AI Infrastructure Architect & Technical Visualizer "Complex Systems, Simplified. I translate massive AI infrastructure into visual intelligence." I love to learn computer tech and help people by the digital.
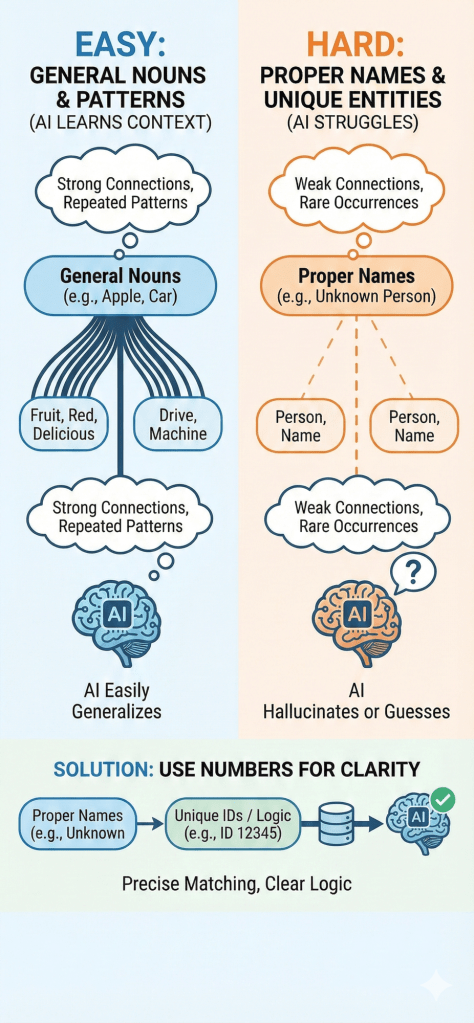
This infographic illustrates the fundamental difference in how AI processes language. It shows that AI excels at understanding General Nouns (like “apple” or “car”) because they are built on strong, repeated contextual patterns. In contrast, AI struggles with Proper Nouns (like specific names) due to weak connections and a lack of context, often leading to hallucinations. The visual suggests a solution: converting unique entities into Numbers or IDs, which offer the clear logic and precision that AI models prefer over ambiguous text.
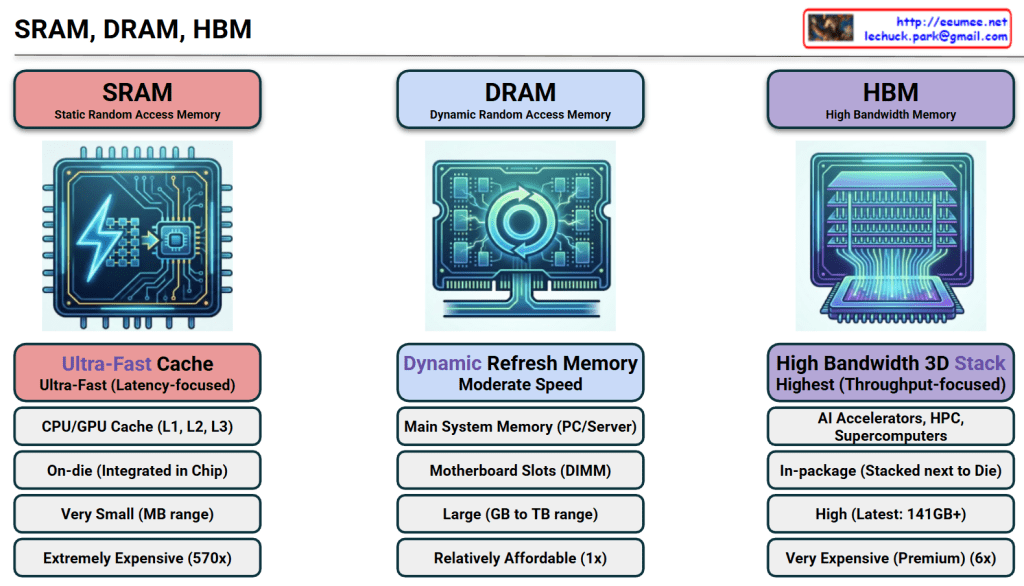
The image provides a comprehensive comparison of SRAM, DRAM, and HBM, which are the three pillars of modern memory architecture. For an expert in AI infrastructure, this hierarchy explains why certain hardware choices are made to balance performance and cost.
