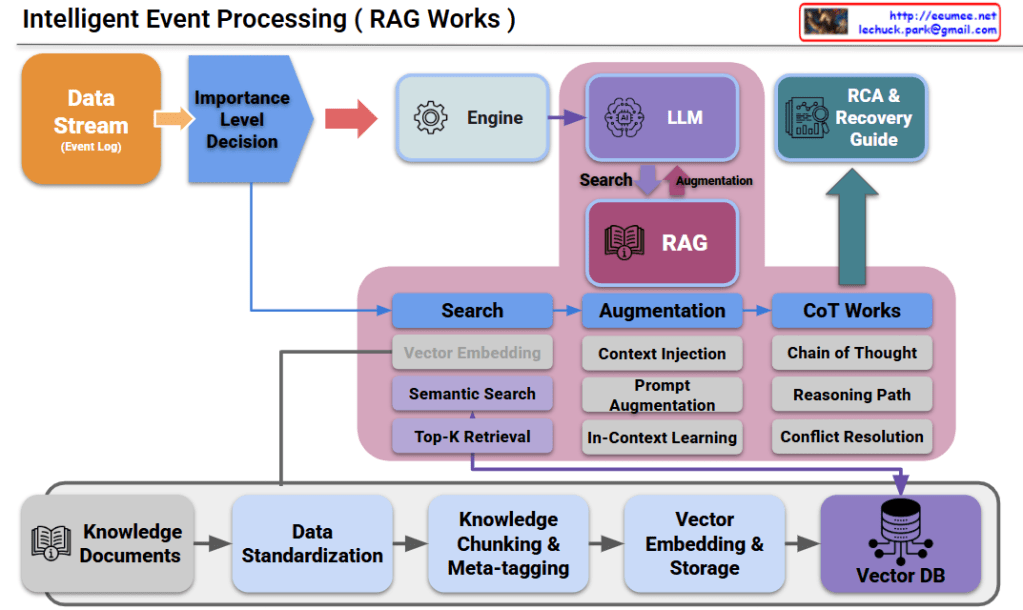
This diagram illustrates a sophisticated Intelligent Event Processing architecture that utilizes Retrieval-Augmented Generation (RAG) to transform raw system logs into actionable technical solutions.
Architecture Breakdown: Intelligent Event Processing (RAG Works)
1. Data Inflow & Prioritization
- Data Stream (Event Log): The system captures real-time logs and events.
- Importance Level Decision: Instead of processing every minor log, this “gatekeeper” identifies critical events, ensuring the AI engine focuses on high-priority issues.
2. The RAG Core (The Reasoning Engine)
This is the heart of the system (the pink area), where the AI analyzes the problem:
- Search (Retrieval): The system performs a Semantic Search and Top-K Retrieval to find the most relevant technical information from the Vector DB.
- Augmentation: It injects this retrieved context into the LLM (Large Language Model) via In-Context Learning, giving the model “temporary memory” of your specific systems.
- CoT Works (Chain of Thought): This is the “thinking” phase. It uses a Reasoning Path to analyze the data step-by-step and performs Conflict Resolution to ensure the final answer is logically sound.
3. Knowledge Management Pipeline
The bottom section shows how the system “learns”:
- Knowledge Documents: Technical manuals, past incident reports, and guidelines are collected.
- Standardization & Chunking: Data is broken down into manageable “chunks” and tagged with metadata.
- Vector DB: These chunks are converted into mathematical vectors (embeddings) and stored, allowing the engine to search for “meaning” rather than just keywords.
4. Final Output
- RCA & Recovery Guide: The ultimate goal. The system doesn’t just say there’s an error; it provides a Root Cause Analysis (RCA) and a step-by-step Recovery Guide to help engineers fix the issue immediately.
Summary
- Automated Intelligence: It’s an “IT First Responder” that converts raw system noise into precise, logical troubleshooting steps.
- Context-Aware Analysis: By combining RAG with Chain-of-Thought reasoning, the system “reads the manual” for you to solve complex errors.
- Data-Driven Recovery: The workflow bridges the gap between massive event logs and actionable Root Cause Analysis (RCA) to minimize downtime.
#AIOps #RAG #LLM #GenerativeAI #SystemArchitecture #DevOps #TechInsights #RootCauseAnalysis
With Gemini