Power Architecture Evolution: From Passive Load to Active Asset
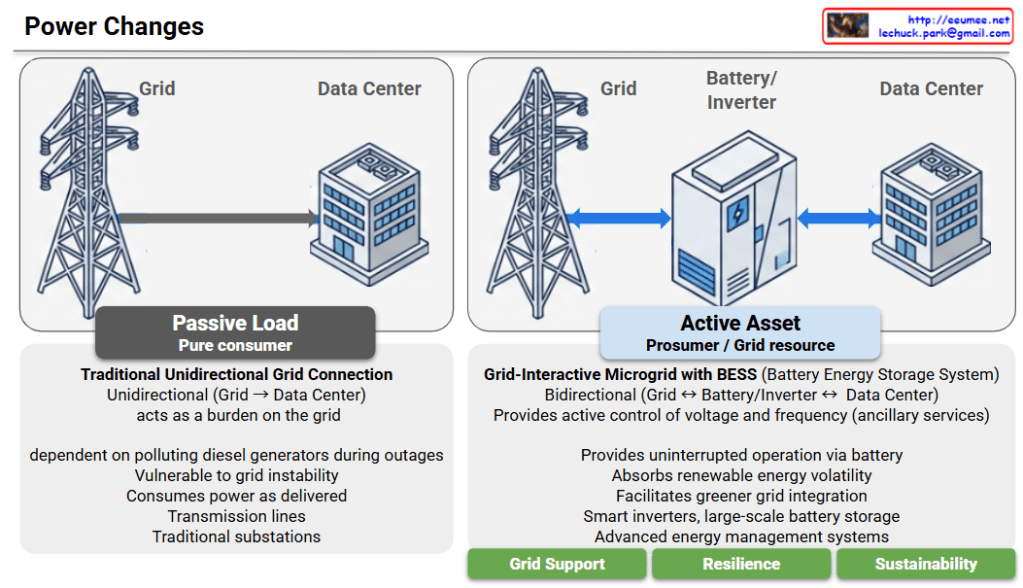
This diagram illustrates the critical evolution of data center power systems, highlighting the shift from a traditional “Passive Load” model to an “Active Asset” model. This transition is emerging as an essential power architecture and strategic direction for future AI Data Centers (AI DCs), which demand massive energy consumption and absolute operational stability.
1. AS-IS: Passive Load (Pure Consumer)
- Traditional Unidirectional Grid Connection: Power flows in only one direction (Grid -> Data Center).
- Grid Burden: The facility acts solely as a massive energy consumer, placing a heavy burden on the power grid.
- Vulnerability & Pollution: It is vulnerable to grid instability and relies heavily on polluting diesel generators during power outages.
- Infrastructure: It relies on traditional transmission lines and substations, consuming power exactly as it is delivered without any grid interaction.
2. TO-BE: Active Asset (Prosumer / Grid Resource)
- Grid-Interactive Microgrid with BESS: Integrates a Battery Energy Storage System (BESS) for intelligent and flexible power management.
- Bidirectional Flow: Power can flow both ways (Grid <-> Battery/Inverter <-> Data Center), allowing the facility to function as a “prosumer.”
- Grid Support (Ancillary Services): Actively provides control over voltage and frequency to help stabilize the broader power grid.
- Resilience & Sustainability: Ensures uninterrupted operation via large-scale battery storage, significantly reducing diesel dependency. It also absorbs the volatility of renewable energy, facilitating a greener grid integration.
- Key Technologies: Driven by smart inverters, large-scale batteries, and Advanced Energy Management Systems (EMS).
Conclusion: An Indispensable Power Direction for AI DCs
Rather than simply acting as facilities that drain massive amounts of electricity, modern data centers must evolve into grid-interactive assets. Given the exponential surge in power demands and the strict continuous operation requirements of AI workloads, adopting this “Active Asset” architecture with BESS and smart inverters is no longer just an eco-friendly alternative—it is an essential and inevitable power infrastructure direction for the successful deployment and scaling of AI Data Centers.
#AIDC #AIDataCenter #DataCenterInfrastructure #ESS #Inverter #GridInteractive
With Gemini