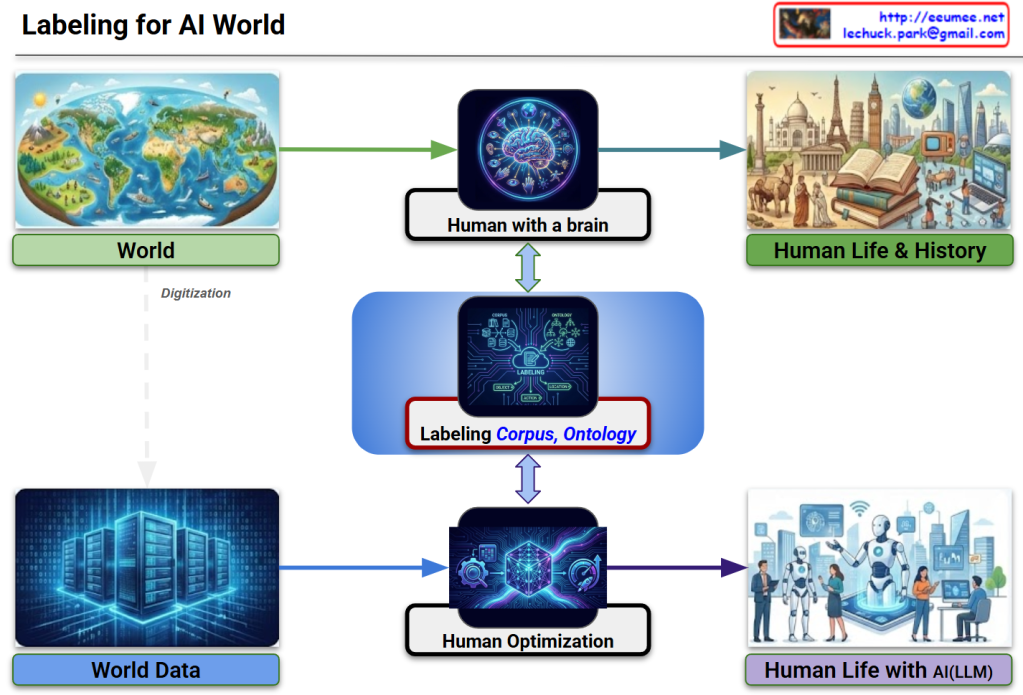
The image illustrates a logical framework titled “Labeling for AI World,” which maps how human cognitive processes are digitized and utilized to train Large Language Models (LLMs). It emphasizes the transition from natural human perception to optimized AI integration.
1. The Natural Cognition Path (Top)
This track represents the traditional human experience:
- World to Human with a Brain: Humans sense the physical world through biological organs, which the brain then analyzes and processes into information.
- Human Life & History: This cognitive processing results in the collective knowledge, culture, and documented history of humanity.
2. The Digital Optimization Path (Bottom)
This track represents the technical pipeline for AI development:
- World Data: Through Digitization, the physical world is converted into raw data stored in environments like AI Data Centers.
- Human Optimization: This raw data is refined through processes like RLHF (Reinforcement Learning from Human Feedback) or fine-tuning to align AI behavior with human intent.
- Human Life with AI (LLM): The end goal is a lifestyle where humans and LLMs coexist, with the AI acting as a sophisticated partner in daily life.
3. The Central Bridge: Labeling (Corpus & Ontology)
The most critical element of the diagram is the central blue box, which acts as a bridge between human logic and machine processing:
- Corpus: Large-scale structured text data necessary for training.
- Ontology: The formal representation of categories, properties, and relationships between concepts that define the human “worldview.”
- The Link: High-quality Labeling ensures that AI optimization is grounded in human-defined logic (Ontology) and comprehensive language data (Corpus), ensuring both Quality and Optimization.
Summary
The diagram demonstrates that Data Labeling, guided by Corpus and Ontology, is the essential mechanism that translates human cognition into the digital realm. It ensures that LLMs are not just processing raw numbers, but are optimized to understand the world through a human-centric logical framework.
#AI #DataLabeling #LLM #Ontology #Corpus #CognitiveComputing #AIOptimization #DigitalTransformation
With Gemini