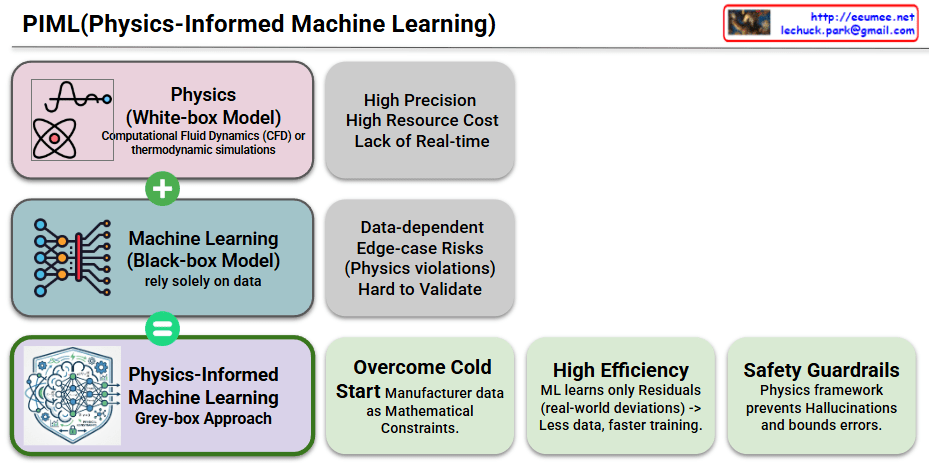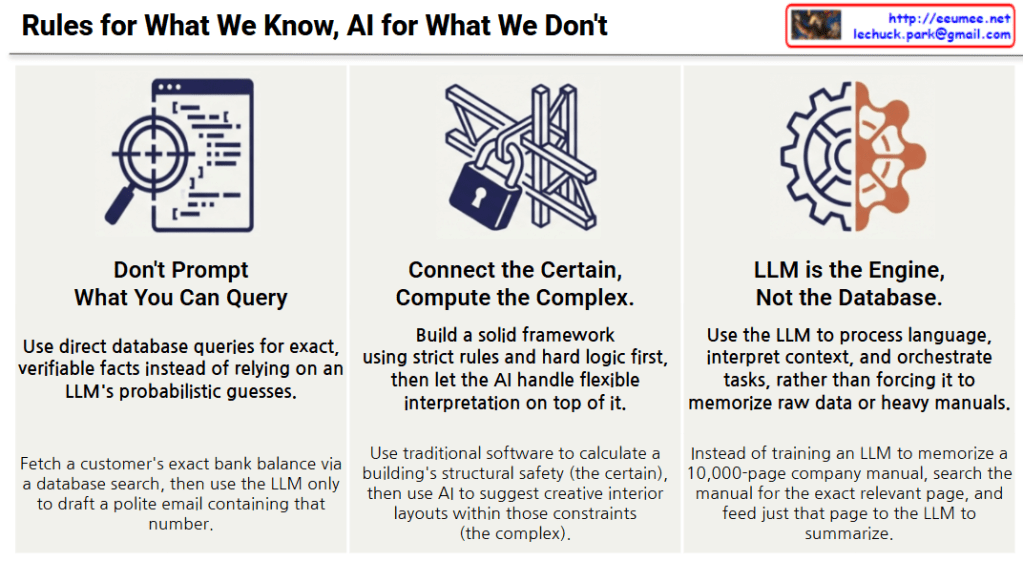
This image presents a practical guide on how to effectively integrate Artificial Intelligence, specifically Large Language Models (LLMs), into software systems. The overarching theme is “Rules for What We Know, AI for What We Don’t,” which emphasizes using reliable, traditional computing for hard facts and reserving AI for complex reasoning and interpretation.
1. Don’t Prompt What You Can Query
This principle warns against using AI to retrieve exact data. Because LLMs generate responses based on probabilities, they can sometimes guess incorrectly or hallucinate. If you need a verified fact—like a user’s bank balance—you should use a standard database search to fetch that exact number. Once you have the accurate data, you can then pass it to the AI to draft a natural, polite response.
2. Connect the Certain, Compute the Complex
This section suggests building a hybrid approach to problem-solving. You should establish a strict, rule-based foundation (the “certain”) using traditional logic, math, or physics. Once that solid framework is in place, you let the AI operate on top of it to handle creative or flexible tasks (the “complex”). For example, use traditional software to ensure a building is structurally safe, and then use AI to design creative interior layouts within those safe boundaries.
3. LLM is the Engine, Not the Database
This final point clarifies the true role of an LLM: it is a processor, not a storage drive. You shouldn’t try to force an AI to memorize massive amounts of raw data, like a 10,000-page company manual. Instead, use a search system to find the exact page you need, and then feed just that relevant text into the LLM. The AI acts as the “engine” to read, understand, and summarize that specific information for you.
Summary
To build reliable AI applications, rely on traditional databases and strict logic for factual retrieval and structural constraints. Use LLMs strictly as reasoning and processing engines to interpret context, draft text, and solve complex problems based on the hard facts you provide them.
#AIArchitecture #LLM #ArtificialIntelligence #SoftwareEngineering #DataScience #PromptEngineering #GenerativeAI