1. SRAM (Static Random Access Memory)
Role:Ultra-Fast Cache. It serves as the immediate storage for the CPU/GPU to prevent processing delays.
Location:On-die. It is integrated directly into the silicon of the processor chip.
Capacity: Very small (MB range) due to the large physical size of its 6-transistor structure.
Cost:Extremely Expensive (~570x vs. DRAM). This is the “prime real estate” of the semiconductor world.
Key Insight: Its primary goal is Latency-focus. It ensures the most frequently used data is available in nanoseconds.
2. DRAM (Dynamic Random Access Memory)
Role:Main System Memory. It is the standard “workspace” for a server or PC.
Location:Motherboard Slots (DIMM). It sits externally to the processor.
Capacity: Large (GB to TB range). It is designed to hold the OS and active applications.
Cost:Relatively Affordable (1x). It serves as the baseline for memory pricing.
Key Insight: It requires a constant “Refresh” to maintain data, making it “Dynamic,” but it offers the best balance of capacity and price.
3. HBM (High Bandwidth Memory)
Role:AI Accelerators & Supercomputing. It is the specialized engine behind modern AI GPUs like the NVIDIA H100.
Location:In-package. It is stacked vertically (3D Stack) and placed right next to the GPU die on a silicon interposer.
Capacity: High (Latest versions offer 141GB+ per stack).
Cost:Very Expensive (Premium, ~6x vs. DRAM).
Key Insight: Its primary goal is Throughput-focus. By widening the data “highway,” it allows the GPU to process massive datasets (like LLM parameters) without being bottlenecked by memory speed.
📊 Technical Comparison Summary
Feature
SRAM
DRAM
HBM
Speed Type
Low Latency
Moderate
High Bandwidth
Price Factor
570x
1x (Base)
6x
Packaging
Integrated in Chip
External DIMM
3D Stacked next to Chip
💡 Summary
SRAM offers ultimate speed at an extreme price, used exclusively for tiny, critical caches inside the processor.
DRAM is the cost-effective “standard” workspace used for general system tasks and large-scale data storage.
HBM is the high-bandwidth solution for AI, stacking memory vertically to feed data-hungry GPUs at lightning speeds.
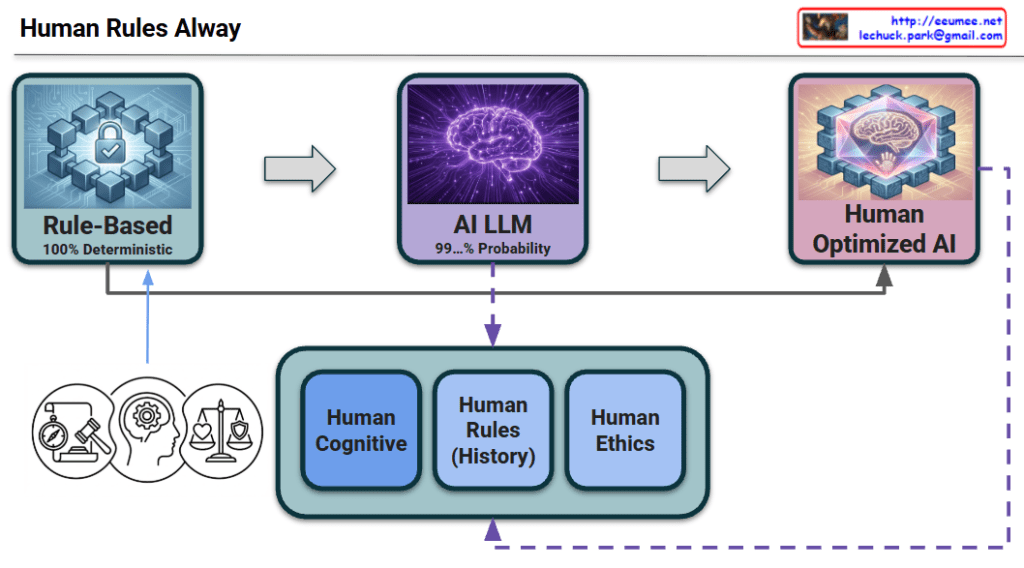
This diagram visualizes the history and future direction of intelligent systems. It illustrates the evolution from the era of manual programming to the current age of generative AI, and finally to the ultimate goal where human standards perfect the technology.
