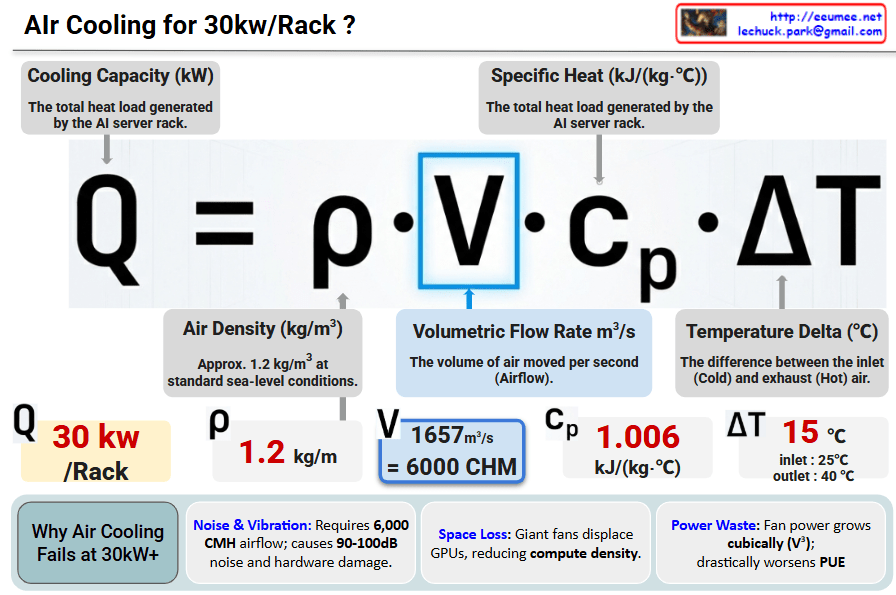
Power Waste: Fan power consumption grows cubically (V^3), causing a significant spike in PUE (Power Usage Effectiveness).
Conclusion: At 30kW/Rack, air cooling hits a physical and economic “wall”. Transitioning to Liquid Cooling is mandatory for next-generation AI Data Centers.
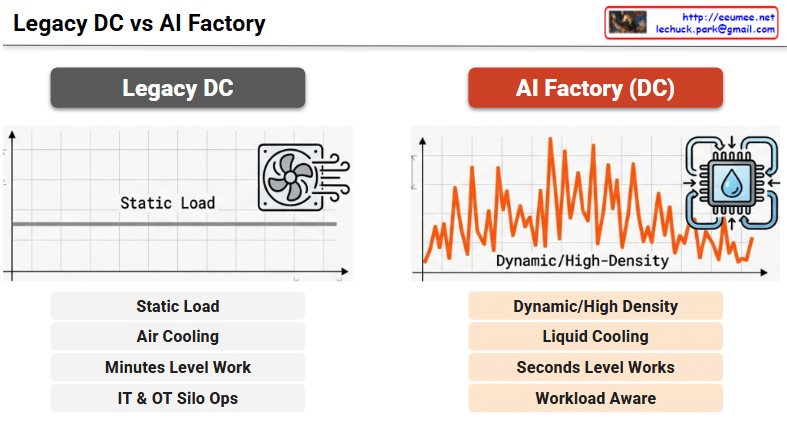
Static Load: The flat line on the graph indicates that power and compute demands are stable, continuous, and highly predictable.
Air Cooling: Traditional fan-based air cooling systems are sufficient to manage the heat generated by standard, lower-density server racks.
Minutes Level Work: System responses, resource provisioning, and facility adjustments generally occur on a scale of minutes.
IT & OT Silo Ops: Information Technology (servers, networking) and Operational Technology (power, cooling facilities) are managed independently in isolated silos, with no real-time data exchange.
2. AI Factory (DC)
Dynamic/High-Density: The volatile, jagged graph illustrates how AI workloads create extreme, rapid power spikes and demand highly dense computing resources.
Liquid Cooling: The immense heat output from high-performance AI chips necessitates advanced liquid cooling solutions (represented by the water drop and circulation arrows) to maintain thermal efficiency.
Seconds Level Works: The physical infrastructure must be highly agile, detecting and responding to sudden dynamic workload changes and thermal shifts within seconds.
