

The Computing for the Fair Human Life.


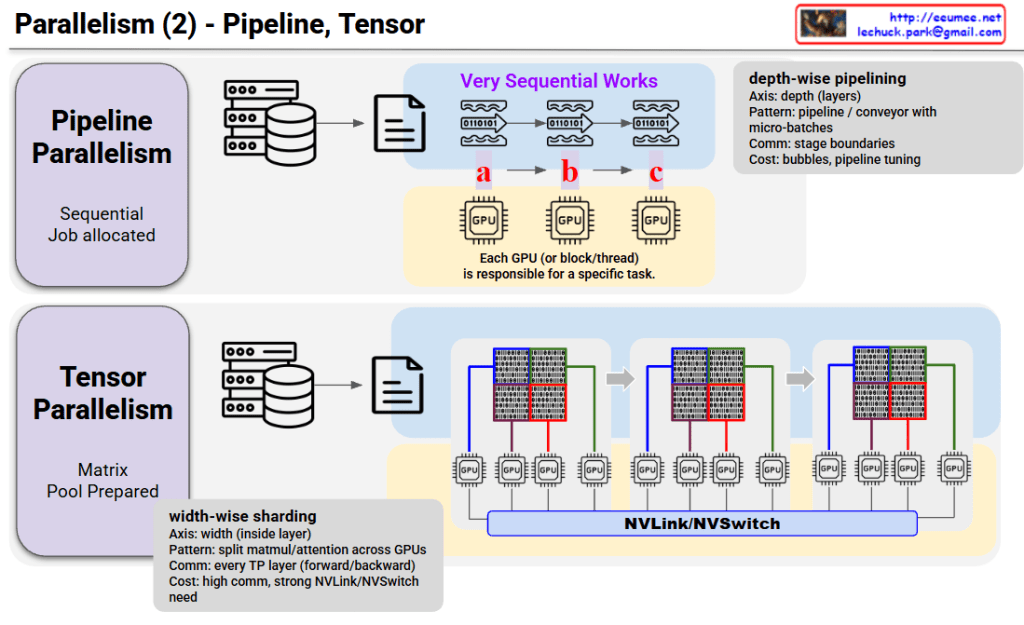
This image compares two parallel processing techniques: Pipeline Parallelism and Tensor Parallelism.
Core Concept:
Characteristics:
How it works: Data flows sequentially like waves, with each GPU processing its assigned stage before passing to the next GPU.
Core Concept:
Characteristics:
How it works: Large matrices are divided into chunks, with each GPU processing simultaneously while continuously communicating via NVLink/NVSwitch.
| Aspect | Pipeline | Tensor |
|---|---|---|
| Split Method | Layer-wise (vertical) | Within-layer (horizontal) |
| GPU Role | Different tasks | Parts of same task |
| Communication | Low (stage boundaries) | High (every layer) |
| Hardware Needs | Standard | High-speed interconnect required |
Pipeline Parallelism splits models vertically by layers with sequential processing and low communication cost, while Tensor Parallelism splits horizontally within layers for parallel processing but requires high-speed interconnects. These two techniques are often combined in training large-scale AI models to maximize efficiency.
