


The Computing for the Fair Human Life.
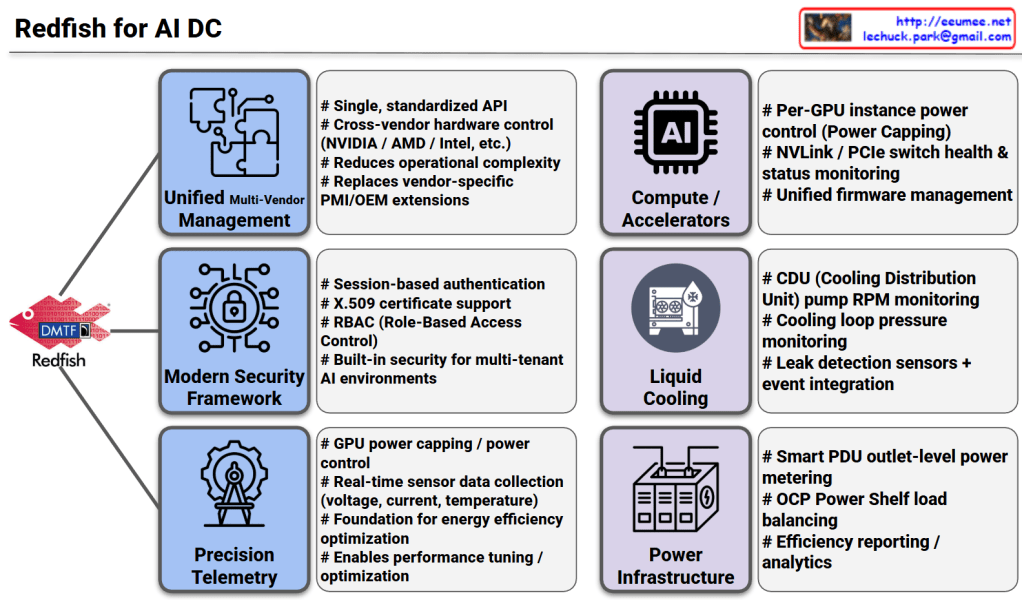
This image illustrates the pivotal role of the Redfish API (developed by DMTF) as the standardized management backbone for modern AI Data Centers (AI DC). As AI workloads demand unprecedented levels of power and cooling, Redfish moves beyond traditional server management to provide a unified framework for the entire infrastructure stack.
For an AI DC Optimization Architect, Redfish is the essential “language” that enables Software-Defined Infrastructure. By moving away from manual, siloed hardware management and toward this API-driven approach, data centers can achieve the extreme automation required to shift OPEX structures predominantly toward electricity costs rather than labor.
#AIDataCenter #RedfishAPI #DMTF #DataCenterInfrastructure #GPUComputing #LiquidCooling #SustainableIT #SmartPDU #OCP #InfrastructureAutomation #TechArchitecture #EnergyEfficiency
With Gemini
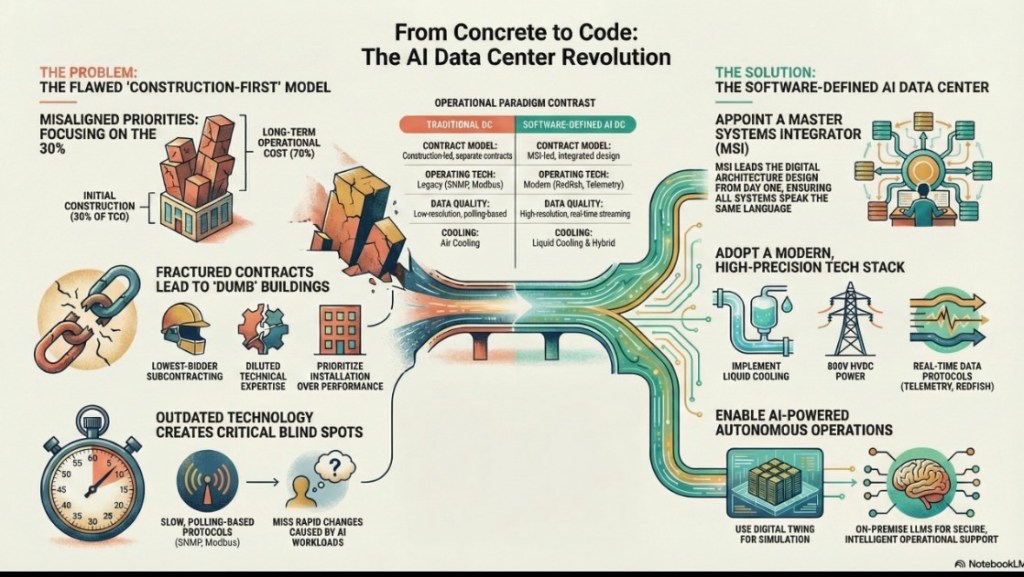
A software-defined data center is not an option, it’s a necessity. And here’s how to achieve it…
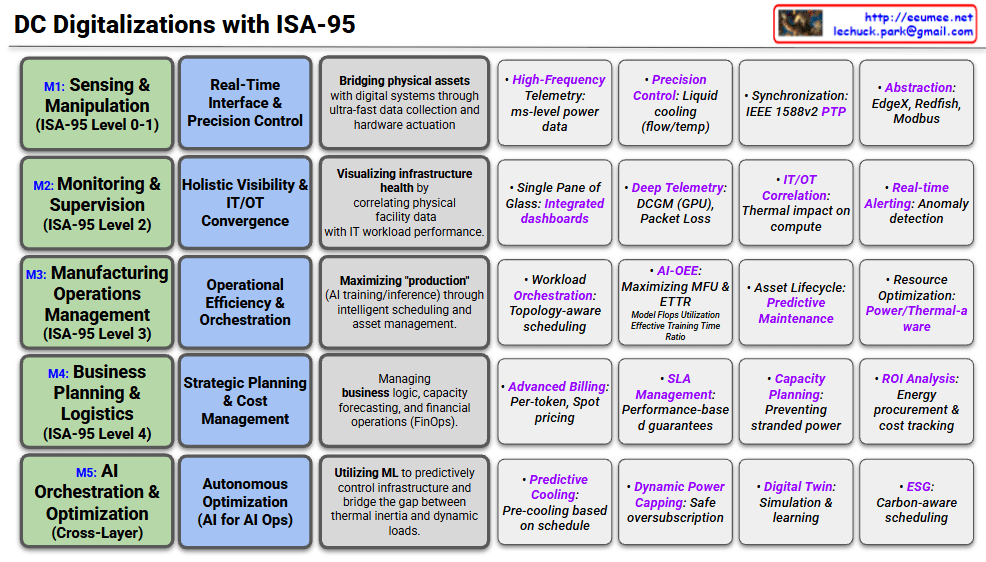
#DataCenter #DigitalTransformation #ISA95 #AIOps #SmartFactory #ITOTConvergence #SustainableIT #GPUOrchestration #FinOps #LiquidCooling
With Gemini
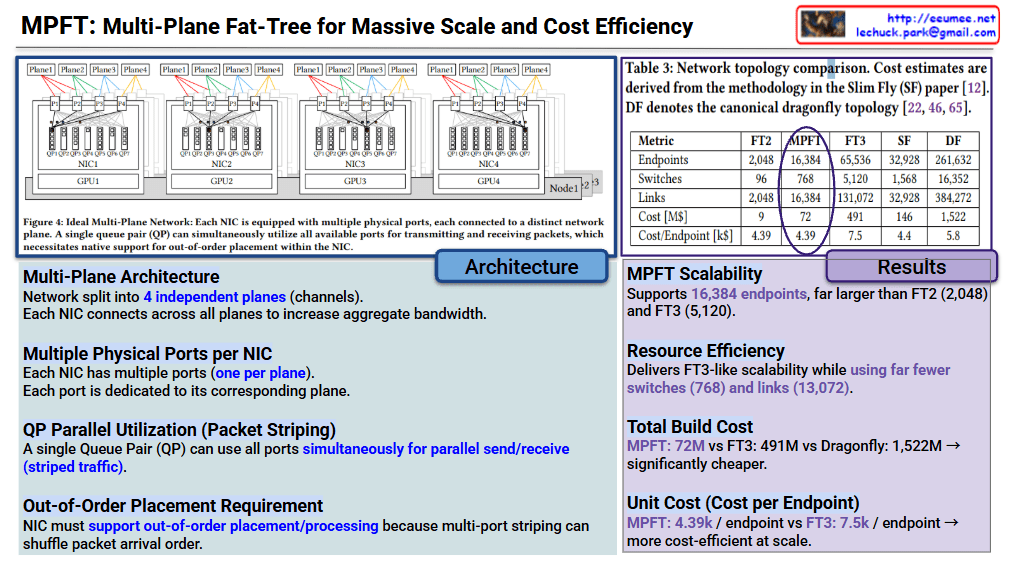
The core innovation of MPFT lies in parallelizing network traffic across multiple independent “planes” to maximize bandwidth and minimize hardware overhead.
The table compares MPFT against standard topologies like FT2/FT3 (Fat-Tree), SF (Slim Fly), and DF (Dragonfly).
| Metric | MPFT | FT3 | Dragonfly (DF) |
| Endpoints | 16,384 | 65,536 | 261,632 |
| Switches | 768 | 5,120 | 16,352 |
| Total Cost | $72M | $491M | $1,522M |
| Cost per Endpoint | $4.39k | $7.5k | $5.8k |
MPFT is presented as a “sweet spot” solution for AI/HPC clusters. It provides the high-speed performance of complex 3-tier networks but keeps the cost and hardware complexity closer to simpler 2-tier systems by using multi-port NICs and traffic striping.