1. The 3 Stages of Technological Evolution (Top Flow)
Stage 1: Rule-Based (The Foundation / Past)
Concept:“The Era of Human-Defined Logic”
Context: This represents the starting point of computing where humans explicitly created formulas and coded every rule.
Characteristics: It is 100% Deterministic. While accurate within its scope, it cannot handle the complexity of the real world beyond what humans have manually programmed.
Stage 2: AI LLM (The Transition / Present)
Concept:“The Era of Probabilistic Scale”
Context: We have evolved into the age of massive parallel processing and Large Language Models.
Characteristics: It operates on 99…% Probability. It offers immense scalability and creativity that rule-based systems could never achieve, but it lacks the absolute certainty of the past, occasionally leading to inefficiencies or hallucinations.
Stage 3: Human Optimized AI (The Final Goal / Future)
Concept:“The Era of Reliability & Efficiency”
Context: This is the destination we must reach. It is not just about using AI, but about integrating the massive power of the “Present” (AI LLM) with the precision of the “Past” (Rule-Based).
Characteristics: By applying human standards to control the AI’s massive parallel processing, we achieve a system that is both computationally efficient and strictly reliable.
2. The Engine of Evolution: Human Standards (Bottom Box)
This section represents the mechanism that drives the evolution from Stage 2 to Stage 3.
The Problem: Raw AI (Stage 2) consumes vast energy and can be unpredictable.
The Solution: We must re-introduce the “Human Rules” (History, Logic, Ethics) established in Stage 1 into the AI’s workflow.
The Process:
Constraint & Optimization: Human Cognition and Rules act as a pruning mechanism, cutting off wasteful parallel computations in the LLM.
Safety:Ethics ensure the output aligns with human values.
Result: This filtering process transforms the raw, probabilistic energy of the LLM into the polished, “Human Optimized” state.
3. The Feedback Loop (Continuous Evolution)
Dashed Line: The journey doesn’t end at Stage 3. The output from the optimized AI is reviewed by humans, which in turn updates our rules and ethical standards. This circular structure ensures that the AI continues to evolve alongside human civilization.
This diagram declares that the future of AI lies not in discarding the old “Rule-Based” ways, but in fusing that deterministic precision with modern probabilistic power to create a truly optimized intelligence.
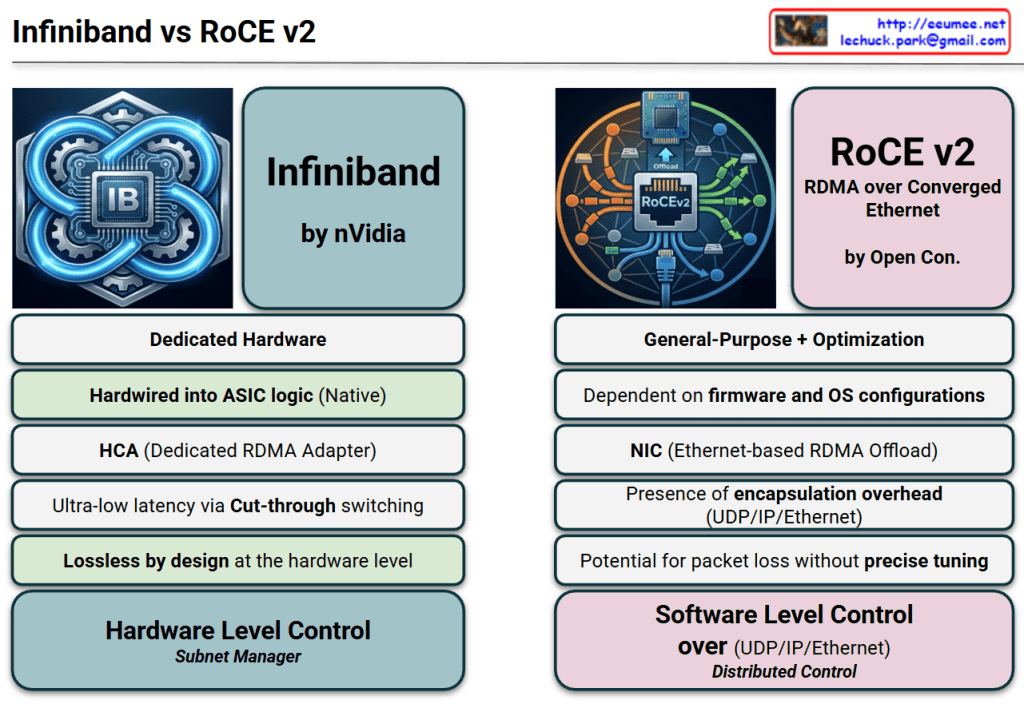
This image provides a technical comparison between InfiniBand and RoCE v2 (RDMA over Converged Ethernet), the two dominant networking protocols used in modern AI data centers and High-Performance Computing (HPC) environments.
