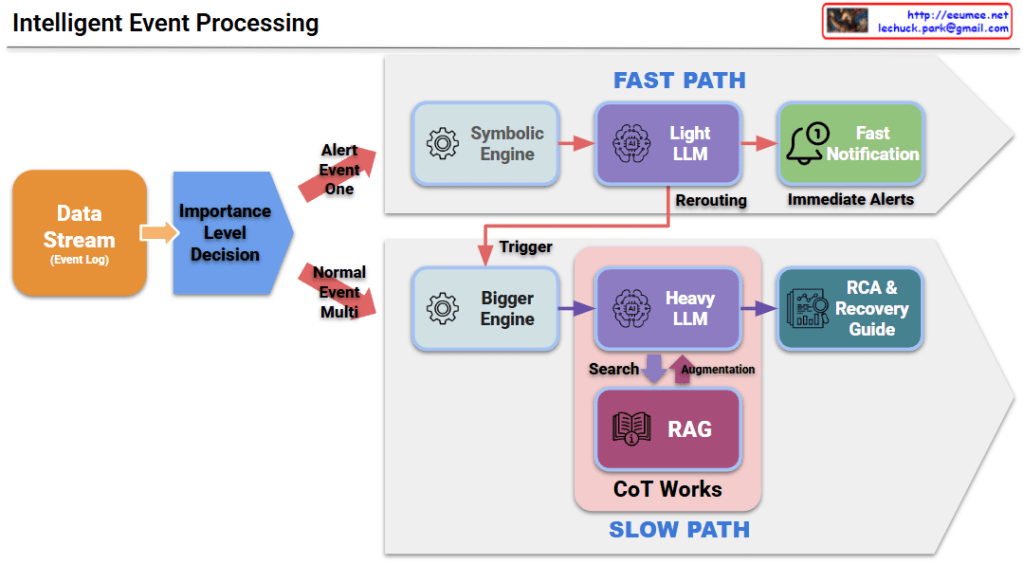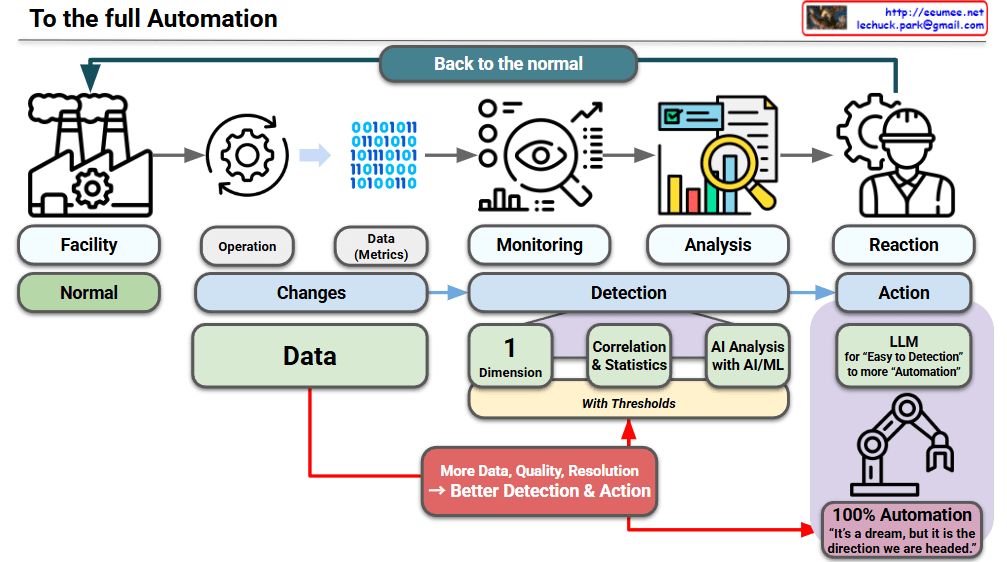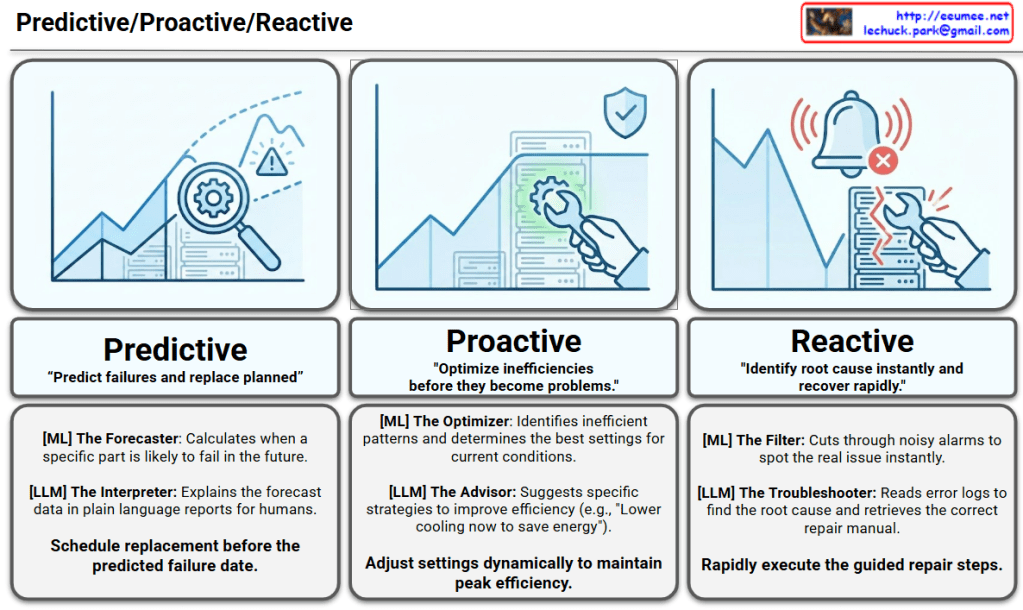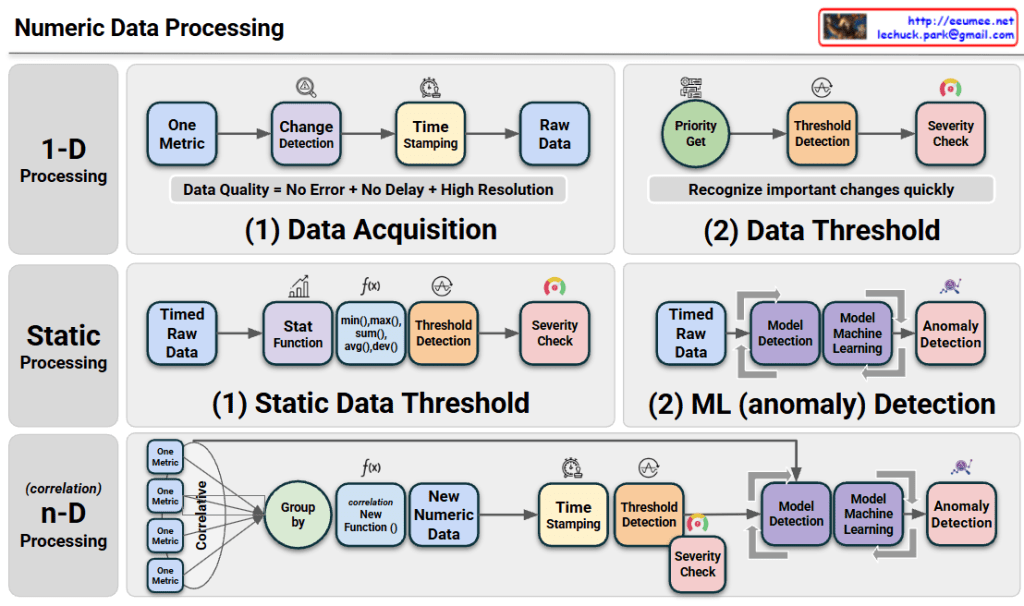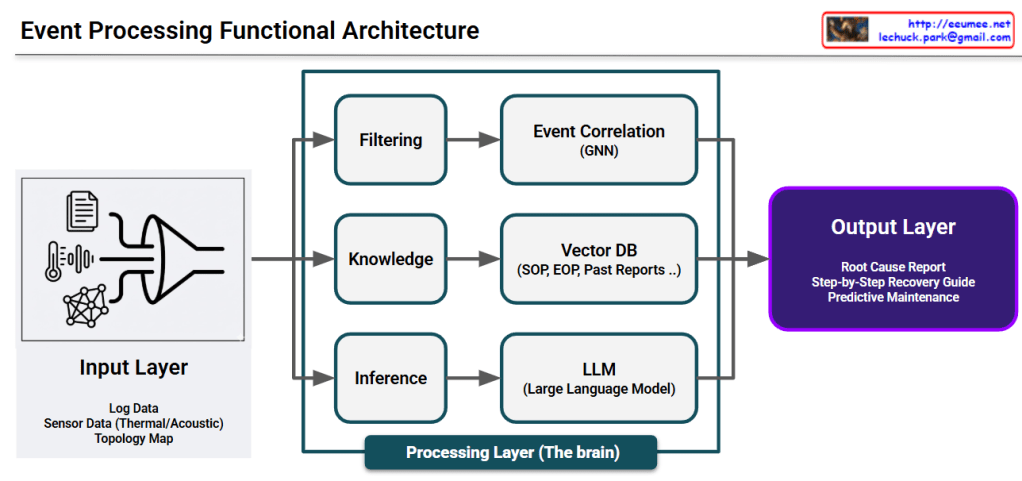
This image illustrates a Data Processing Pipeline (Architecture) where raw data is ingested, analyzed through an AI engine, and converted into actionable business intelligence.
## Image Interpretation: AI-Driven Data Pipeline
### 1. Input Layer (Left: Data Ingestion)
This represents the raw data collected from various sources within the infrastructure:
- Log Data (Document Icon): System logs and event records that capture operational history.
- Sensor Data (Thermometer & Waveform Icons): Real-time monitoring of physical environments, specifically focusing on Thermal (heat) and Acoustic (noise) patterns.
- Topology Map (Network Icon): The structural map of equipment and their interconnections, providing context for how data flows through the system.
### 2. Integration & Processing (Center: The AI Funnel)
- The Funnel/Pipe Shape: This symbolizes the process of data fusion and refinement. It represents different data types being standardized and processed through an AI model or analytics engine to filter out noise and identify patterns.
### 3. Output Layer (Right: Actionable Insights)
The final results generated by the analysis, designed to provide immediate value to operators:
- Root Cause Report (Document with Magnifying Glass): Identifies the underlying reason for a specific failure or anomaly.
- Step-by-Step Recovery Guide (Checklist with Arrows): Provides a sequential, automated, or manual procedure to restore the system to a healthy state.
- Predictive Maintenance (Gear with Upward Arrow): Utilizes historical trends to predict potential failures before they occur, optimizing maintenance schedules and reducing downtime.
# Summary
The diagram effectively visualizes the transition from complex raw data to actionable intelligence. It highlights the core value of an AI-driven platform: reducing cognitive load for human operators by providing clear, data-backed directions for maintenance and recovery.
#AI #DataCenter #PredictiveMaintenance #DataAnalytics #SmartInfrastructure #RootCauseAnalysis #DigitalTransformation #OperationsOptimization
With Gemini