#ParallelComputing #DistributedTraining #DeepLearning #GPUOptimization #MachineLearning #ModelParallelism #AIInfrastructure #NeuralNetworks #ScalableAI #HPC
With Claude
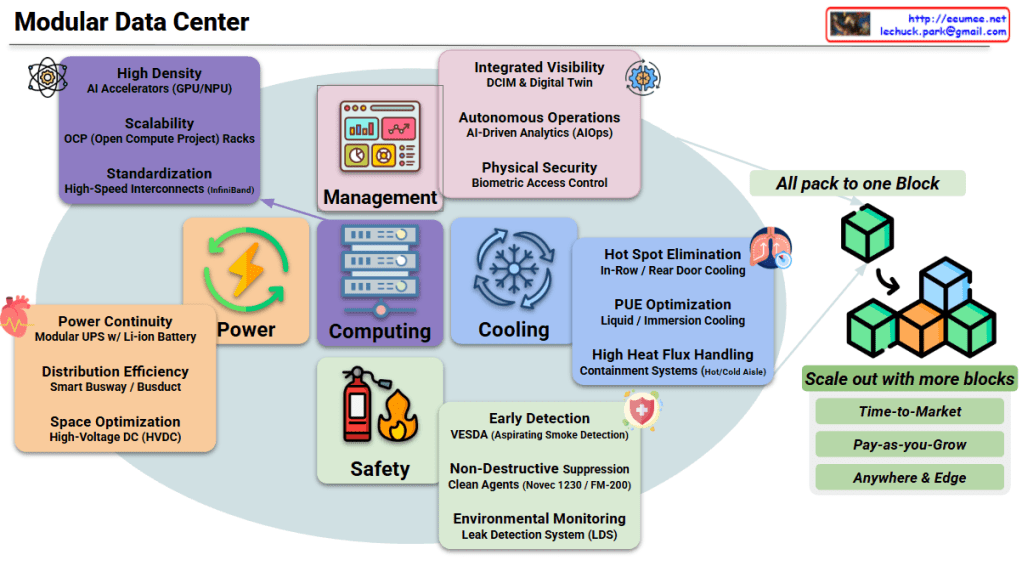
This image illustrates a comprehensive Modular Data Center architecture designed specifically for modern AI/ML workloads, showcasing integrated systems and their key capabilities.
Traditional data centers take 18-24 months to build, but AI demands are exploding NOW. Modular DCs deploy in 3-6 months, allowing organizations to capture market opportunities and respond to rapidly evolving AI compute requirements without lengthy construction cycles.
AI workloads generate 3-5x more heat per rack (30-100kW) compared to traditional servers (5-10kW). Modular designs integrate advanced liquid cooling and containment systems from day one, purpose-built to handle GPU/NPU thermal density that would overwhelm conventional infrastructure.
AI projects often start experimental but can scale exponentially. The “pay-as-you-grow” model lets organizations deploy one block initially, then add capacity incrementally as models grow—avoiding massive upfront capital while maintaining consistent architecture and avoiding stranded capacity.
AI inference increasingly happens at the edge for latency-sensitive applications (autonomous vehicles, smart manufacturing). Modular DCs’ compact, self-contained design enables AI deployment anywhere—from remote locations to urban centers—with full data center capabilities in a standardized package.
AI workloads demand maximum PUE efficiency to manage operational costs. Modular DCs achieve PUE of 1.1-1.3 through integrated cooling optimization, HVDC power distribution, and AI-driven management—versus 1.5-2.0 in traditional facilities—critical when GPU clusters consume megawatts.
📦 “All pack to one Block” – Complete infrastructure in pre-integrated modules 🧩 “Scale out with more blocks” – Linear, predictable expansion without redesign
Modular Data Centers are essential for AI infrastructure because they deliver pre-integrated, high-density compute, power, and cooling blocks that deploy 4-6x faster than traditional builds, enabling organizations to rapidly scale GPU clusters from prototype to production while maintaining optimal PUE efficiency and avoiding massive upfront capital investment in uncertain AI workload trajectories.
The modular approach specifically addresses AI’s unique challenges: extreme thermal density (30-100kW/rack), explosive demand growth, edge deployment requirements, and the need for liquid cooling integration—all packaged in standardized blocks that can be deployed anywhere in months rather than years.
This architecture transforms data center infrastructure from a multi-year construction project into an agile, scalable platform that matches the speed of AI innovation, allowing organizations to compete in the AI economy without betting the company on fixed infrastructure that may be obsolete before completion.
#ModularDataCenter #AIInfrastructure #DataCenterDesign #EdgeComputing #LiquidCooling #GPUComputing #HyperscaleAI #DataCenterModernization #AIWorkloads #GreenDataCenter #DCInfrastructure #SmartDataCenter #PUEOptimization #AIops #DigitalTwin #EdgeAI #DataCenterInnovation #CloudInfrastructure #EnterpriseAI #SustainableTech
With Claude

This image compares two major parallelization strategies used for training large language models (LLMs).
