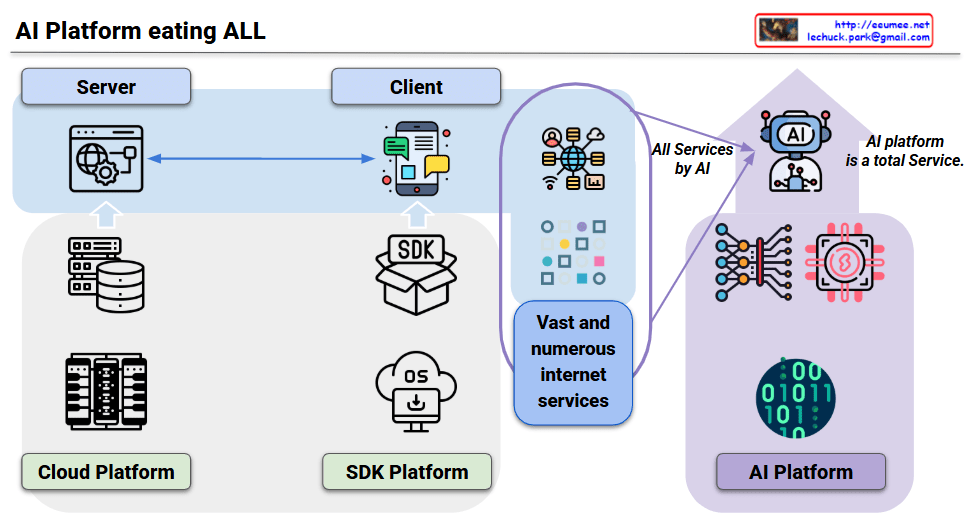
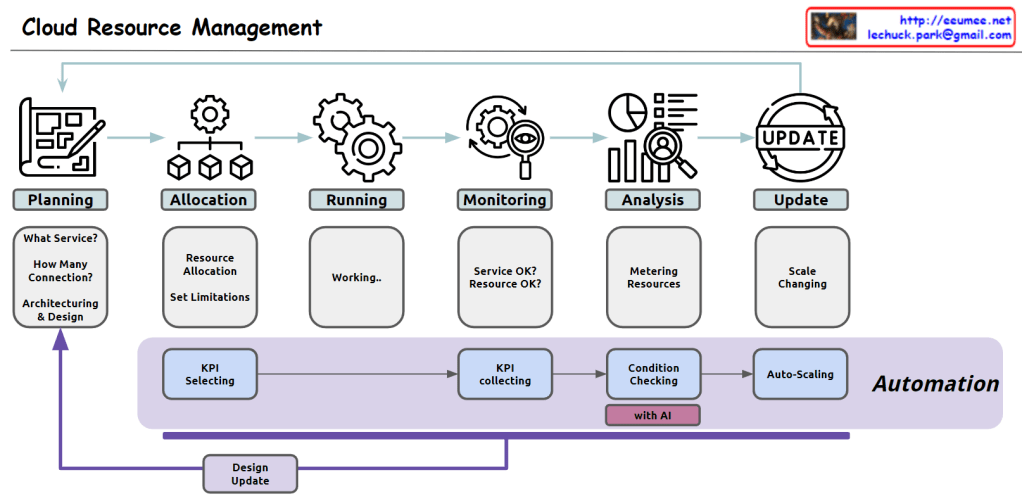
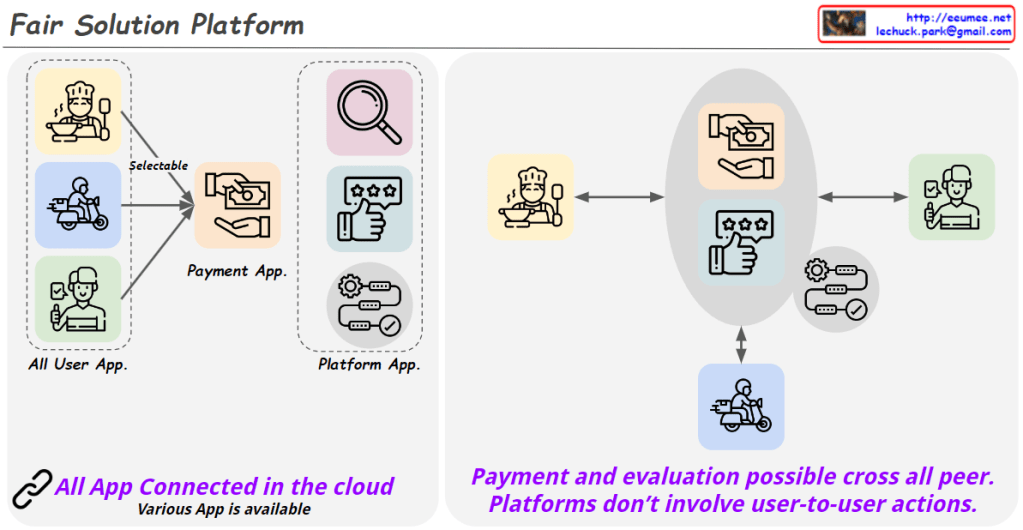
This diagram illustrates the “Computing Evolutions” from the perspective of data’s core attributes development.
Top: Core Data Properties
- Data: Foundation of digital information composed of 0s and 1s
- Store: Data storage technology
- Transfer: Data movement and network technology
- Computing: Data processing and computational technology
- AI Era: The convergence of all these technologies into the artificial intelligence age
Bottom: Evolution Stages Centered on Each Property
- Storage-Centric Era: Data Center
- Focus on large-scale data storage and management
- Establishment of centralized server infrastructure
- Transfer-Centric Era: Internet
- Dramatic advancement in network technology
- Completion of global data transmission infrastructure
- “Data Ready”: The point when vast amounts of data became available and accessible
- Computing-Centric Era: Cloud Computing
- Democratization and scalability of computing power
- Development of GPU-based parallel processing (blockchain also contributed)
- “Infra Ready”: The point when large-scale computing infrastructure was prepared
Convergence to AI Era With data prepared through the Internet and computing infrastructure ready through the cloud, all these elements converged to enable the current AI era. This evolutionary process demonstrates how each technological foundation systematically contributed to the emergence of artificial intelligence.
#ComputingEvolution #DigitalTransformation #AIRevolution #CloudComputing #TechHistory #ArtificialIntelligence #DataCenter #TechInnovation #DigitalInfrastructure #FutureOfWork #MachineLearning #TechInsights #Innovation
With Claude