LLM-Based Multi-Datacenter Operation System
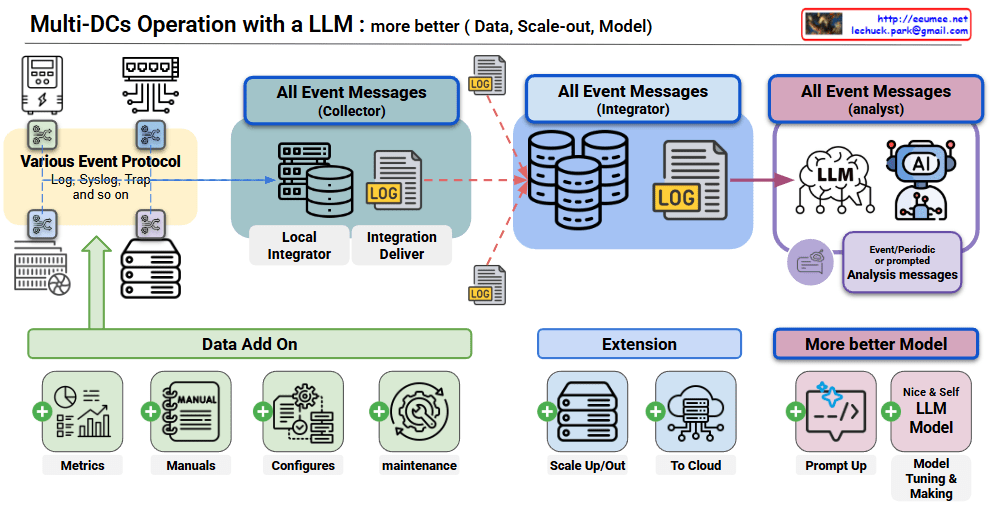
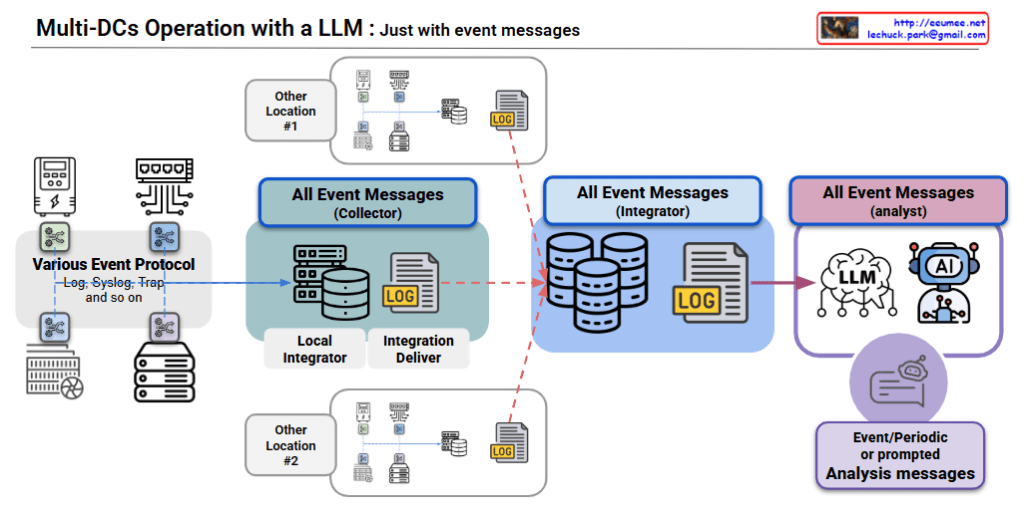
System Architecture
3-Stage Processing Pipeline: Collector → Integrator → Analyst
- Event collection from various protocols
- Data normalization through local integrators
- Intelligent analysis via LLM/AI analyzers
- RAG data expansion through bottom Data Add-On modules
Core Functions
1. Time-Based Event Aggregation Analysis
- 60-second intervals (adjustable) for event bundling
- Comprehensive situational analysis instead of individual alarms
- LLM queries with predefined prompts
Effectiveness:
- ✅ Resolves alarm fatigue and enables correlation analysis
- ✅ Improves operational efficiency through periodic comprehensive reports
- ⚠️ Potential delay in immediate response to critical issues ( -> Using a legacy/local monitoring system )
2. RAG-Based Data Enhancement
- Extension data: Metrics, manuals, configurations, maintenance records
- Reuse of past analysis results as learning data
- Improved accuracy through domain-specific knowledge accumulation
Effectiveness:
- ✅ Continuous improvement of analysis quality and increased automation
- ✅ Systematization of operational knowledge and organizational capability enhancement
Innovative Value
- Paradigm Shift: Reactive → Predictive/Contextual analysis
- Operational Burden Reduction: Transform massive alarms into meaningful insights
- Self-Evolution: Continuous learning system through RAG framework
Executive Summary: This system overcomes the limitations of traditional individual alarm approaches and represents an innovative solution that intelligentizes datacenter operations through time-based event aggregation and LLM analysis. As a self-evolving monitoring system that continuously learns and develops through RAG-based data enhancement, it is expected to dramatically improve operational efficiency and analysis accuracy.
With Claude