Workload Aware: The facility dynamically adapts its cooling and power based on real-time AI computing needs. Establishing this requires robust “IT/OT Data Convergence” and the utilization of “High-Fidelity Data” as key components of a broader “Digitalization” strategy.
Summary
Legacy data centers are designed for predictable, static loads using traditional air cooling, with IT and facility operations (OT) isolated from one another.
AI Factories must handle highly volatile, high-density workloads, making liquid cooling and instantaneous, seconds-level infrastructure responses mandatory.
Transitioning to a true “Workload Aware” facility requires a strong “Digitalization” strategy centered around “IT/OT Data Convergence” and “High-Fidelity Data.”
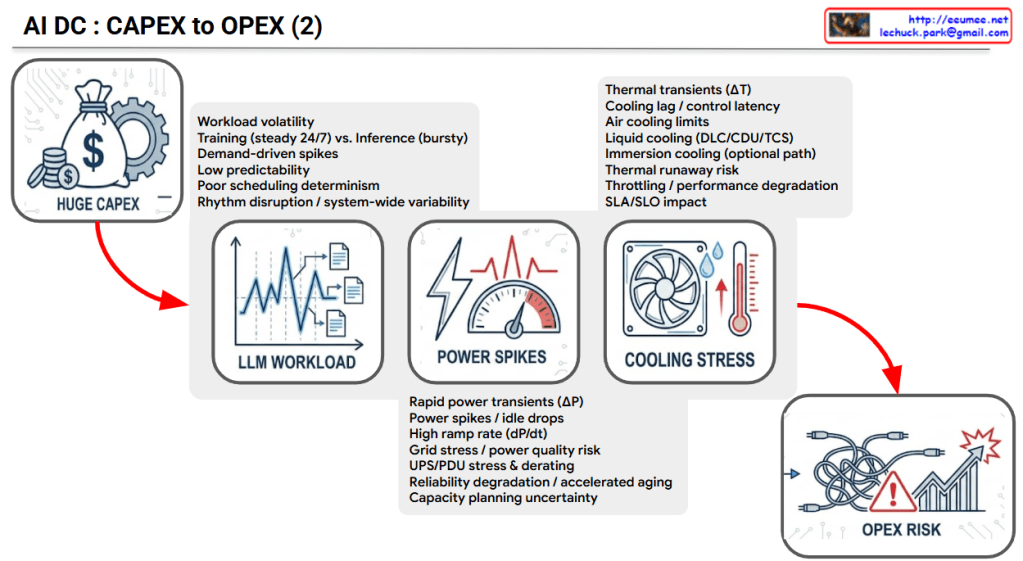
The provided image logically illustrates the sequential mechanism of how the massive initial capital expenditure (CAPEX) of an AI Data Center (AI DC) translates into complex operational risks and increased operating expenses (OPEX).
1. HUGE CAPEX (Massive Initial Investment)
Context: Building an AI data center requires enormous capital expenditure (CAPEX) due to high-cost GPU servers, high-density racks, and specialized networking infrastructure.
Flow: However, the challenge does not end with high initial costs. Driven by the following three factors, this massive infrastructure investment inevitably cascades into severe operational risks.
2. LLM WORKLOAD (The Root Cause)
Characteristics: Unlike traditional IT workloads, AI (especially LLM) workloads are highly volatile and unpredictable.
Key Factors: * The continuous, heavy load of Training (steady 24/7) mixed with the bursty, erratic nature of Inference.
Demand-driven spikes and low predictability, which lead to poor scheduling determinism and system-wide rhythm disruption.
3. POWER SPIKES (Electrical Infrastructure Stress)
Characteristics: The extreme volatility of LLM workloads causes sudden, extreme fluctuations in server power consumption.
Key Factors:
Rapid power transients (ΔP) and high ramp rates (dP/dt) create sudden power spikes and idle drops.
These fluctuations cause significant grid stress, accelerate the aging of power distribution equipment (UPS/PDU stress & derating), degrade overall system reliability, and create major capacity planning uncertainty.
4. COOLING STRESS (Thermal System Stress)
Characteristics: Sudden surges in power consumption immediately translate into rapid temperature increases (Thermal transients, ΔT).
Key Factors:
Cooling lag / control latency: There is an inevitable delay between the sudden heat generation and the cooling system’s physical response.
