
Learning is always happy 🙂
The Computing for the Fair Human Life.
Learning is always happy 🙂
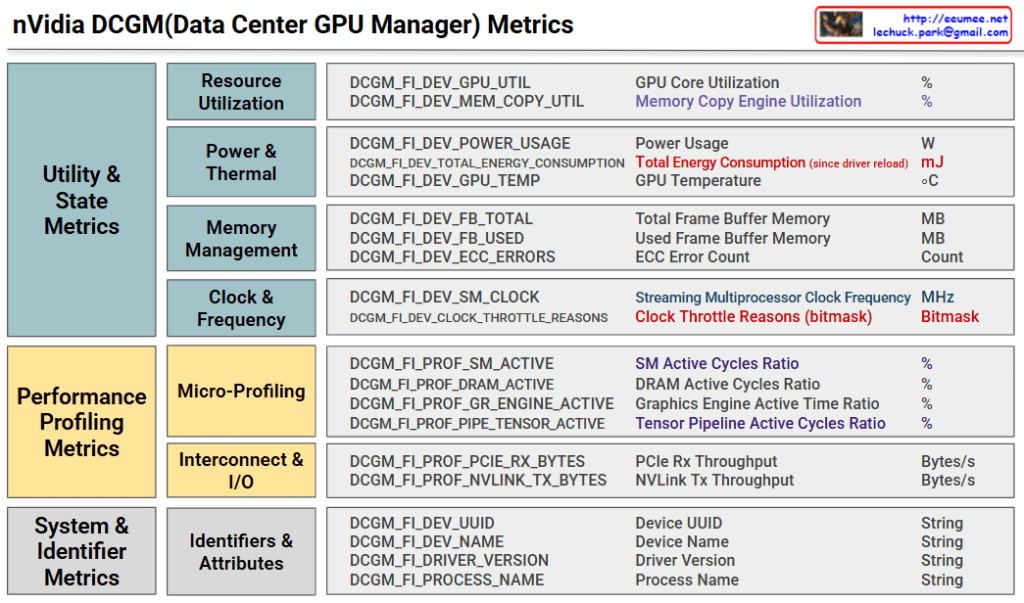
DCGM (Data Center GPU Manager) metrics provide comprehensive real-time monitoring for GPU cluster stability and performance optimization in data center environments. The system enables proactive issue detection and prevention through systematic metric categorization across utility states, performance profiling, and system identification. This integrated approach ensures uninterrupted high-performance operations while extending hardware lifespan and optimizing operational costs.
The Clock Throttle Reasons bitmask provides real-time detection of GPU performance limitations. Normal operation (0x00000000) maintains peak performance, while power limiting (0x00000001) triggers workload distribution to alternate GPUs. Thermal limiting (0x00000002) activates enhanced cooling and temporarily suspends heat-generating tasks. Complex limitation scenarios prompt emergency workload migration and hardware diagnostics to maintain system stability.
With Claude

This diagram illustrates two main power switching methods used in electrical systems: ATS (Automatic Transfer Switch) and STS (Static Transfer Switch).
Location: Switchgear Area (Power Distribution Board)
Characteristics:
Location: Panelboard Area (Distribution Panel)
Characteristics:
Summary: This diagram shows a redundant power system where ATS provides cost-effective backup power switching while STS offers near-instantaneous transfer for critical loads. Both systems work together with UPS backup to ensure continuous power supply to servers and sensitive equipment.
