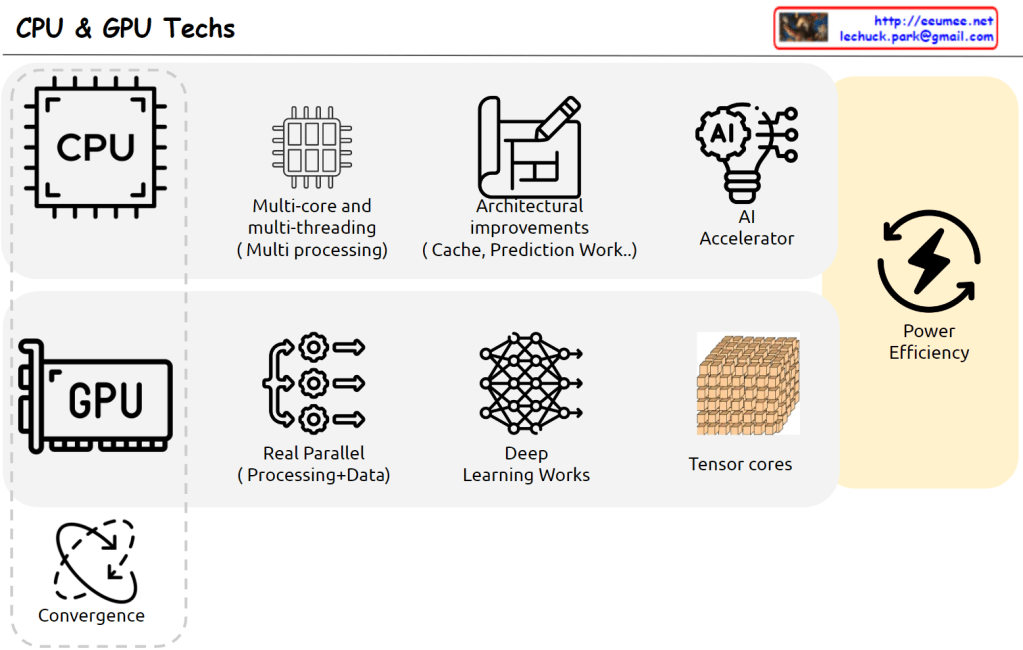
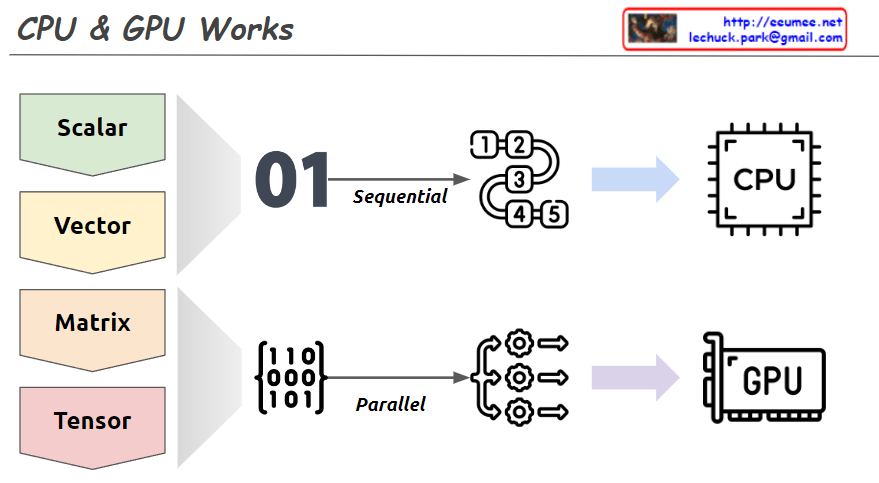
with a Claude’s Help
The network architecture demonstrates 3 levels of connectivity technologies:
- NVLink (Single node Parallel processing)
- Technology for directly connecting GPUs within a single node
- Supports up to 256 GPU connections
- Physical HBM (High Bandwidth Memory) sharing
- Optimized for high-performance GPU parallel processing within individual servers
- NVSwitch
- Switching technology that extends NVLink limitations
- Provides logical HBM sharing
- Key component for large-scale AI model operations
- Enables complete mesh network configuration between GPU groups
- Efficiently connects multiple GPU groups within One Box Server
- Targets large AI model workloads
- InfiniBand
- Network technology for server clustering
- Supports RDMA (Remote Direct Memory Access)
- Used for distributed computing and HPC (High Performance Computing) tasks
- Implements hierarchical network topology
- Enables large-scale cluster configuration across multiple servers
- Focuses on distributed and HPC workloads
This 3-tier architecture provides scalability through:
- GPU parallel processing within a single server (NVLink)
- High-performance connectivity between GPU groups within a server (NVSwitch)
- Cluster configuration between multiple servers (InfiniBand)
The architecture enables efficient handling of various workload scales, from small GPU tasks to large-scale distributed computing. It’s particularly effective for maximizing GPU resource utilization in large-scale AI model training and HPC workloads.
Key Benefits:
- Hierarchical scaling from single node to multi-server clusters
- Efficient memory sharing through both physical and logical HBM
- Flexible topology options for different computing needs
- Optimized for both AI and high-performance computing workloads
- Comprehensive solution for GPU-based distributed computing
This structure provides a complete solution from single-server GPU operations to complex distributed computing environments, making it suitable for a wide range of high-performance computing needs.