Structure:
Characteristics:
Structure:
Characteristics:
| Aspect | Data Parallelism | Expert Parallelism |
|---|---|---|
| Model Division | Full model replication | Model divided into experts |
| Data Division | Batch-wise | Layer/token-wise |
| Communication Pattern | Gradient All-Reduce | Token All-to-All |
| Scalability | Proportional to data size | Proportional to expert count |
| Efficiency | Dense computation | Sparse computation (conditional activation) |
These two approaches are often used together in practice, enabling ultra-large-scale model training through hybrid parallelization strategies.
Data Parallelism replicates the entire model across GPUs and divides the training data, synchronizing gradients after each step – simple but memory-limited. Expert Parallelism divides the model into specialized experts and routes tokens dynamically, enabling massive scale through sparse activation. Modern systems combine both strategies to train trillion-parameter models efficiently.
#MachineLearning #DeepLearning #LLM #Parallelism #DistributedTraining #DataParallelism #ExpertParallelism #MixtureOfExperts #MoE #GPU #ModelTraining #AIInfrastructure #ScalableAI #NeuralNetworks #HPC

This image outlines the key technologies and performance efficiency of the DeepSeek-v3 model, which utilizes the Mixture-of-Experts (MoE) architecture. It is divided into the architecture diagram/cost table on the left and four key technical features on the right.
The diagram illustrates how the model processes data:
This section explains how DeepSeek-v3 overcomes the limitations of existing MoE models:
The comparison highlights the massive efficiency gain over dense models:
#DeepSeek #AI #MachineLearning #MoE #MixtureOfExperts #LLM #DeepLearning #TechTrends #ArtificialIntelligence #ModelArchitecture
With Gemini
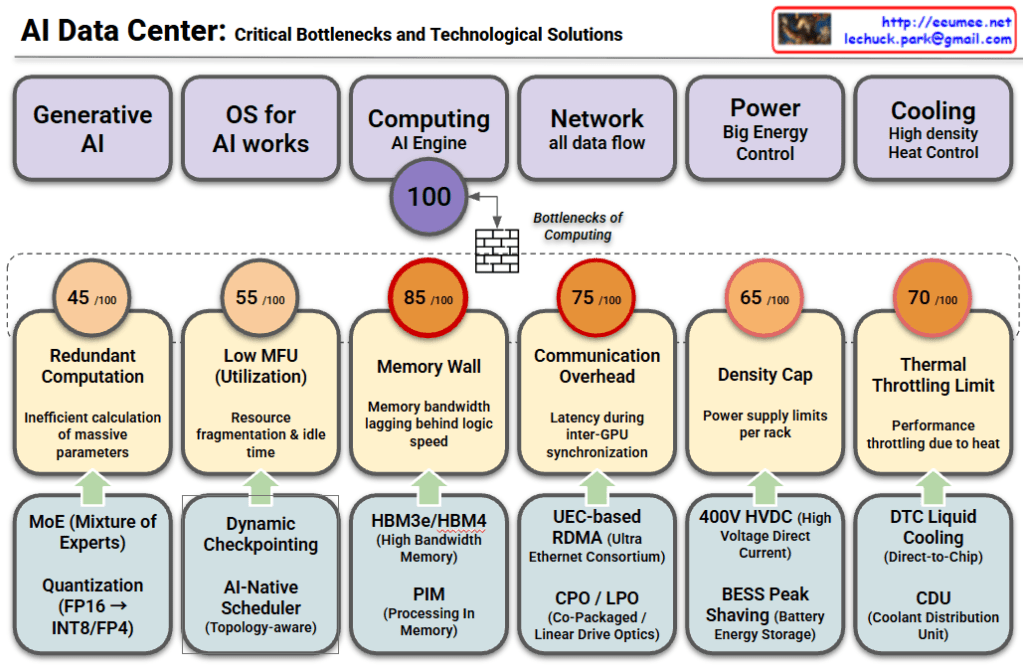
This chart analyzes the major challenges facing modern AI Data Centers across six key domains. It outlines the [Domain] → [Bottleneck/Problem] → [Solution] flow, indicating the severity of each bottleneck with a score out of 100.
#AIDataCenter #ArtificialIntelligence #MemoryWall #HBM #LiquidCooling #GenerativeAI #TechTrends #AIInfrastructure #Semiconductor #CloudComputing
With Gemini