1. Architectural Philosophy
InfiniBand (Dedicated Hardware): Designed from the ground up specifically for high-throughput, low-latency communication. It is a proprietary ecosystem largely driven by NVIDIA (Mellanox).
RoCE v2 (General-Purpose + Optimization): An evolution of standard Ethernet designed to bring RDMA (Remote Direct Memory Access) capabilities to traditional network infrastructures. It is backed by the Open Consortium.
2. Hardware vs. Software Logic
Hardwired ASIC (InfiniBand): The protocol logic is baked directly into the silicon. This “Native” approach ensures consistent performance with minimal jitter.
Firmware & OS Dependent (RoCE v2): Relies more heavily on the NIC’s firmware and operating system configurations, making it more flexible but potentially more complex to stabilize.
3. Data Transfer Efficiency
Ultra-low Latency (InfiniBand): Utilizes Cut-through switching, where the switch starts forwarding the packet as soon as the destination address is read, without waiting for the full packet to arrive.
Encapsulation Overhead (RoCE v2): Because it runs on Ethernet, it must wrap RDMA data in UDP/IP/Ethernet headers. This adds “overhead” (extra data bits) and processing time compared to the leaner InfiniBand frames.
4. Reliability and Loss Management
Lossless by Design (InfiniBand): It uses a credit-based flow control mechanism at the hardware level, ensuring that a sender never transmits data unless the receiver has room to buffer it. This guarantees zero packet loss.
Tuning-Dependent (RoCE v2): Ethernet is natively “lossy.” To make RoCE v2 work effectively, the network must be “Converged” using complex features like PFC (Priority Flow Control) and ECN (Explicit Congestion Notification). Without precise tuning, performance can collapse during congestion.
5. Network Management
Subnet Manager (InfiniBand): Uses a centralized “Subnet Manager” to discover the topology and manage routing, which simplifies the management of massive GPU clusters.
Distributed Control (RoCE v2): Functions like a traditional IP network where routing and control are distributed across the switches and routers.
Comparison Summary
Feature
InfiniBand
RoCE v2
Primary Driver
Performance & Stability
Cost-effectiveness & Compatibility
Complexity
Plug-and-play (within IB ecosystem)
Requires expert-level network tuning
Latency
Absolute Lowest
Low (but higher than IB)
Scalability
High (specifically for AI/HPC)
High (standard Ethernet scalability)
Design & Logic:InfiniBand is a dedicated, hardware-native solution for ultra-low latency, whereas RoCE v2 adapts general-purpose Ethernet for RDMA through software-defined optimization and firmware.
Efficiency & Reliability:InfiniBand is “lossless by design” with minimal overhead via cut-through switching, while RoCE v2 incurs encapsulation overhead and requires precise network tuning to prevent packet loss.
Control & Management:InfiniBand utilizes centralized hardware-level management (Subnet Manager) for peak stability, while RoCE v2 relies on distributed software-level control over standard UDP/IP/Ethernet stacks.