Physical limits: Traditional air cooling hits its limits, forcing transitions to Liquid cooling (DLC/CDU) or Immersion cooling. Failure to manage this latency increases the risk of thermal runaway, triggers system throttling (performance degradation), and negatively impacts SLAs/SLOs.
5. OPEX RISK (The Final Operational Consequence)
Context: The combination of unpredictable LLM workloads, power infrastructure stress, and cooling system limitations culminates in severe OPEX Risk.
Conclusion: Ultimately, this chain reaction exponentially increases daily operational costs and uncertainties—ranging from accelerated equipment replacement costs and higher power bills (due to degraded PUE) to massive expenses related to frequent incident responses and infrastructure instability.
Summary:
The slide delivers a powerful message: While the physical construction of an AI data center is highly expensive (CAPEX), the true danger lies in the unique volatility of AI workloads. This volatility triggers extreme power (ΔP) and thermal (ΔT) spikes. If these physical transients are not strictly managed, the operational costs and risks (OPEX) will spiral completely out of control.
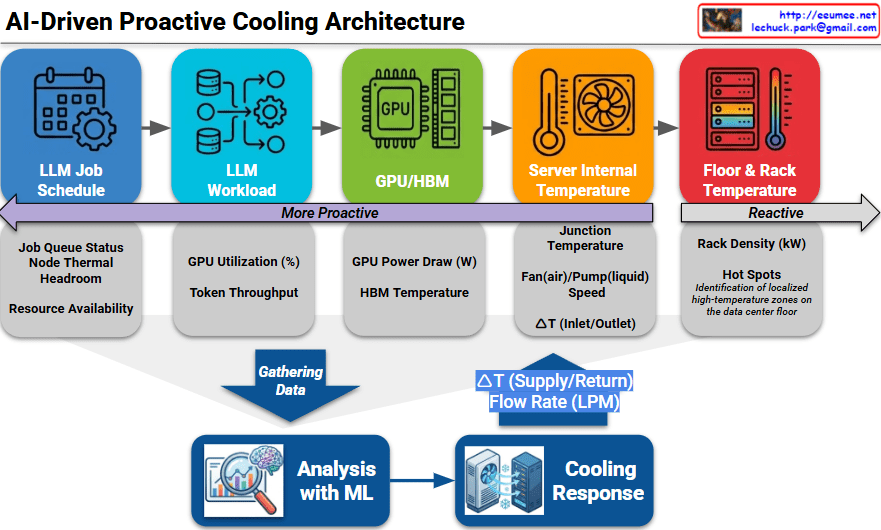
The provided image illustrates an AI-Driven Proactive Cooling Architecture, detailing a sophisticated pipeline that transforms operational data into precise thermal management.
1. The Proactive Data Hierarchy
The architecture categorizes data sources along a spectrum, moving from “More Proactive” (predicting future heat) to “Reactive” (measuring existing heat).
LLM Job Schedule (Most Proactive): This layer looks at the job queue, node thermal headroom, and resource availability. It allows the system to prepare for heat before the first calculation even begins.
LLM Workload: Monitors real-time GPU utilization (%) and token throughput to understand the intensity of the current processing task.
GPU / HBM: Captures direct hardware telemetry, including GPU power draw (Watts) and High Bandwidth Memory (HBM) temperatures.
Server Internal Temperature: Measures the junction temperature, fan/pump speeds, and the $\Delta T$ (temperature difference) between server inlet and outlet.
Floor & Rack Temperature (Reactive): The traditional monitoring layer that identifies hot spots and rack density (kW) once heat has already entered the environment.
2. The Analysis and Response Loop
The bottom section of the diagram shows how this multi-layered data is converted into action:
Gathering Data: Telemetry from all five layers is aggregated into a central repository.
Analysis with ML: A Machine Learning engine processes this data to predict thermal trends. It doesn’t just look at where the temperature is now, but where it will be in the next few minutes based on the workload.
Cooling Response: The ML insights trigger physical adjustments in the cooling infrastructure, specifically controlling the $\Delta T$ (Supply/Return) and Flow Rate (LPM – Liters Per Minute) of the coolant.
