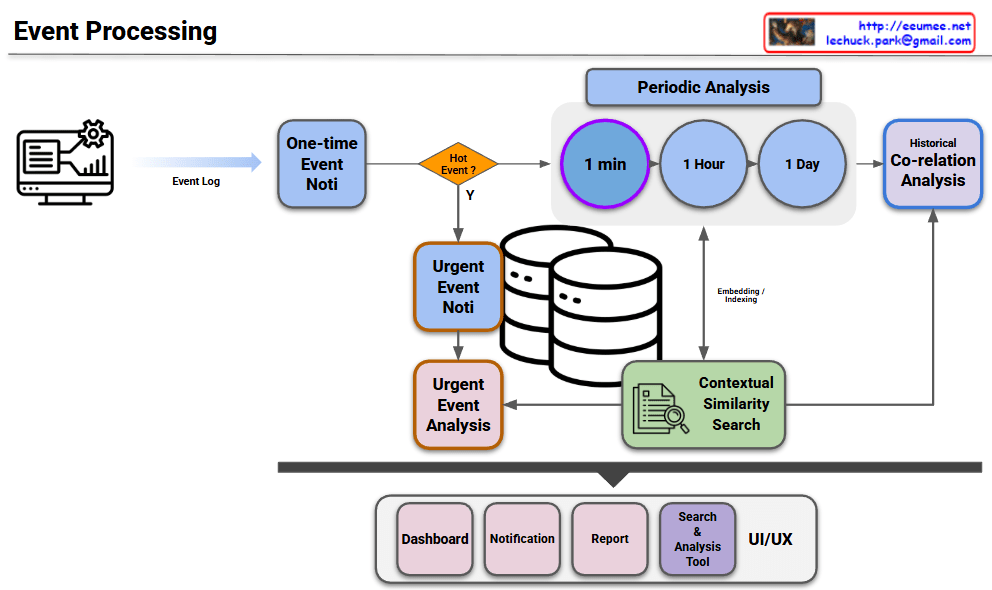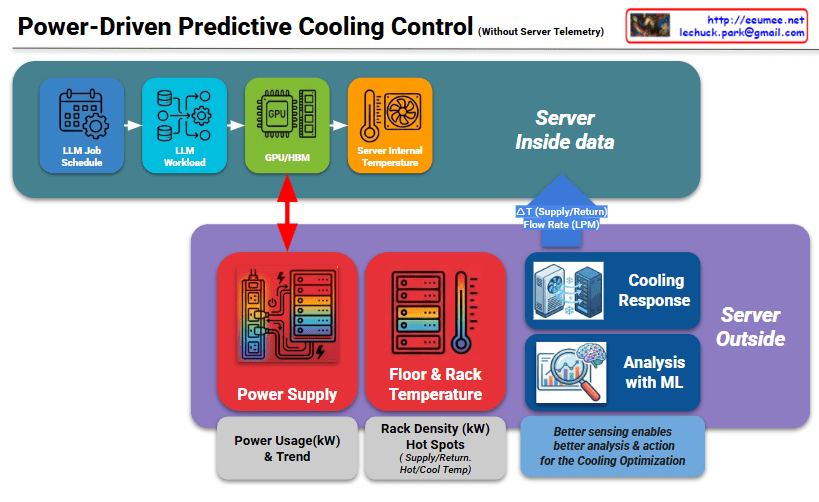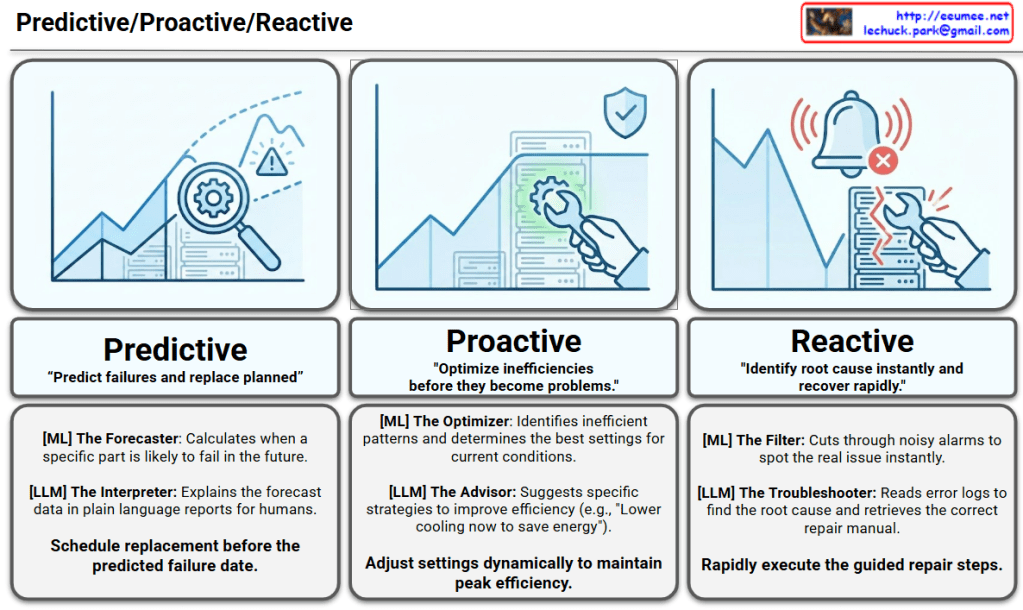
The infographic visualizes how AI technologies (Machine Learning and Large Language Models) are applied across Predictive, Proactive, and Reactive stages of facility management.
1. Predictive Stage
This is the most advanced stage, anticipating future issues before they occur.
- Core Goal: “Predict failures and replace planned.”
- Icon Interpretation: A magnifying glass is used to examine a future point on a rising graph, identifying potential risks (peaks and warnings) ahead of time.
- Role of AI:
- [ML] The Forecaster: Analyzes historical data to calculate precisely when a specific component is likely to fail in the future.
- [LLM] The Interpreter: Translates complex forecast data and probabilities into plain language reports that are easy for human operators to understand.
- Key Activity: Scheduling parts replacement and maintenance windows well before the predicted failure date.
2. Proactive Stage
This stage focuses on optimizing current conditions to prevent problems from developing.
- Core Goal: “Optimize inefficiencies before they become problems.”
- Icon Interpretation: On a stable graph, a wrench is shown gently fine-tuning the system for optimization, protected by a shield icon representing preventative measures.
- Role of AI:
- [ML] The Optimizer: Identifies inefficient operational patterns and determines the optimal configurations for current environmental conditions.
