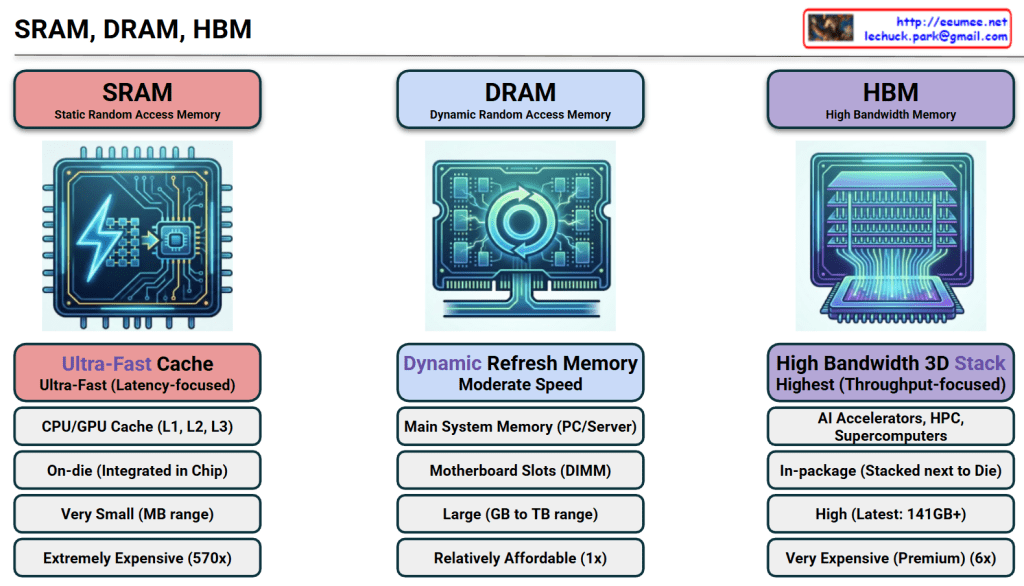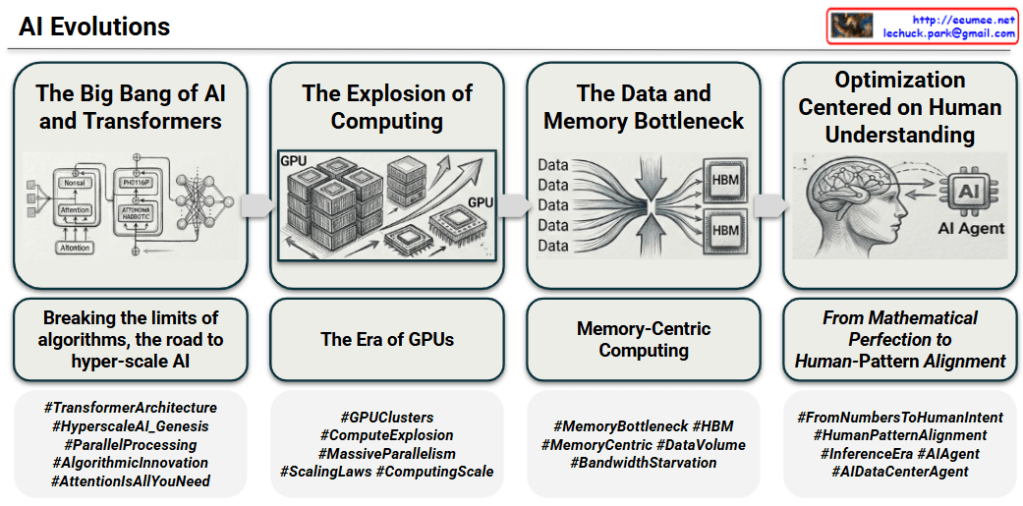
AI Evolutions: A Chronological Journey of Artificial Intelligence
This infographic provides a clear and structured four-stage chronological timeline of the evolution of artificial intelligence technology. Each stage is presented with a main title, a diagram illustrating key concepts, a descriptive sub-header, and a set of relevant hashtags, allowing for a comprehensive understanding of the technical trends.
Here is a detailed phase-by-phase interpretation:
1. The Big Bang of AI and Transformers
- Interpretation: This first phase metaphorically compares the arrival of the Transformer architecture to the “big bang” of a new AI era, highlighting its foundational importance. It marks the shift in algorithmic innovation.