3. Technical Significance
By shifting the control logic “left” (toward the LLM Job Schedule), data centers can eliminate the thermal lag inherent in traditional systems. This is particularly critical for AI infrastructure, where GPU power consumption can spike almost instantaneously, often faster than traditional mechanical cooling systems can ramp up.
Summary
This architecture shifts cooling from a reactive sensor-based model to a proactive workload-aware model using AI/ML.
It integrates data across the entire stack, from high-level LLM job queues down to chip-level GPU power draw and rack temperatures.
The ML engine predicts thermal demand to dynamically adjust coolant flow rates and supply temperatures, significantly improving energy efficiency and hardware longevity.
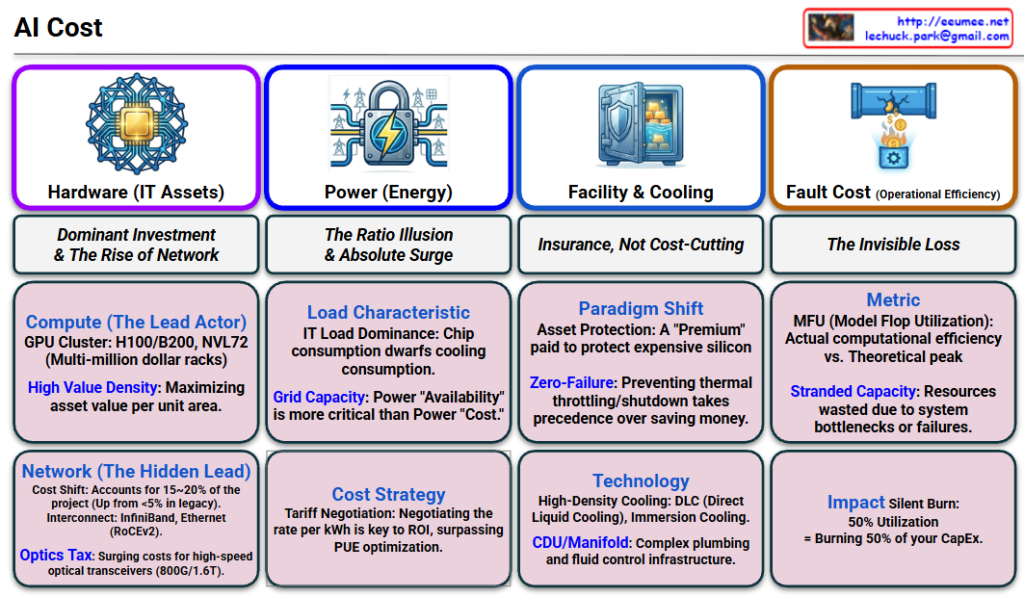
Key Message: The absolute dominant force, consuming ~70% of the total budget.
Details:
Compute (The Lead): Features GPU clusters (H100/B200, NVL72). These are not just servers; they represent “High Value Density.”
Network (The Hidden Lead): No longer just cabling. The cost of Interconnects (InfiniBand/RoCEv2) and Optics (800G/1.6T) has surged to 15~20%, acting as the critical nervous system of the cluster.
2. Power (Energy): “The Capacity War”
Icon: An electric grid secured by a heavy lock (representing capacity security).
Key Message: A “Ratio Illusion.” While the percentage (~20%) seems stable due to the skyrocketing hardware costs, the absolute electricity bill has exploded.
Details:
Load Characteristic: The IT Load (Chip power) dwarfs the cooling load.
Strategy: The battle is not just about Efficiency (PUE), but about Availability (Grid Capacity) and Tariff Negotiation.
3. Facility & Cooling: “The Insurance Policy”
Icon: A vault holding gold bars (Asset Protection).
Key Message: Accounting for ~10% of CapEx, this is not an area for cost-cutting, but for “Premium Insurance.”
Details:
Paradigm Shift: The facility exists to protect the multi-million dollar “Silicon Assets.”
Technology:Zero-Failure is the goal. High-density technologies like DLC (Direct Liquid Cooling) and Immersion Cooling are mandatory to prevent thermal throttling.
4. Fault Cost (Operational Efficiency): “The Invisible Loss”
Icon: A broken pipe leaking coins (burning money).
Key Message: A “Hidden Cost” that determines the actual success or failure of the business.
Details:
Metric: The core KPI is MFU (Model Flop Utilization).
