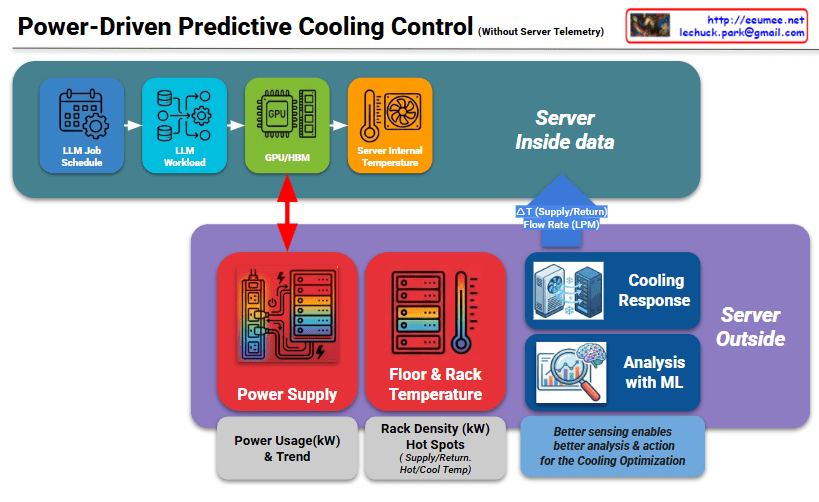
For a Co-location (Colo) service provider, the challenge is managing high-density AI workloads without having direct access to the customer’s proprietary server data or software stacks. This second image provides a specialized architecture designed to overcome this “data blindness” by using infrastructure-level metrics.
1. The Strategy: Managing the “Black Box”
In a co-location environment, the server internal data—such as LLM Job Schedules, GPU/HBM telemetry, and Internal Temperatures—is often restricted for security and privacy reasons. This creates a “Black Box” for the provider. The architecture shown here shifts the focus from the Server Inside to the Server Outside, where the provider has full control and visibility.
2. Power as the Primary Lead Indicator
Because the provider cannot see when an AI model starts training, they must rely on Power Supply telemetry as a proxy.
- The Power-Heat Correlation: As indicated by the red arrow, there is a near-instantaneous correlation between GPU activity and power draw ($kW$).
- Zero-Inference Monitoring: By monitoring Power Usage & Trends at the PDU (Power Distribution Unit) level, the provider can detect a workload spike the moment it happens, often several minutes before the heat actually migrates to the rack-level sensors.
3. Bridging the Gap with ML Analysis
Since the provider is missing the “More Proactive” software-level data, the Analysis with ML component becomes even more critical.
- Predictive Modeling: The ML engine analyzes power trends to forecast the thermal discharge. It learns the specific “power signature” of AI workloads, allowing it to initiate a Cooling Response (adjusting Flow Rate in LPM and $\Delta T$) before the ambient temperature rises.
- Optimization without Intrusion: This allows the provider to maintain a strict SLA (Service Level Agreement) and optimize PUE (Power Usage Effectiveness) without requiring the tenant to install agents or share sensitive job telemetry.
Comparison for Co-location Providers
| Feature | Ideal Model (Image 1) | Practical Colo Model (Image 2) |
| Visibility | Full-stack (Software to Hardware) | Infrastructure-only (Power & Air/Liquid) |
| Primary Metric | LLM Job Queue / GPU Temp | Power Trend ($kW$) / Rack Density |
| Tenant Privacy | Low (Requires data sharing) | High (Non-intrusive) |
| Control Precision | Extremely High | High (Dependent on Power Sampling Rate) |
Summary
- For Co-location providers, this architecture solves the lack of server-side visibility by using Power Usage ($kW$) as a real-time proxy for heat generation.
- By monitoring Power Trends at the infrastructure level, the system can predict thermal loads and trigger Cooling Responses before temperature sensors even react.
- This ML-driven approach enables high-efficiency cooling and PUE optimization while respecting the strict data privacy and security boundaries of multi-tenant AI data centers.
Hashtags
#Colocation #DataCenterManagement #PredictiveCooling #AICooling #InfrastructureOptimization #PUE #LiquidCooling #MultiTenantSecurity
With Gemini