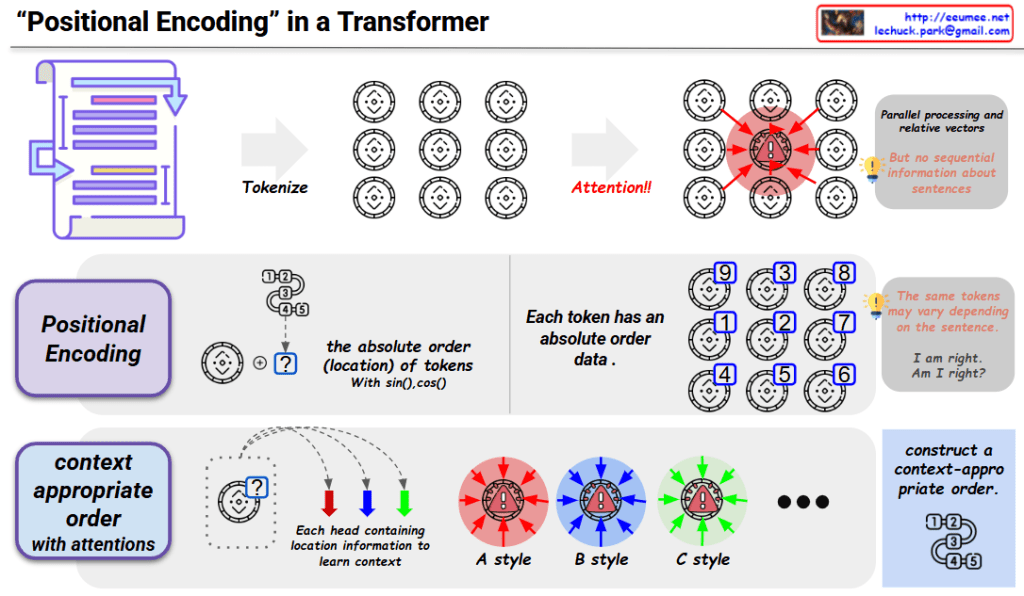
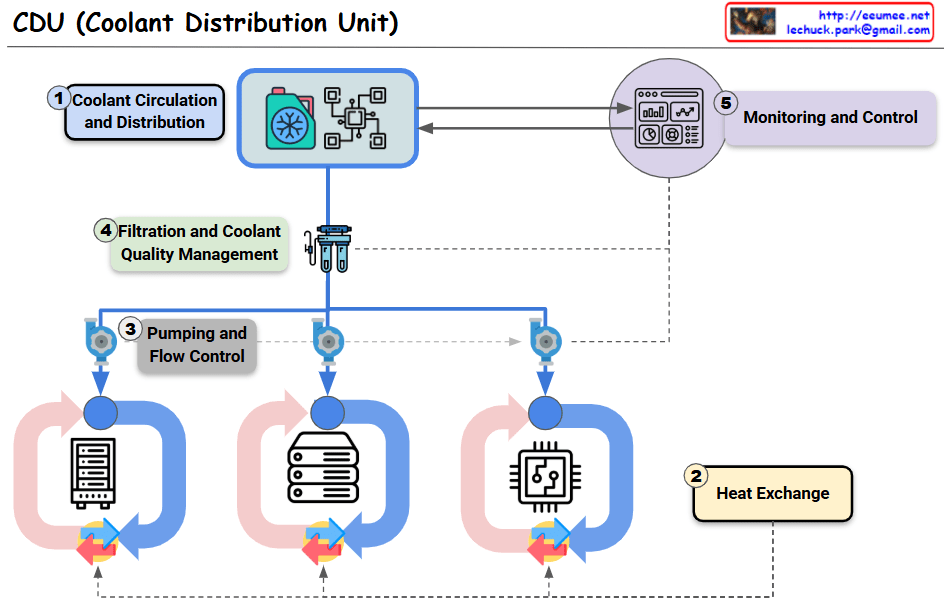
Image Overview
This dashboard displays the cascading resource changes that occur when GPU workload increases in an AI data center server room monitoring system.
Key Change Sequence (Estimated Values)
- GPU Load Increase: 30% → 90% (AI computation tasks initiated)
- Power Consumption Rise: 0.42kW → 1.26kW (3x increase)
- Temperature Delta Rise: 7°C → 17°C (increased heat generation)
- Cooling System Response:
- Water flow rate: 200 LPM → 600 LPM (3x increase)
- Fan speed: 600 RPM → 1200 RPM (2x increase)
Operational Prediction Implications
- Operating Costs: Approximately 3x increase from baseline expected
- Spare Capacity: 40% cooling system capacity remaining
- Expansion Capability: Current setup can accommodate additional 67% GPU load
This AI data center monitoring dashboard illustrates the cascading resource changes when GPU workload increases from 30% to 90%, triggering proportional increases in power consumption (3x), cooling flow rate (3x), and fan speed (2x). The system demonstrates predictable operational scaling patterns, with current cooling capacity showing 40% remaining headroom for additional GPU load expansion. Note: All values are estimated figures for demonstration purposes.
Note: All numerical values are estimated figures for demonstration purposes and do not represent actual measured data.
With Claude