Impact: Any bottleneck (network stall, storage wait) results in “Stranded Capacity.” If utilization drops to 50%, you are effectively engaging in a “Silent Burn” of 50% of your massive CapEx investment.
💡 Architect’s Note
This chart perfectly illustrates “Why we need an AI DC Operating System.”
“Pillars 1, 2, and 3 (Hardware, Power, Facility) represent the massive capital burned during CONSTRUCTION.
Pillar 4 (Fault Cost) is the battleground for OPERATION.”
Your Operating System is the solution designed to plug the leak in Pillar 4, ensuring that the astronomical investments in Pillars 1, 2, and 3 translate into actual computational value.
Summary
The AI Data Center is a “High-Value Density Asset” where Hardware dominates CapEx (~70%), Power dominates OpEx dynamics, and Facility acts as Insurance. However, the Operational System (OS) is the critical differentiator that prevents Fault Cost—the silent killer of ROI—by maximizing MFU.
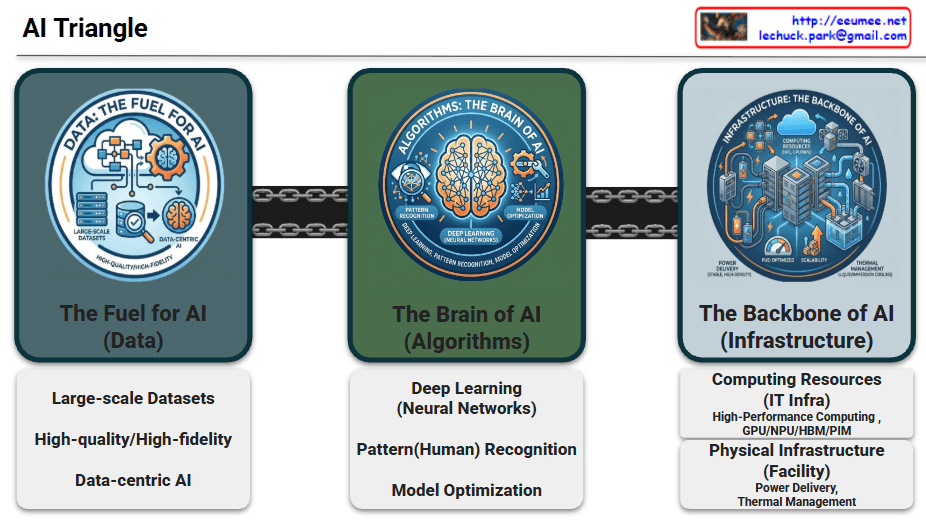
Data serves as the essential raw material that determines the intelligence and accuracy of AI models.
Large-scale Datasets: Massive volumes of information required for foundational training.
High-quality/High-fidelity: The emphasis on clean, accurate, and reliable data to ensure superior model performance.
Data-centric AI: A paradigm shift focusing on enhancing data quality rather than just iterating on model code.
2. Algorithms: The Brain of AI
Algorithms provide the logical framework and mathematical structures that allow machines to learn from data.
Deep Learning (Neural Networks): Multi-layered architectures inspired by the human brain to process complex information.
Pattern Recognition: The ability to identify hidden correlations and make predictions from raw inputs.
Model Optimization: Techniques to improve efficiency, reduce latency, and minimize computational costs.
3. Infrastructure: The Backbone of AI
The physical and digital foundation that enables massive computations and ensures system stability.
Computing Resources (IT Infra):
HPC & Accelerators: High-performance clusters utilizing GPUs, NPUs, and HBM/PIM for parallel processing.
Physical Infrastructure (Facilities):
Power Delivery: Reliable, high-density power systems including UPS, PDU, and smart energy management.
Thermal Management: Advanced cooling solutions like Liquid Cooling and Immersion Cooling to handle extreme heat from AI chips.
Scalability & PUE: Focus on sustainable growth and maximizing energy efficiency (Power Usage Effectiveness).
📝 Summary
The AI Triangle represents the vital synergy between high-quality Data, sophisticated Algorithms, and robust Infrastructure.
While data fuels the model and algorithms provide the logic, infrastructure acts as the essential backbone that supports massive scaling and operational reliability.
