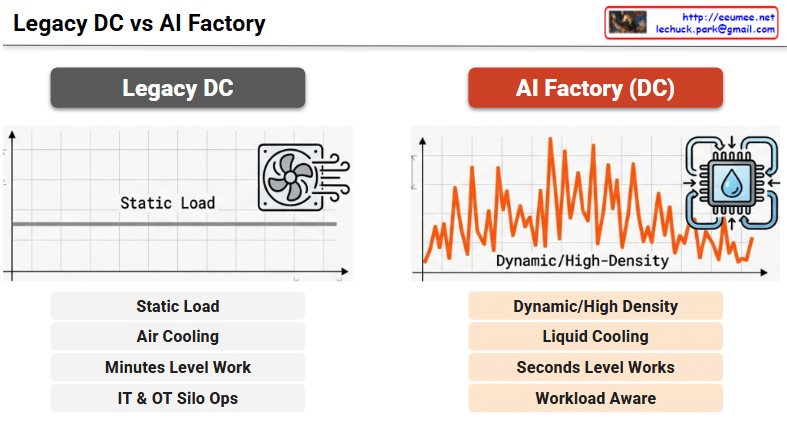
Static Load: The flat line on the graph indicates that power and compute demands are stable, continuous, and highly predictable.
Air Cooling: Traditional fan-based air cooling systems are sufficient to manage the heat generated by standard, lower-density server racks.
Minutes Level Work: System responses, resource provisioning, and facility adjustments generally occur on a scale of minutes.
IT & OT Silo Ops: Information Technology (servers, networking) and Operational Technology (power, cooling facilities) are managed independently in isolated silos, with no real-time data exchange.
2. AI Factory (DC)
Dynamic/High-Density: The volatile, jagged graph illustrates how AI workloads create extreme, rapid power spikes and demand highly dense computing resources.
Liquid Cooling: The immense heat output from high-performance AI chips necessitates advanced liquid cooling solutions (represented by the water drop and circulation arrows) to maintain thermal efficiency.
Seconds Level Works: The physical infrastructure must be highly agile, detecting and responding to sudden dynamic workload changes and thermal shifts within seconds.
Workload Aware: The facility dynamically adapts its cooling and power based on real-time AI computing needs. Establishing this requires robust “IT/OT Data Convergence” and the utilization of “High-Fidelity Data” as key components of a broader “Digitalization” strategy.
Summary
Legacy data centers are designed for predictable, static loads using traditional air cooling, with IT and facility operations (OT) isolated from one another.
AI Factories must handle highly volatile, high-density workloads, making liquid cooling and instantaneous, seconds-level infrastructure responses mandatory.
Transitioning to a true “Workload Aware” facility requires a strong “Digitalization” strategy centered around “IT/OT Data Convergence” and “High-Fidelity Data.”
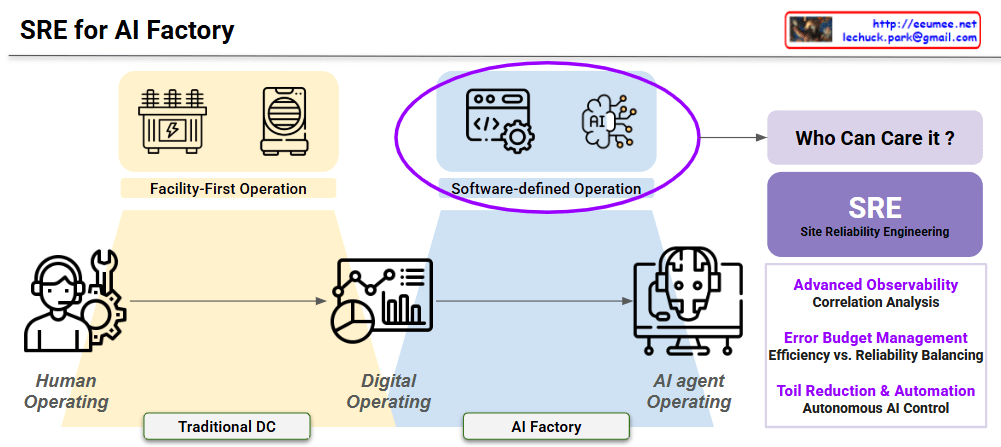
Human Operating (Traditional DC): Depicts the legacy stage where manual intervention and physical inspections are the primary means of management.
Digital Operating: A transitional phase represented by dashboards and data visualization, moving toward data-informed decision-making.
AI Agent Operating (AI Factory): The future state where autonomous AI agents (like your AIDA platform) manage complex infrastructures with minimal human oversight.
2. Shift in Core Methodology (Top Transition)
Facility-First Operation: Focuses on the physical health of hardware (Transformers, Cooling units) to ensure basic uptime.
