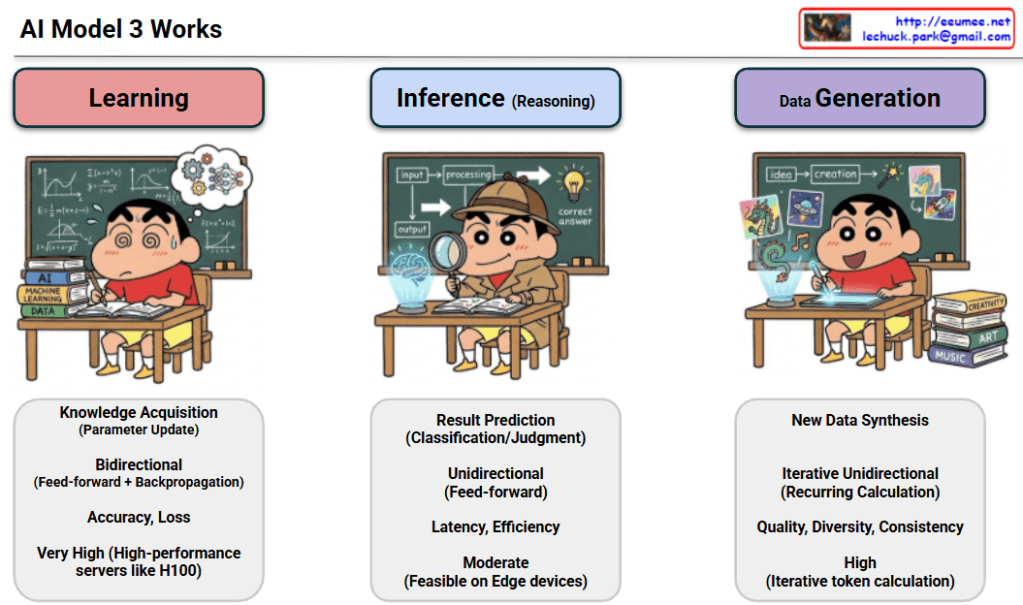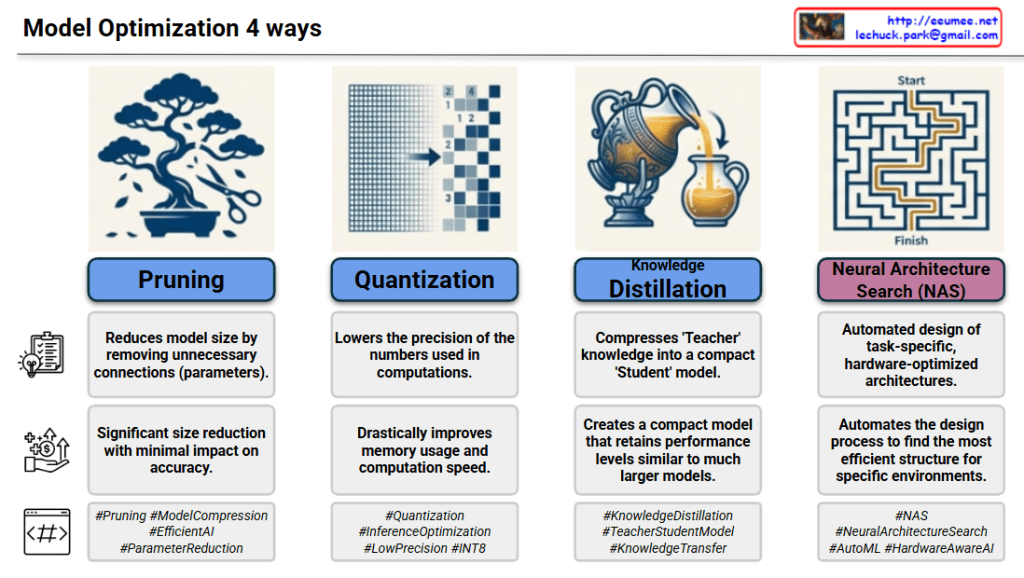
4 Key Methods of Model Optimization
1. Pruning
- Analogy: Trimming a bonsai tree by cutting off unnecessary branches.
- Description: This method involves removing redundant or non-essential connections (parameters) within a neural network that do not significantly contribute to the output.
- Key Benefit: It leads to a significant reduction in model size with minimal impact on accuracy.
2. Quantization
- Analogy: Reducing the resolution of a grid to make it simpler.
- Description: This technique lowers the numerical precision of the weights and activations (e.g., converting 32-bit floating-point numbers to 8-bit integers).
- Key Benefit: It drastically improves memory efficiency and increases computation speed, which is essential for mobile or edge devices.
3. Knowledge Distillation
- Analogy: Pouring the contents of a large pitcher into a smaller, more efficient cup.
- Description: A large, complex pre-trained model (the Teacher) transfers its “knowledge” to a smaller, more compact model (the Student).
- Key Benefit: The Student model achieves performance levels close to the Teacher model but remains much faster and lighter.
4. Neural Architecture Search (NAS)
- Analogy: Finding the fastest path through a complex maze.
- Description: Instead of human engineers designing the network, algorithms automatically search for and design the most optimal architecture for a specific task or hardware.
- Key Benefit: It automates the creation of the most efficient structure tailored to specific environments or performance requirements.
Summary
- Efficiency: These techniques reduce AI model size and power consumption while maintaining high performance.
- Deployment: Optimization is crucial for running advanced AI on hardware-constrained devices like smartphones and IoT sensors.
- Automation: Methods like NAS move beyond manual design to find the mathematically perfect structure for any given hardware.
#AI #DeepLearning #ModelOptimization #Pruning #Quantization #KnowledgeDistillation #NAS #EdgeAI #EfficientAI #MachineLearning
With Gemini