#NetworkArchitecture #DataCenter #HighPerformanceComputing #GPU #AITraining #MultiPlaneFatTree #MPFT #NetworkingTech #ClusterComputing #CloudInfrastructure

This diagram outlines a comprehensive framework for optimizing an “AI Factory”—a modern data center dedicated to AI workloads. The core message is that optimizing AI performance and cost requires a holistic view that connects physical infrastructure realities directly to high-level business Service Level Agreements (SLAs).
Here is a breakdown of the three main pillars of this framework:
On the far left, we see the AI Factory itself. This represents the converged physical infrastructure required to run massive AI models (indicated by the neural network icons).
It emphasizes that the critical hardware components—GPUs (Compute), Networking, Power, and Cooling—cannot be managed in silos. They are marked as “ULTRA CONNECTED,” meaning the behavior of one directly impacts the others (e.g., intense GPU activity spikes power demand and generates immediate heat, requiring instant cooling response).
In the center, the diagram highlights the necessity of Ultra Data Quality. To optimize such a complex, interconnected system, standard logging isn’t enough. The telemetry data collected from the infrastructure must meet three critical criteria:
The right section is the most critical, showing the direct mapping between physical operational metrics (Usage+Performance) and business outcomes (Cost & SLA). It argues that physical stability directly dictates business success:
This diagram illustrates that optimizing an AI business isn’t just about better code or faster chips; it requires an end-to-end approach where the physical realities of power, cooling, and hardware are tightly integrated with data analytics to ensure performance promises (SLAs) are met cost-effectively.
#AIFactory #DataCenterOptimization #AIInfrastructure #GPUComputing #SLAmanagement #EnergyEfficiency #PUE #Operations #TechInnovation #ArtificialIntelligence