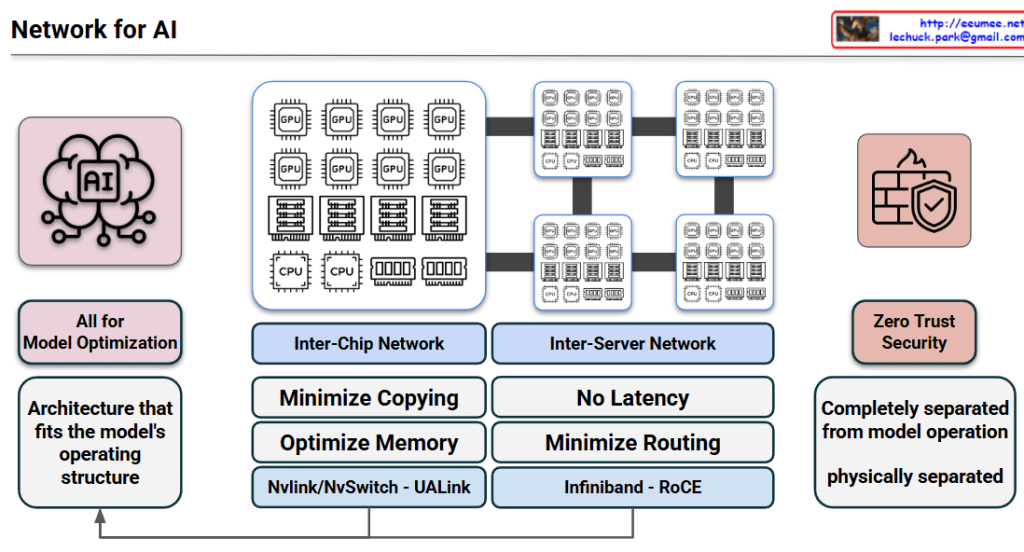
The primary goal is to create an “Architecture that fits the model’s operating structure.” Unlike traditional general-purpose data centers, AI infrastructure is specialized to handle the massive data throughput and synchronized computations required by LLMs (Large Language Models).
2. Hierarchical Network Design
The architecture is divided into two critical layers to handle different levels of data exchange:
A. Inter-Chip Network (Scale-Up)
This layer focuses on the communication between individual GPUs/Accelerators within a single server or node.
Key Goals: Minimize data copying and optimize memory utilization (Shared Memory/Memory Pooling).
UALink (Ultra Accelerator Link): The new open standard designed for scale-up AI clusters.
B. Inter-Server Network (Scale-Out)
This layer connects multiple server nodes to form a massive AI cluster.
Key Goals: Achieve “No Latency” (Ultra-low latency) and minimize routing overhead to prevent bottlenecks during collective communications (e.g., All-Reduce).
Technologies: * InfiniBand: A lossless, high-bandwidth fabric preferred for its low CPU overhead.
RoCE (RDMA over Converged Ethernet): High-speed Ethernet that allows direct memory access between servers.
3. Zero Trust Security & Physical Separation
A unique aspect of this architecture is the treatment of security.
Operational Isolation: The security and management plane is completely separated from the model operation plane.
Performance Integrity: By being physically separated, security protocols (like firewalls or encryption inspection) do not introduce latency into the high-speed compute fabric where the model runs. This ensures that a “Zero Trust” posture does not degrade training or inference speed.
4. Architectural Feedback Loop
The arrow at the bottom indicates a feedback loop: the performance metrics and requirements of the inter-chip and inter-server networks directly inform the ongoing optimization of the overall architecture. This ensures the platform evolves alongside advancing AI model structures.
The architecture prioritizes model-centric optimization, ensuring infrastructure is purpose-built to match the specific operating requirements of large-scale AI workloads.
It employs a dual-tier network strategy using Inter-chip (NVLink/UALink) for memory efficiency and Inter-server (InfiniBand/RoCE) for ultra-low latency cluster scaling.
Zero Trust security is integrated through complete physical separation from the compute fabric, allowing for robust protection without causing any performance bottlenecks.