- Diagram: Shows the core structure of the Transformer architecture. A specific box is highlighted for the ‘Attention’ mechanism, identifying it as the critical breakthrough. It depicts multi-layer neural networks and how they process data to understand context.
- Sub-Header: “Breaking the limits of algorithms, the road to hyper-scale AI.”
- Detailed Meaning: This signifies that the Transformer overcame the sequential processing limitations of previous algorithms. The parallel processing enabled by the ‘Attention’ mechanism maximized computational efficiency, laying the groundwork for developing massive, hyper-scale AI models.
- Key Hashtags (from image): #TransformerArchitecture, #ParallelProcessing, #AttentionIsAllYouNeed, #HyperscaleAI_Genesis, #AlgorithmicInnovation
2. The Explosion of Computing
(Fast Computing)
- Interpretation: As the size of AI models grew exponentially following the Transformer’s success, this phase describes the explosive increase in computational power required for training them. The focus is on hardware scaling.
- Diagram: Illustrates clusters and stacks of GPUs (Graphics Processing Units) and chip dies. Multiple GPUs are shown in a chassis, with a waterfall of individual chips symbolizing vast hardware resources and massive processing scale.
- Sub-Header: “The Era of GPUs.”
- Detailed Meaning: The computation demands for hyper-scale models skyrocketed, leading to the establishment of GPU clusters as the backbone of AI computing, given their optimization for large-scale parallel tasks. This highlights that model size and compute power increase together according to scaling laws.
- Key Hashtags (from image): #ComputeExplosion, #MassiveParallelism, #ScalingLaws, #GPUClusters, #ComputingScale
3. The Data and Memory Bottleneck
(Volume of Data)
- Interpretation: With computing power reaching unprecedented levels, a new critical bottleneck emerged. This phase identifies that memory bandwidth cannot keep pace with processing speeds, causing a significant performance limitation.
- Diagram: Visualizes countless data streams (labeled “Data”) converging into a tight funnel-like bottleneck, creating a “Funnel Effect.” Adjacent to the funnel are two diagrams of high-performance ‘High Bandwidth Memory)’ chips, indicating the technological solution.
- Sub-Header: “Memory-Centric Computing.”
- Detailed Meaning: This addresses the “Von Neumann Bottleneck,” which has become severe in AI workloads. While processor performance grew rapidly, memory bandwidth improvement lagged, creating “Bandwidth Starvation.” To overcome this, the paradigm must shift to “memory-centric computing,” using advanced technologies like HBM to feed data to processors quickly.
- Key Hashtags (from image): #MemoryBottleneck, #HBM, #BandwidthStarvation, #MemoryCentric, #DataVolume
4. Optimization Centered on Human Understanding
- Interpretation: Moving beyond raw technical performance (computation and memory), the final phase emphasizes optimizing AI to align with human intent, values, and understanding. The focus shifts to human-centric intelligence.
- Diagram: Depicts a human brain interacting with an AI chip. An arrow goes from the brain to the AI chip, and another arrow returns from the AI chip, which includes the text “AI Agent,” back to a human head silhouette. This symbolizes an autonomous AI agent that learns from human brain patterns.
- Sub-Header (italicized): “From Mathematical Perfection to Human-Pattern Alignment.”
- Detailed Meaning: The crux is no longer just mathematical correctness but “alignment.” AI must produce results that humans can understand and accept. This leads to the evolution of self-governing “AI Agents” and a shift from purely technology-driven optimization to human-centric value creation.
- Key Hashtags (from image): #FromNumbersToHumanIntent, #HumanPatternAlignment, #AIAgent, #InferenceEra, #AIDataCenterAgent
Summary
This infographic provides a powerful narrative of AI evolution through four clear technological and philosophical paradigm shifts: Algorithmic Innovation (Transformer) -> Computing Explosion (GPU) -> Memory Bottleneck Solution () -> Human-Centered AI Agents. It concludes that the future of AI lies not just in being more powerful but in being deeply aligned with human understanding and purpose. The contact info in the corner adds a touch of professional expertise.
#AIEvolution #TransformerArchitecture #AIInfrastructure #ComputeExplosion #GPU_Computing #HighBandwidthMemory #MemoryBottleneck #DataStarvation #VonNeumannBottleneck #HumanAICoexistence #HumanAICollaboration #AIAlignment #ExplainableAI (XAI) #EthicalAI #HumanCentricAI #TechEvolution #FutureOfWork #AI_Strategy