- [LLM] The Advisor: Suggests specific, actionable strategies to improve efficiency (e.g., “Lower cooling now to save energy”).
- Key Activity: Dynamically adjusting system settings in real-time to maintain peak efficiency.
3. Reactive Stage
This stage deals with responding rapidly and accurately to incidents that have already occurred.
- Core Goal: “Identify root cause instantly and recover rapidly.”
- Icon Interpretation: A sharp drop in the graph accompanied by emergency alarms, showing an urgent repair being performed on a broken server rack.
- Role of AI:
- [ML] The Filter: Cuts through the noise of massive alarm volumes to instantly isolate the true, critical issue.
- [LLM] The Troubleshooter: Reads and analyzes complex error logs to determine the root cause and retrieves the correct Standard Operating Procedure (SOP) or manual.
- Key Activity: Rapidly executing the guided repair steps provided by the system.
Summary
- The image illustrates the evolution of data center operations from traditional Reactive responses to intelligent Proactive optimization and Predictive maintenance.
- It clearly delineates the roles of AI, where Machine Learning (ML) handles data analysis and forecasting, while Large Language Models (LLMs) interpret these insights and provide actionable guidance.
- Ultimately, this integrated AI approach aims to maximize uptime, enhance energy efficiency, and accelerate incident recovery in critical infrastructure.
#DataCenter #AIOps #PredictiveMaintenance #SmartInfrastructure #ArtificialIntelligence #MachineLearning #LLM #FacilityManagement #ITOps
with Gemini