Modern AI evolution increasingly relies on advanced facility management, specifically optimized power delivery and high-efficiency cooling, to sustain next-generation workloads.
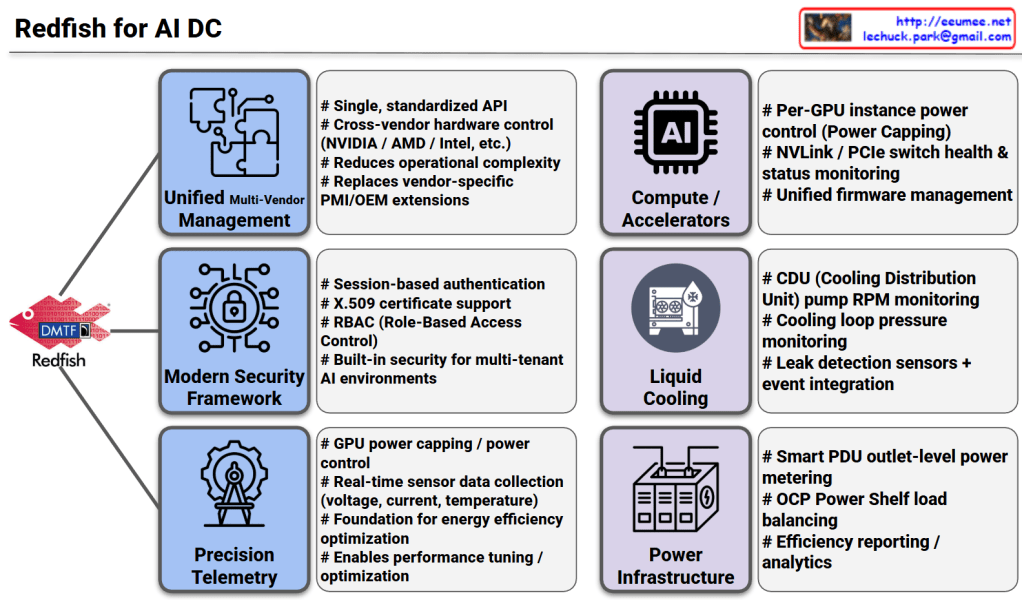
This image illustrates the pivotal role of the Redfish API (developed by DMTF) as the standardized management backbone for modern AI Data Centers (AI DC). As AI workloads demand unprecedented levels of power and cooling, Redfish moves beyond traditional server management to provide a unified framework for the entire infrastructure stack.
1. Management & Security Framework (Left Column)
Unified Multi-Vendor Management:
Acts as a single, standardized API to manage diverse hardware from different vendors (NVIDIA, AMD, Intel, etc.).
It reduces operational complexity by replacing fragmented, vendor-specific IPMI or OEM extensions with a consistent interface.
Modern Security Framework:
Designed for multi-tenant AI environments where security is paramount.
Supports robust protocols like session-based authentication, X.509 certificates, and RBAC (Role-Based Access Control) to ensure only authorized entities can modify critical infrastructure.
Precision Telemetry:
Provides high-granularity, real-time data collection for voltage, current, and temperature.
This serves as the foundation for energy efficiency optimization and fine-tuning performance based on real-time hardware health.
2. Infrastructure & Hardware Control (Right Column)
Compute / Accelerators:
Enables per-GPU instance power capping, allowing operators to limit power consumption at a granular level.
Monitors the health of high-speed interconnects like NVLink and PCIe switches, and simplifies firmware lifecycle management across the cluster.
Liquid Cooling:
As AI chips run hotter, Redfish integrates with CDU (Cooling Distribution Unit) systems to monitor pump RPM and loop pressure.
It includes critical safety features like leak detection sensors and integrated event handling to prevent hardware damage.
Power Infrastructure:
Extends management to the rack level, including Smart PDU outlet metering and OCP (Open Compute Project) Power Shelf load balancing.
Facilitates advanced efficiency analytics to drive down PUE (Power Usage Effectiveness).
Summary
For an AI DC Optimization Architect, Redfish is the essential “language” that enables Software-Defined Infrastructure. By moving away from manual, siloed hardware management and toward this API-driven approach, data centers can achieve the extreme automation required to shift OPEX structures predominantly toward electricity costs rather than labor.