Software-Defined Operation (Highlighted): The centerpiece of the transition. It treats infrastructure as code, using software logic and AI to control physical assets dynamically.
3. The Solution: SRE (Site Reliability Engineering)
The image identifies SRE as the definitive answer to the question “Who can care for it?” by applying three technical pillars:
Advanced Observability: Moving beyond binary alerts to deep Correlation Analysis of power and cooling data.
Error Budget Management: Quantitatively Balancing Efficiency (PUE) vs. Reliability to push performance without risking failure.
Toil Reduction & Automation: Achieving scalability through Autonomous AI Control, eliminating repetitive manual tasks.
3-Line Summary
Paradigm Shift: Evolution from hardware-centric “Facility-First” management to code-driven “Software-Defined Operation.”
The Role of SRE: Implementation of SRE principles is the essential bridge to managing the high complexity of AI Factories.
Operational Pillars: Success relies on Advanced Observability, Error Budgeting (PUE optimization), and Toil Reduction via AI automation.
End-to-End AI Factory Optimization: Bridging Infrastructure and Business Value
This diagram outlines a comprehensive framework for optimizing an “AI Factory”—a modern data center dedicated to AI workloads. The core message is that optimizing AI performance and cost requires a holistic view that connects physical infrastructure realities directly to high-level business Service Level Agreements (SLAs).
Here is a breakdown of the three main pillars of this framework:
1. The AI Factory (Infrastructure Foundation)
On the far left, we see the AI Factory itself. This represents the converged physical infrastructure required to run massive AI models (indicated by the neural network icons).
It emphasizes that the critical hardware components—GPUs (Compute), Networking, Power, and Cooling—cannot be managed in silos. They are marked as “ULTRA CONNECTED,” meaning the behavior of one directly impacts the others (e.g., intense GPU activity spikes power demand and generates immediate heat, requiring instant cooling response).
2. Ultra Data Quality (The Intelligence Layer)
In the center, the diagram highlights the necessity of Ultra Data Quality. To optimize such a complex, interconnected system, standard logging isn’t enough. The telemetry data collected from the infrastructure must meet three critical criteria:
Ultra Precision & Resolution: Capturing minute details of operations.
Ultra Time-Sync: The ability to perfectly synchronize timestamps across different hardware types (e.g., nanosecond-level GPU events vs. millisecond-level cooling events) to understand cause-and-effect relationships accurately.
3. Cost & SLA vs. Usage+Performance (The Value Realization)
The right section is the most critical, showing the direct mapping between physical operational metrics (Usage+Performance) and business outcomes (Cost & SLA). It argues that physical stability directly dictates business success:
TOKEN (Output/Revenue) ↔ Clock Consistency: To maintain a steady stream of AI output (tokens), the GPU clock speeds must remain consistent and stable without fluctuating.
FLOPS (Peak Compute Power) ↔ Zero Throttling Events: Achieving maximum floating-point operations per second requires eliminating “throttling”—performance downgrades caused by overheating or power constraints.
Watt (Operational Cost) ↔ Power Draw vs TDP: Managing operational expenses (electricity bills) requires optimizing the actual power draw relative to the hardware’s Thermal Design Power (TDP) limits.
PUE (Data Center Efficiency) ↔ Thermal Headroom: The overall Power Usage Effectiveness of the facility depends on optimizing “thermal headroom”—managing how close the cooling systems run to their limits without wasting energy.
This diagram illustrates that optimizing an AI business isn’t just about better code or faster chips; it requires an end-to-end approach where the physical realities of power, cooling, and hardware are tightly integrated with data analytics to ensure performance promises (SLAs) are met cost-effectively.
PUE Improvement: Power Usage Effectiveness (overall power efficiency metric)
Key Message
This diagram emphasizes that for successful AI implementation:
Technical Foundation: Both Data/Chips (Computing) and Power/Cooling (Infrastructure) are necessary
Tight Integration: These two axes are not separate but must be firmly connected like a chain and optimized simultaneously
Implementation Technologies: Specific advanced technologies for stability and optimization in each domain must provide support
The central link particularly visualizes the interdependent relationship where “increasing computing power requires strengthening energy and cooling in tandem, and computing performance cannot be realized without infrastructure support.”
Summary
AI systems require two inseparable pillars: Computing (Data/Chips) and Infrastructure (Power/Cooling), which must be tightly integrated and optimized together like links in a chain. Each pillar is supported by advanced technologies spanning from AI model optimization (FlashAttention, Quantization) to next-gen hardware (GB200, TPU) and sustainable infrastructure (SMR, Liquid Cooling, AI-driven optimization). The key insight is that scaling AI performance demands simultaneous advancement across all layers—more computing power is meaningless without proportional energy supply and cooling capacity.