With Claude
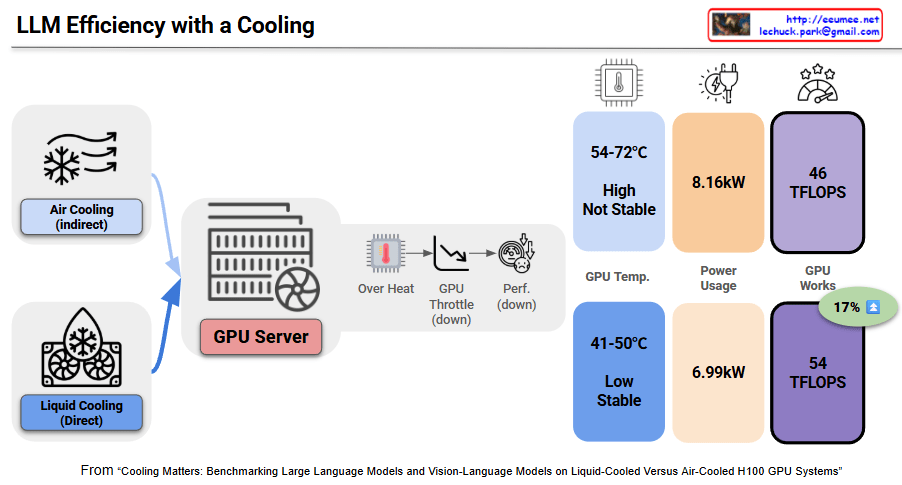
This image demonstrates the critical impact of cooling stability on both LLM performance and energy efficiency in GPU servers through benchmark results.
Problems with Unstable Air Cooling:
Energy Efficiency Impact:
Temperature Stability Achievement:
Energy Efficiency Improvement:
Advanced cooling systems can achieve energy savings ranging from 17% to 23% compared to traditional methods. This benchmark paradoxically shows that proper cooling investment dramatically improves overall energy efficiency.
Unstable cooling triggers thermal throttling that simultaneously degrades LLM performance while increasing power consumption, creating a dual efficiency loss. Stable liquid cooling achieves 17% performance gains and 14% power savings simultaneously, improving energy efficiency by 38%. In AI infrastructure, adequate cooling investment is essential for optimizing both performance and energy efficiency.
With Claude
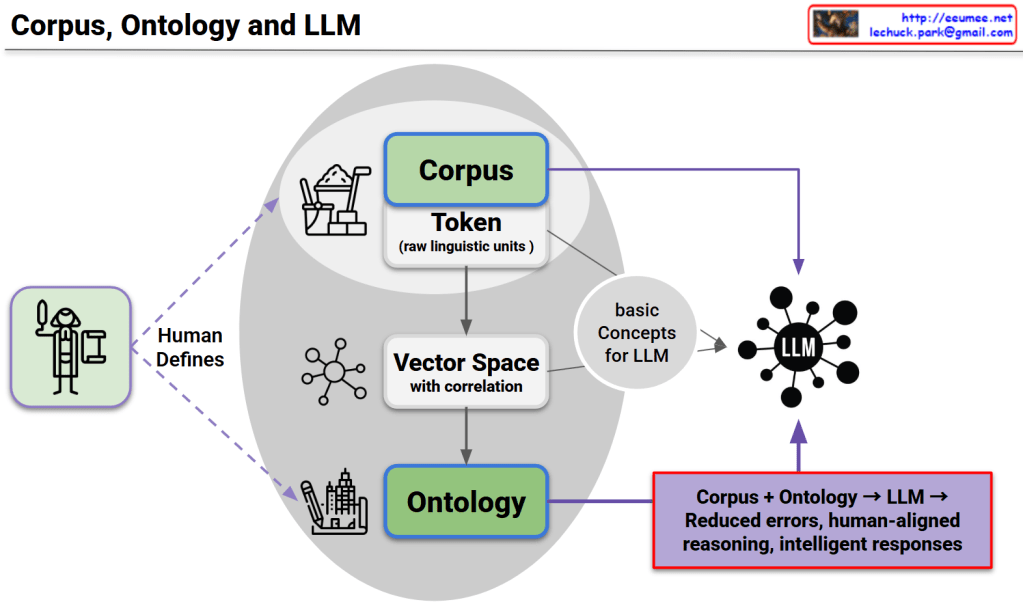
This diagram presents a unified framework consisting of three core structures, their interconnected relationships, and complementary utilization as the foundation for LLM advancement.
1. Corpus Structure
2. Ontology Structure
3. LLM Structure
Each structure compensates for the limitations of others:
This triangular complementary structure overcomes the limitations of single approaches to achieve:
This represents the core foundation for next-generation LLM development.
With Claude


